アンサンブル学習技術:Pythonでのランダムフォレストを使った手順解説
Pythonでのランダムフォレストを使ったアンサンブル学習の手順解説
機械学習モデルは、複数の業界で意思決定の重要な要素となっていますが、ノイズや多様なデータセットの処理にはしばしば困難が伴います。そこでアンサンブル学習が登場します。
本記事では、アンサンブル学習を解説し、強力なランダムフォレストアルゴリズムについて紹介します。データサイエンティストがツールキットを磨くための情報を求めている場合や、頑健な機械学習モデルの構築に関する実践的な洞察を求めている開発者の場合、この記事はどなたにも役立つものです!
この記事の終わりまでに、アンサンブル学習とPythonにおけるランダムフォレストの動作について、詳しい知識を得ることができます。経験豊富なデータサイエンティストであるか、単に機械学習の能力を拡張したいと思っているかにかかわらず、この冒険に参加して機械学習の専門知識を深めましょう!
- 大規模言語モデルは安全性を自己評価できるのか?RAINに会ってください:ファインチューニングなしでAIのアライメントと防御を変革する革新的な推論方法
- 5つのステップでScikit-learnを始める
- 「人物再識別入門」
1. アンサンブル学習とは何ですか?
アンサンブル学習は、複数の弱いモデルの予測を組み合わせ、より強力な予測を得る機械学習アプローチです。アンサンブル学習の背後にあるコンセプトは、各モデルの予測力を活用して、単一のモデルからのバイアスとエラーを減らすことです。
より具体的な例を挙げるために、生活の例を考えてみましょう。何らかの動物を見たことがあり、その動物がどの種に属するか分かりません。一人の専門家に尋ねる代わりに、十人の専門家に尋ね、そのうちの多数派の意見を採用します。これが「ハード投票」と呼ばれるものです。
「ハード投票」は、各分類器のクラスの予測を考慮に入れ、入力を特定のクラスへの最大得票数に基づいて分類するものです。一方、「ソフト投票」は、各分類器の各クラスの確率予測を考慮に入れ、各クラスの平均確率(分類器の確率の平均値)に基づいて入力を最大確率のクラスに分類するものです。
2. アンサンブル学習を使用するタイミング
アンサンブル学習は、モデルの性能を改善するために常に使用されます。これには、分類の正確性の向上や回帰モデルの平均絶対誤差の減少が含まれます。また、アンサンブル学習は常により安定したモデルを生成します。アンサンブル学習は、モデル同士が相関していない場合に最も効果を発揮します。その場合、各モデルはユニークな情報を学習し、全体のパフォーマンスの向上に取り組むことができます。
3. アンサンブル学習の戦略
アンサンブル学習は様々な方法で適用することができますが、実践においては、次の3つの戦略が簡単に実装・使用できるため、非常に人気があります。これらの戦略は次の通りです:
- バギング(Bagging):バギングは、ブートストラップ集約とも呼ばれ、データセットのランダムサンプルを使用してモデルを訓練するアンサンブル学習の戦略です。
- スタッキング(Stacking):スタッキングは、データに対して複数のモデルを訓練し、それらのモデルを組み合わせるモデルを訓練するアンサンブル学習の戦略です。
- ブースティング(Boosting):ブースティングは、誤分類されたデータを選択してモデルを訓練するアンサンブル学習の手法です。
これらの戦略について詳しく見ていき、Pythonを使用してこれらのモデルをデータセットに訓練する方法を見ていきましょう。
4. バギングアンサンブル学習
バギングは、データのランダムサンプルを取り、学習アルゴリズムと平均値を使用してバギング確率を見つけます。これはブートストラップ集約とも呼ばれ、複数のモデルからの結果を集約して広範な結果を得ます。
この手法は次の手順で行われます:
- 元のデータセットを置換を伴う複数のサブセットに分割する。
- それぞれのサブセットに対して基本モデルを開発する。
- 最終的な予測を得るため、すべてのモデルを同時に実行し、すべての予測を通過させる。
Scikit-learnは、BaggingClassifierとBaggingRegressorの両方を実装する機能を提供しています。BaggingMetaEstimatorは、元のデータセットのランダムなサブセットを特定し、各基本モデルに適合させ、投票または平均化を介して個々の基本モデルの予測を集約し、投票または平均化を使用して集約予測に個々の基本モデルの予測を集約します。この方法により、構築プロセスがランダム化されることで分散を減らすことができます。
Scikit-learnを使用してバギングエスティメータを使った例を見てみましょう:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
バギング分類器はいくつかのパラメータを考慮します:
- base_estimator:バギング手法で使用される基本モデル。ここでは決定木分類器を使用します。
- n_estimators:バギング手法で使用する推定器の数。
- max_samples:各基本推定器のために学習セットから抽出されるサンプルの数。
- max_features:各基本推定器の学習に使用される特徴量の数。
次に、この分類器を学習セットに適合させ、スコアを計算します。
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
回帰タスクに対しても同じことができますが、異なるのは回帰推定器を使用することです。
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)
5. スタッキングアンサンブル学習
スタッキングは、複数の推定器を組み合わせてバイアスを最小化し、正確な予測を行うための技術です。各推定器の予測は組み合わせられ、交差検証を通じてトレーニングされた究極の予測メタモデルに供給されます。スタッキングは分類問題と回帰問題の両方に適用することができます。
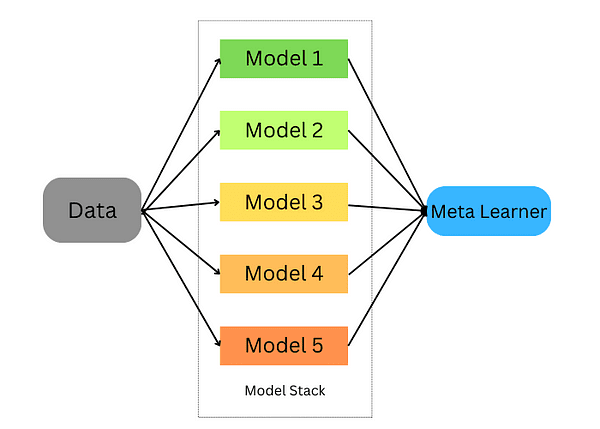
スタッキングは以下の手順で行われます:
- データを訓練セットと検証セットに分割する
- 訓練セットをK個のフォールドに分割する
- K-1個のフォールドでベースモデルを訓練し、k番目のフォールドで予測を行う
- 各フォールドに対して予測が得られるまで繰り返す
- ベースモデルを全体の訓練セットに適合させる
- モデルを使用してテストセットで予測を行う
- 他のベースモデルに対してステップ3〜6を繰り返す
- テストセットからの予測を新しいモデル(メタモデル)の特徴量として使用する
- メタモデルを使用してテストセットで最終的な予測を行う
以下の例では、RandomForestClassifierとGradientBoostingClassifierの2つのベース分類器とLogisticRegressionのメタクラス分類器を作成し、K-fold交差検証を使用してこれらの分類器から訓練データ(アヤメデータセット)の予測を入力特徴量として使用します。
ベース分類器からテストデータセットへの予測を入力特徴量として使用し、スタックされたアンサンブルの対応する予測との正確性を評価します。
# データセットの読み込み
data = load_iris()
X, y = data.data, data.target
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ベース分類器の定義
base_classifiers = [
RandomForestClassifier(n_estimators=100, random_state=42),
GradientBoostingClassifier(n_estimators=100, random_state=42)
]
# メタクラス分類器の定義
meta_classifier = LogisticRegression()
# ベース分類器の予測を保持する配列を作成
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))
# K-fold交差検証を用いてスタッキングを実行
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train):
train_fold, val_fold = X_train[train_index], X_train[val_index]
train_target, val_target = y_train[train_index], y_train[val_index]
for i, clf in enumerate(base_classifiers):
cloned_clf = clone(clf)
cloned_clf.fit(train_fold, train_target)
base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)
# メタクラス分類器をベース分類器の予測で学習
meta_classifier.fit(base_classifier_predictions, y_train)
# スタックされたアンサンブルを使用して予測を行う
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):
stacked_predictions[:, i] = clf.predict(X_test)
# メタクラス分類器を使用して最終的な予測を行う
final_predictions = meta_classifier.predict(stacked_predictions)
# スタックされたアンサンブルのパフォーマンスを評価する
accuracy = accuracy_score(y_test, final_predictions)
print(f"スタックされたアンサンブルの正解率:{accuracy:.2f}")
6. ブースティングアンサンブル学習
ブースティングは、弱学習器を強学習器に変換することで、バイアスと分散を削減する機械学習のアンサンブル技術です。これらの弱学習器はデータセットに順次適用され、まず最初に初期モデルが作成され、トレーニングセットに適合させられます。最初のモデルのエラーが特定されると、それを修正するために別のモデルが設計されます。
ブースティングアンサンブル学習技術には人気のあるアルゴリズムと実装があります。最も有名なものを探ってみましょう。
6.1. AdaBoost
AdaBoostは効果的なアンサンブル学習技術であり、弱学習器を順次的にトレーニングに利用します。各反復では、不正確な予測を優先し、正しく予測されたインスタンスに割り当てられる重みを減らします。挑戦的な観測に対する戦略的な重点は、AdaBoostが時間とともにますます正確になるように促します。最終的な予測は、弱学習器の多数決または重み付き合計によって決定されます。
AdaBoostは、回帰と分類の両方のタスクに適した多目的なアルゴリズムですが、ここではScikit-learnを使用した分類問題への適用に焦点を当てています。以下の例では、分類タスクにおいてAdaBoostを使用する方法を見てみましょう:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
この例では、scikit-learnのAdaBoostClassifierを使用し、n_estimatorsを100に設定しました。デフォルトの学習器は決定木であり、変更することができます。また、決定木のパラメータも調整できます。
2. eXtreme Gradient Boosting (XGBoost)
eXtreme Gradient Boosting、またはXGBoostとしてよく知られているものは、ブースティングアンサンブル学習の最高の実装の一つです。並列計算を行うため、単一のコンピュータ上で非常に最適化された動作ができます。XGBoostは、機械学習コミュニティによって開発されたxgboostパッケージを介して使用できます。
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
3. LightGBM
LightGBMは、木ベースのアルゴリズムを使用するブースティングアルゴリズムの一つです。しかし、他の木ベースのアルゴリズムとは異なり、葉ノードごとの木の成長を行うため、収束が早くなります。
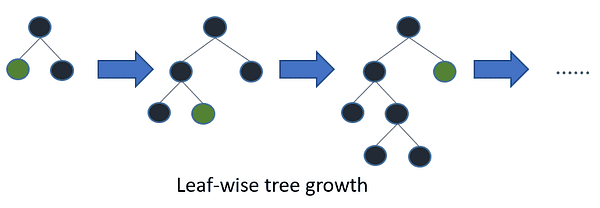
以下の例では、LightGBMを2値分類問題に適用します:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
アンサンブル学習とランダムフォレストは、機械学習の実践者やデータサイエンティストによって常に使用される強力な機械学習モデルです。この記事では、それらの基本的な直感、使用するタイミング、そして最も人気のあるアルゴリズムとPythonでの使用方法について説明しました。
参考文献
- アンサンブル学習アルゴリズムへの優しいイントロダクション
- アンサンブル学習の包括的ガイド:あなたは実際に何を知る必要がありますか
- アンサンブル学習の包括的ガイド(Pythonコード付き)
Youssef Rafaatは、コンピュータビジョンの研究者兼データサイエンティストです。彼の研究は、ヘルスケアアプリケーション向けのリアルタイムコンピュータビジョンアルゴリズムの開発に焦点を当てています。また、彼はマーケティング、ファイナンス、およびヘルスケアの分野で3年以上データサイエンティストとして働いてきました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





