「Pythia 詳細な研究のための16個のLLMスイート」
Pythia 16 LLM Suites for detailed research

今日、大規模な言語モデルとLLMパワードのChatGPTやGPT-4のようなチャットボットは、私たちの日常生活にうまく統合されています。
しかし、デコーダーのみの自己回帰トランスフォーマーモデルは、LLMアプリケーションが主流になる前から、生成型NLPアプリケーションに広く使用されてきました。トレーニング中にこれらのモデルがどのように進化し、スケールアップするにつれてパフォーマンスがどのように変化するかを理解することは役に立つかもしれません。
Eleuther AIによるプロジェクトであるPythiaは、研究、分析、およびさらなる研究のための再現性を提供する16の大規模言語モデルのスイートです。この記事はPythiaの紹介です。
- 「新しいAI研究が、PanGu-Coder2モデルとRRTFフレームワークを提案し、コード生成のための事前学習済み大規模言語モデルを効果的に向上させる」というものです
- 「AIと脳インプラントにより、麻痺した男性の運動と感覚が回復する」
- UCバークレーの研究者が、Neural Radiance Field(NeRF)の開発に利用できるPythonフレームワーク「Nerfstudio」を紹介しました
Pythiaスイートは何を提供していますか?
前述のように、Pythiaは、デコーダーのみの自己回帰トランスフォーマーモデルである16の大規模言語モデルのスイートです。これらのモデルは公開されているデータセットでトレーニングされており、サイズは70Mから12Bのパラメーターまでさまざまです。
- すべてのモデルは、同じデータを同じ順序でトレーニングされています。これにより、トレーニングプロセスの再現性が容易になります。トレーニングパイプラインを再現するだけでなく、言語モデルを分析し、詳細に研究することもできます。
- さらに、16の言語モデルごとに、トレーニングデータローダーと154以上のモデルチェックポイントのダウンロード機能も提供されています。
トレーニングデータとトレーニングプロセス
では、Pythia LLMスイートの詳細について見ていきましょう。
トレーニングデータセット
Pythia LLMスイートは、次のデータセットでトレーニングされました:
- 300BトークンのPileデータセット
- 207Bトークンの重複排除Pileデータセット
最小のモデルと最大のモデルはそれぞれ70Mと12Bのパラメーターを持ち、他のモデルのサイズには160M、410M、1B、1.4B、2.8B、6.9Bが含まれます。
これらのモデルのそれぞれは、Pileと重複したPileの両方のデータセットでトレーニングされ、合計16のモデルが生成されました。以下の表は、モデルのサイズと一部のハイパーパラメーターを示しています。
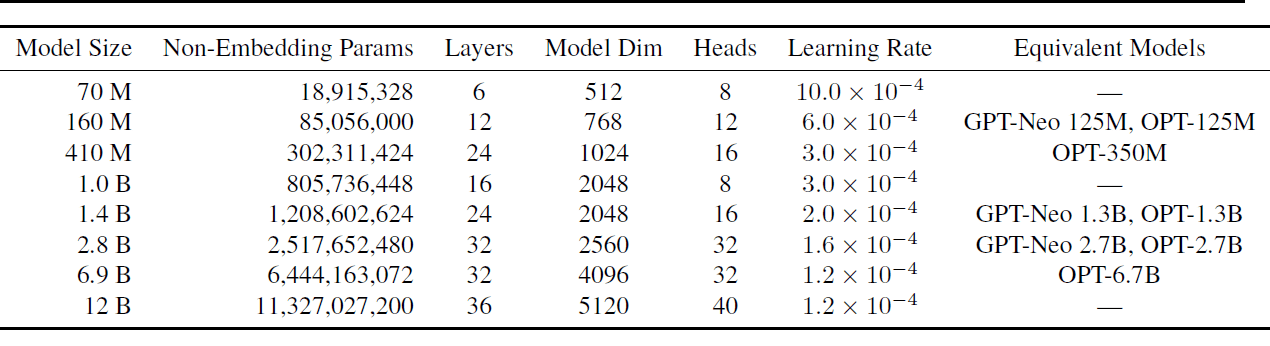
使用されたハイパーパラメーターの詳細については、「Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling」を参照してください。
トレーニングプロセス
ここでは、アーキテクチャとトレーニングプロセスの概要を説明します:
- すべてのモデルには完全な密なレイヤーがあり、フラッシュアテンションが使用されます。
- より解釈しやすくするために、結合されていない埋め込み行列が使用されます。
- バッチサイズは1024で、シーケンスの長さは2048です。この大きなバッチサイズは、ウォールクロックのトレーニング時間を大幅に短縮します。
- トレーニングプロセスでは、データとテンソルの並列処理などの最適化技術も利用されます。
トレーニングプロセスには、Eleuther AIが開発したGPT-Neo-Xライブラリ(DeepSpeedライブラリの機能を含む)が使用されます。
モデルチェックポイント
各モデルには154のチェックポイントがあります。1000イテレーションごとに1つのチェックポイントがあります。さらに、トレーニングプロセスの初期段階でログ間隔でチェックポイントが存在します:1、2、4、8、16、32、64、128、256、および512。
Pythiaは他の言語モデルと比較してどうですか?
Pythia LLMスイートは、OpenAIのLAMBADAバリアントを含む利用可能な言語モデリングベンチマークに対して評価されました。その結果、PythiaのパフォーマンスはOPTおよびBLOOM言語モデルと比較可能であることがわかりました。
利点と制限
Pythia LLMスイートの主な利点は再現性です。データセットは一般公開されており、事前にトークン化されたデータローダーと154のモデルチェックポイントも一般公開されています。ハイパーパラメータの完全なリストも公開されています。これにより、モデルのトレーニングと分析の再現がより簡単になります。
[1]では、著者たちは多言語のテキストコーパスではなく、英語の言語データセットを選択した理由を説明しています。しかし、多言語の大規模言語モデルの再現可能なトレーニングパイプラインは役立つ場合があります。特に、多言語の大規模言語モデルのダイナミクスの研究と研究を促進するために。
ケーススタディの概要
この研究では、Pythiaスイートの大規模言語モデルのトレーニングプロセスの再現性を活用した興味深いケーススタディも紹介されています。
ジェンダーバイアス
すべての大規模言語モデルはバイアスと誤情報の影響を受けやすいです。この研究では、固定割合の代名詞を特定の性別のものにすることで、ジェンダーバイアスを軽減することに焦点を当てています。この事前トレーニングも再現可能です。
記憶
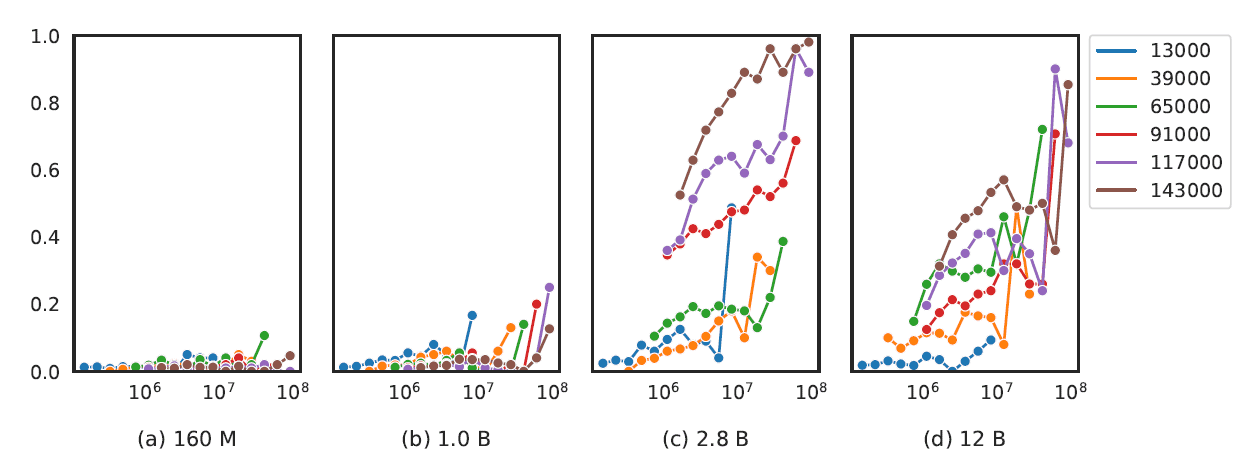
大規模言語モデルの記憶も広く研究されている領域です。シーケンスの記憶はポアソン点プロセスとしてモデル化されます。この研究では、特定のシーケンスの位置がトレーニングデータセット内での記憶に影響を与えるかどうかを理解することを目指しています。その結果、位置は記憶に影響を与えないことが観察されました。
事前トレーニングの用語の頻度の影響
2.8Bパラメータ以上の言語モデルでは、事前トレーニングコーパス内のタスク固有の用語の出現が、質問応答などのタスクのパフォーマンスを向上させることがわかりました。
モデルのサイズと、算術や数理推論などのより複雑なタスクのパフォーマンスとの間にも相関関係があります。
まとめと次のステップ
議論の重要なポイントをまとめましょう。
- Eleuther AIのPythiaは、一般公開されているPileデータセットと重複排除されたPileデータセットでトレーニングされた16のLLMスイートです。
- LLMのサイズは70Mから12Bパラメータの範囲です。
- トレーニングデータとモデルのチェックポイントはオープンソースであり、正確なトレーニングデータローダーを再構成することが可能です。そのため、LLMスイートは大規模言語モデルのトレーニングダイナミクスをより理解するのに役立ちます。
次のステップとして、Hugging Face HubでPythiaスイートのモデルとモデルのチェックポイントを探索してみることができます。
参考文献
[1] Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, arXiv, 2023 Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。彼女の関心と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、コーヒーが好きです!現在、彼女はチュートリアル、ハウツーガイド、意見記事などを執筆することで、開発者コミュニティと彼女の知識を共有するための学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AIを使用してAI画像の改ざんを防ぐ
- 「NYUとMeta AIの研究者は、ユーザーと展開されたモデルの間の自然な対話から学習し、追加の注釈なしで社会的な対話エージェントの改善を研究しています」
- 中国からの新しいAI研究が提案するSHIP:既存のファインチューニング手法を改善するためのプラグアンドプレイの生成AIアプローチ
- ETHチューリッヒの研究者たちは、LMQLという言語モデルとの相互作用のためのプログラミング言語を紹介しました
- 「Google DeepMindと東京大学の研究者が、WebAgentを紹介:自然言語の指示に従って実際のウェブサイト上のタスクを完了できるLLM-Drivenエージェント」
- 「研究者がChatGPTを破った方法と、将来のAI開発に与える可能性」
- 「KAISTの研究者がFaceCLIPNeRFを紹介:変形可能なNeRFを使用した3D顔のテキスト駆動型操作パイプライン」






