「慢性腎臓病の予測:新しい視点」
Prediction of Chronic Kidney Disease New Perspectives
SHAPを利用して、医学文献と一致する解釈可能なモデルを構築する
はじめに
腎臓は、血液中の廃物、毒素、余分な液体を取り除くために一生懸命働いており、その正常な機能は健康にとって重要です。慢性腎臓病(CKD)は、腎臓が血液を適切にろ過できない状態であり、長期的には血液中の液体や廃物が蓄積し、腎不全を引き起こす可能性があります。 [1] CKDは、世界の人口の10%以上に影響を与え、2040年までに世界で最も生命年を減らす要因の第5位になると予測されています。 [2]
この記事では、私の目的は、患者のCKDの発生を予測する最も正確なモデルを構築することではありませんでした。代わりに、標準的な機械学習アルゴリズムを使用して開発された最良のモデルが、医学文献に基づいてもっとも意味のあるモデルであるかどうかを確認することでした。私はSHAP(SHapley Additive exPlanations)の原則を使用し、MLモデルの出力を説明するゲーム理論的なアプローチを取りました。
医学文献は何を言っているのか?
医学文献は、CKDの発症と進行をいくつかの主要な症状と関連付けています。
- 糖尿病と高血圧:糖尿病と高血圧は、CKDと関連する最も重要なリスク要因の2つです。2011年から2014年にかけて米国で実施された研究では、CKD(ステージ3-4)の有病率は、糖尿病患者で24.5%、糖尿病予備軍で14.3%、非糖尿病患者で4.9%であることがわかりました。同じ研究では、高血圧患者ではCKDの有病率が35.8%、予高血圧者では14.4%、非高血圧者では10.2%であることが観察されました。 [2]
- ヘモグロビンと赤血球レベルの低下:腎臓はエリスロポエチン(EPO)と呼ばれるホルモンを生成し、赤血球の生成に役立ちます。CKDでは、腎臓が十分なEPOを生成できず、貧血、つまり血液中の赤血球およびヘモグロビンレベルの低下が生じます。 [3]
- 血清(血液)クレアチニンの増加:クレアチニンは通常の筋肉とタンパク質の分解の副産物であり、余分なクレアチニンは腎臓を介して血液から除去されます。CKDでは、腎臓が余分なクレアチニンを効果的に除去できず、血液中のクレアチニンレベルが高くなります。 [4]
- 尿比重の低下:尿の比重は、腎臓が尿をどれだけ濃縮できるかを示す指標です。CKDの患者は、腎臓が尿を効果的に濃縮できないため、尿比重が低下します。 [5]
- 血尿とアルブミン尿:血尿とアルブミン尿は、尿中に赤血球とアルブミンが存在することを示します。通常、腎臓のフィルターは血液やアルブミンが尿に入るのを防ぎます。しかし、これらのフィルターへの障害は、血液(または赤血球)とアルブミンが尿に入る原因となります。 [6][7]
データセット
この記事で使用されているデータセットは、Kaggleで利用可能な「慢性腎臓病」データセットであり、元々はUCIのMLリポジトリによって提供されました。これには、24の特徴量と1つのバイナリの目標変数(CKDのなし= 0、CKDのあり= 1)が含まれています。特徴の詳細な説明はこちらで確認できます。
データの前処理
CKDデータセットには、さらなる分析の前に補完する必要のある欠損値が多くありました。このプロットは、その列の欠損値を示す黄色い線で欠損データの視覚的な表現を示しています。
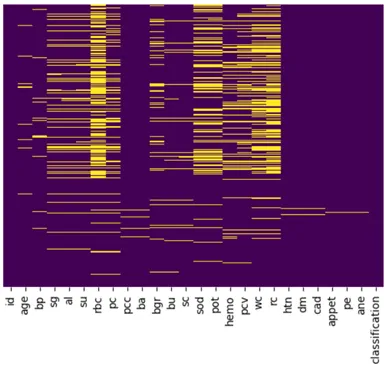
欠損値は以下の方法で補完されました:
- 数値特徴量の場合、欠損値は中央値を使用して補完されました。平均値は外れ値に敏感ですが、中央値はそうではありません。これらの列には外れ値が存在するため、中央値が中心値のより良い指標です。
- カテゴリ特徴量の「rbc」と「pc」は、それぞれデータの38%と16.25%が欠損していました。これは大量の欠損データですので、欠損値は「unknown」として補完されました。ここでモードを使用すると、同じカテゴリに大量の観測値を分類するのは少しリスキーです。
- その他のカテゴリ特徴量は、データの欠損率が1%以下でした。したがって、欠損値はそれぞれのモードを使用して補完されました。
モデルの構築とSHAPを使用した解釈のチェック
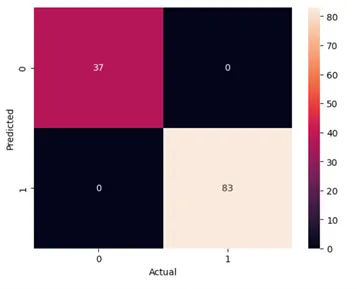
欠損値を補完した後、データはトレーニングセットとテストセットに分割され、単純なランダムフォレスト分類モデルが実行されました。テストの正解率は100%であり、つまり、モデルは以前に見たことのない患者を100%の確率で正しく分類することができました。以下に混同行列を示します。
今ではもちろん優れた分類モデルを持っています。しかし、解釈性に興味がある場合、つまり、各特徴が予測にどのように肯定的または否定的に寄与するかを知りたい場合、どの特徴が予測に最も重要であるかを知りたい場合はどうでしょうか?結果は臨床的な所見と一致していますか?これらの質問にSHAPが答えるのに役立ちます。
SHAPは、ゲーム理論に基づく数学的なアプローチであり、予測を説明するために任意のMLモデルの各特徴の貢献を計算することができます。これにより、予測に寄与する最も重要な特徴と、それらが目的変数にどの方向で影響を与えるかを特定するのに役立ちます。[8] SHAP説明子がテストデータに適合し、以下に示すようなグローバル特徴の重要性プロットが生成されました。
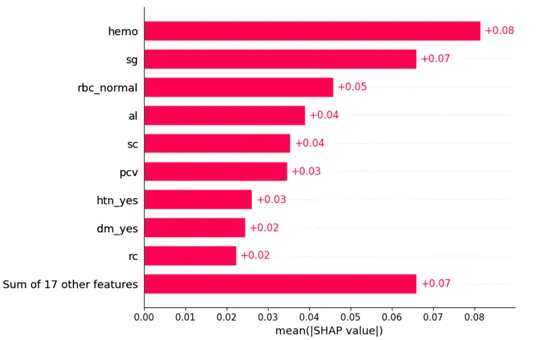
予測に寄与するトップ3の特徴は、ヘモグロビンレベル(「hemo」)、尿の比重(「sg」)、および尿中の赤血球の存在(「rbc_normal」)です。特徴の重要性は、与えられたすべてのサンプルに対するその特徴の絶対SHAP値の平均を取ることによって計算されるため、プロットは重要性の順序の情報のみを提供し、影響の方向を提供しません。より詳細なプロットを作成して、これらの目的を両方にまとめましょう。
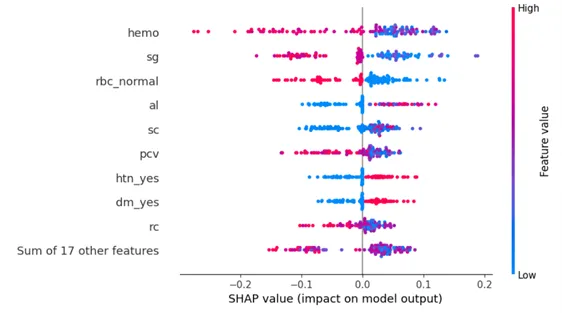
このビースワームプロットは、データセットのトップ特徴がモデルの予測にどのように影響を与えるかを示す素晴らしい方法です。ピンクの点は、CKDを予測した患者を示し、青の点は、CKDを予測しなかった患者を示します。予測のトップ特徴を知ったので、臨床的な所見と一致しているかどうかを見てみましょう。
- 糖尿病(「dm_yes」)と高血圧(「htn_yes」)の存在は、CKDの存在と関連しています。これは臨床的な所見と一致していますが、CKDと関連する主要なリスク要因であるため、グローバルな重要性の観点ではもう少し上位になることが期待されます。
- ヘモグロビンレベル(「hemo」)の低下、患者の血液中の赤血球の体積パーセンテージ(「pcv」)、および赤血球数の低下(「rc」)は、CKDと関連しています。これは臨床的な所見と一致しており、CKDを患っている患者は十分なレベルの赤血球を生成できないためです。
- 尿の比重の低下(「sg」)は、CKDと関連しています。これは臨床的には腎臓が尿を濃縮する能力を失うためです。
- 尿中のアルブミン(「al」)および血清クレアチニン(「sc」)レベルの上昇は、CKDと関連しています。これは臨床的な所見と一致しており、腎臓が血液を効果的にろ過できなくなるためです。
- 尿中の赤血球または異常な尿(「rbc_normal」;値=1は正常な尿で赤血球が含まれていないことを示し、値=0は赤血球が含まれている可能性がある異常な尿を示します)は、CKDと関連しています。これは臨床的な所見と一致しており、血尿はCKDを患っている患者でより一般的に見られます。
要約すると、予測に対する上位の特徴とその影響の方向は、医学文献と一致しています。
結論
この記事では、次の2つの主なポイントがあります:
- 医学文献は、CKDの発展と進行を同じ上位の特徴と関連付けています。MLモデルは、患者がCKDを予測されるかどうかを分類するために使用する特徴と一致しています。
- これらの上位の特徴が目標変数に影響を与える方向は、臨床の知見を支持しており、モデルがCKDを予測するだけでなく、医学的な意味を持ち、結果が完全に解釈可能であることを示唆しています。
この研究の可能な制限の一つは、サンプルサイズの小ささです。より多くのデータが利用可能になると、モデルを高い精度で実行し続けるかどうかをより大規模な患者グループでテストする必要があります。また、特徴の重要度の順序がより大きな患者群に対して変化するかどうかも興味深いです。
医療の分野では、最も正確なモデルが常に最も意義深いモデルではありません。この研究では、SHAPを使用してモデルが医学文献と一致しているかどうかを確認しました。結果のモデルの利点は、高い精度だけでなく、解釈が容易で臨床の知見に基づいていることです。このモデルは、テレメディシンでの使用に非常に役立ちます。それによって、CKDのリスクが高い患者を特定することができます。将来の研究では、個々の観察を調べ、モデルのどの特徴が個別のレベルで予測を推進しているのかを調べることができます。
このプロジェクトのコードはこちらで見つけることができます。本文中のすべての画像は、私がGoogle Colabを使用して生成しました。
参考文献
元のデータセットのライセンス: L. Rubini、P. Soundarapandian、P. Eswaran、Chronic_Kidney_Disease(2015)、UCI Machine Learning Repository(CC BY 4.0)
Kaggleの「慢性腎臓病」データセット: https://www.kaggle.com/datasets/mansoordaku/ckdisease
元のSHAPドキュメント: https://shap.readthedocs.io/en/latest/api_examples.html#plots
[1] Chronic Kidney Disease Basics(2022)、疾病管理予防センター
[2] C.P. Kovesdy、Epidemiology of chronic kidney disease: an update 2022(2022)、Kidney International Supplements
[3] H. Shaikh、M.F. Hashmi、N.R. Aeddula、Anemia of Chronic Renal Disease(2023)、国立医学図書館
[4] 血清(血液)クレアチニン(2023)、National Kidney Foundation
[5] J.A. Simerville、W.C. Maxted、J.J. Pahira、Urinalysis: A Comprehensive Review(2005)、American Family Physician
[6] P.F. Orlandi、他、Hematuria as a risk factor for progression of chronic kidney disease and death: findings from the Chronic Renal Insufficiency Cohort(CRIC)Study(2018)、BMC Nephrology
[7] Albuminuria(2016)、国立糖尿病・消化・腎臓病研究所
[8] R. Bagheri、Introduction to SHAP Values and their Application in Machine Learning(2022)、Towards Data Science
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
