プレイヤーの離脱を予測する方法、ChatGPTの助けを借りる
Predicting player departure with the help of ChatGPT.
低コードMLプラットフォームを使用したデータサイエンス|Actable AI
低コードプラットフォームを使用したプレイヤー離脱予測のためのデータ分析とモデルトレーニング
イントロダクション
ゲームの世界では、企業はプレイヤーを引きつけるだけでなく、特にインゲームマイクロトランザクションに依存するフリートゥープレイゲームにおいて、できるだけ長くプレイヤーを維持することを目指しています。これらのマイクロトランザクションは、インゲーム通貨の購入を含み、プレイヤーが進行やカスタマイズのためのアイテムを取得し、ゲームの開発を資金調達します。離脱率を監視することは重要です。これは、高い離脱率は収入の大幅な減少を意味し、開発者やマネージャーのストレスレベルが高まるためです。
この記事では、モバイルアプリから取得した実世界のデータセットを使用し、特にユーザーがプレイしたレベルに焦点を当てています。機械学習を活用することで、テクノロジーランドスケープの重要な部分となり、人工知能(AI)の基礎を形成する機械学習を活用することで、ビジネスはデータから価値ある洞察を抽出できます。
しかし、機械学習モデルの構築には通常、コーディングとデータサイエンスの専門知識が必要であり、多くの個人やリソースを雇用するためのリソースが不足している小規模企業にとってはアクセスが困難です。
このような課題に対応するために、低コードおよびノーコードの機械学習プラットフォームが登場し、機械学習およびデータサイエンスプロセスを簡素化し、広範なコーディング知識を必要としないようにすることで課題に対応しています。そのようなプラットフォームの例には、Einblick、KNIME、Dataiku、Alteryx、Akkioなどがあります。
この記事では、1つの低コード機械学習プラットフォームを使用して、ユーザーがゲームをプレイしなくなるかどうかを予測するモデルをトレーニングします。さらに、結果の解釈およびモデルのパフォーマンスを向上させるために使用できる技術についても説明します。
この記事の残りの部分は以下のとおりです。
- プラットフォーム
- データセット
- 探索的データ分析
- 分類モデルのトレーニング
- モデルパフォーマンスの向上
- 新しい機能の作成
- 新しい(改善された)分類モデルのトレーニング
- モデル展開の本番環境での使用
- 結論
プラットフォーム
免責事項-私はこの記事を書いた当時、Actable AIのデータサイエンティストであり、この記事で使用されるプラットフォームです。また、MLライブラリに新しい機能を実装し、メンテナンスを行っているため、実世界の問題にどのように対処するかに興味がありました。
このプラットフォームは、従来の分類、回帰、およびセグメンテーションの人気のある機械学習手法を備えたWebアプリケーションを提供しています。タイムシリーズ予測、センチメント分析、因果推論などの一部の一般的でないツールも利用可能です。欠損データを補完することもでき、データセットの統計(特徴間の相関、分散分析(ANOVA)など)を計算することもできます。また、棒グラフ、ヒストグラム、ワードクラウドなどのツールを使用してデータを可視化することができます。
Googleシートのアドオンも利用可能で、スプレッドシート内で分析およびモデルトレーニングを直接行うことができます。ただし、新しい機能がこのアドオンには利用できない場合があります。
コアライブラリはオープンソースであり、GitHubで利用可能であり、AutoGluonやscikit-learnなどのよく知られた信頼できるフレームワークで構成されています。これは、他の関連するプラットフォームでも同様であり、既存のオープンソースソリューションを活用しています。
しかし、ここで問題が生じます。ほとんどのツールがすでに利用可能であり、無料で使用できる場合、なぜこのようなプラットフォームを使用する必要があるのでしょうか?
これらのツールを使用するには、Pythonなどのプログラミング言語の知識が必要であり、一般的にコーディングに慣れていない人は使用するのが難しいか不可能である場合があります。そのため、これらのプラットフォームは、プログラミングコマンドのセットではなく、グラフィカルユーザーインターフェイス(GUI)の形式ですべての機能を提供することを目的としています。
より経験豊富なプロフェッショナルは、使いやすいグラフィカルインターフェイスによって時間を節約し、使用可能なツールや技術の情報的な説明を提供することもできるため、潜在的に利益を得ることができます。一部のプラットフォームは、あなたが馴染みのないツールを提示したり、データを扱う際に役立つ可能性のある警告(例えば、モデルが見えないデータに展開されるときに利用できない特徴にアクセスする場合のデータ漏洩など)を提供することもできます。
これらの種類のプラットフォームを使用する別の理由は、モデルを実行するためのハードウェアも提供されることです。したがって、自分自身のコンピューターやグラフィカルプロセッシングユニット(GPU)などのコンポーネントを購入して維持する必要はありません。
データセット
このプラットフォームを使用したゲーム会社が提供したデータセットは、ここで確認でき、CC BY-SA-4ライセンスが関連付けられています。適切なクレジットが提供される限り、共有や適応が可能です。データセットには、かなりの量の789,879行(サンプル)が含まれており、モデルの過剰適合などの効果を軽減するのに役立つはずです。
データセットには、ユーザーがモバイルアプリでプレイした各レベルに関する情報が含まれています。たとえば、プレイ時間、プレイヤーがレベルを勝利または敗北したかどうか、レベル番号などの情報があります。
ユーザーIDも含まれていますが、元のプレイヤーの身元を明らかにしないように匿名化されています。一部のフィールドも削除されています。ただし、このデータセットは、この記事で考慮されるMLプラットフォームがプレイヤーの転換を予測するのに役立つかどうかを確認する堅牢な基盤を提供するはずです。
各機能の意味は以下のとおりです:
転換:プレイヤーが2週間以上ゲームをプレイしていない場合は「1」、それ以外の場合は「0」サーバー時間:レベルがプレイされたときのサーバーのタイムスタンプ終了タイプ:レベルが終了した理由(プレイヤーがゲームに勝利した場合は主に「勝利」、プレイヤーがゲームに負けた場合は「敗北」)レベルタイプ:レベルの種類レベル:レベル番号サブレベル:サブレベル番号バリアント:レベルバリアントレベルバージョン:レベルバージョン次の車:未使用(後で説明されるように、1つのラベルしか持たない特徴を取り扱うプラットフォームの扱い方を確認するために含まれています)追加移動:追加の移動可能数ダブルマナ:未使用(後で説明されるように、1つのラベルしか持たない特徴を取り扱うプラットフォームの扱い方を確認するために含まれています)開始移動:レベルの開始時に利用可能な移動回数追加移動:追加の移動数使用された移動:プレイヤーが使用した移動使用された車の変更:未使用(後で説明されるように、1つのラベルしか持たない特徴を取り扱うプラットフォームの扱い方を確認するために含まれています)動画を見た:追加の移動を提供する動画が視聴されたかどうかより多くの移動を購入する:プレイヤーがより多くの移動を購入した回数プレイ時間:レベルで費やした時間スコア:プレイヤーが達成したスコア使用されたコイン:レベルで使用された総コイン数最大レベル:プレイヤーが到達した最大レベルプラットフォーム:デバイスタイプユーザーID:プレイヤーのIDローリングロス:プレイヤーによる連続した敗北回数
探索的データ分析
トレーニングの前に最初に行うべきことは、探索的データ分析(EDA)を通じてデータを理解することです。EDAは、データセットの主な特徴を要約し、視覚化し、理解するデータ分析手法です。目的は、データに洞察を得て、パターン、トレンド、異常値、または存在する可能性のある問題(欠損値など)を特定し、使用する特徴量やモデルを調整するのに役立つことです。
まず、レベルが終了する主な理由を確認してみましょう:
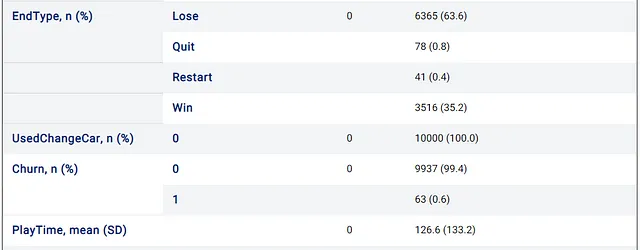
上記の画像では、レベルが終了する主要な原因(EndTypeで表される)は、プレイヤーがゲームに負けたため(63.6%)であり、プレイヤーがゲームに勝った場合は35.2%です。また、UsedChangeCar列については、すべての行に同じ値が含まれているため、無用であると思われます。
非常に重要な観察結果として、ターゲット値が非常に不均衡であり、最初の10,000行のうちわずか63サンプル(つまりデータの0.6%)が1の離脱値(つまりプレイヤーが離脱した)を持っていることが挙げられます。これは、モデルがChurnの値を0のみに予測することが非常に容易である可能性があるため、心に留めておく必要があります。その理由は、モデルが精度などのいくつかのメトリックで非常に良い値を得ることができるためです。この場合、もっとも一般的なクラスを単純に選択するダミーモデルの場合、99.4%が正しいとなります。Baptiste RoccaとJason Brownleeによる2つの素晴らしい記事で詳しく説明しています。
残念ながら、Actable AIにはまだ、Synthetic Minority Oversampling Technique(SMOTE)を介して不均衡なデータを処理する方法、またはクラスの重みや異なるサンプリング戦略を使用する方法はありません。これは、最適化に選択されたメトリックに注意する必要があることを意味します。上記のように、正確さは、1つのクラスのサンプルが正しくラベル付けされない場合でも高いレートを達成できるため、最適な選択肢ではありません。
特に、予測子特徴量とターゲット特徴量の間の相関関係を分析することは、非常に有用です。これは「相関分析」ツールを使用して行うことができ、その結果はここでActable AIプラットフォームで直接表示できます:
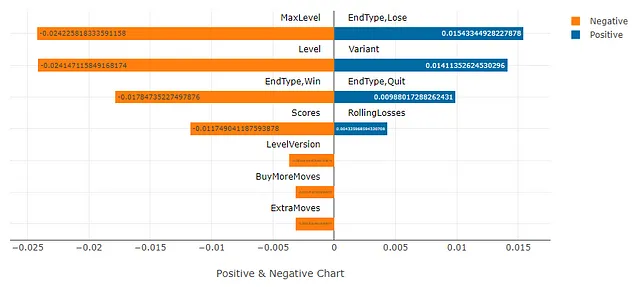
上記のチャートでは、青い棒は、値が1の場合にChurnとの正の相関関係を示し、一方、オレンジの棒は負の特徴量相関関係を示します。相関は-1から1の間にあり、正の値は両方の特徴量が同じ方向に変化する傾向があることを示し(例えば、両方が増加または両方が減少する)、負の相関は、1つの特徴量が増加または減少する場合、もう一方が反対に動くことを単に示します。したがって、相関の大きさ(負の符号を無視する)が最も重要な点であると言えます。
レベルを失ったプレイヤーが離脱する可能性が高い(最上位の青い棒)というような、いくつかのポイントを含め、多くのことが学べます。しかし、これらの値はかなり低いことにも注意する必要があり、これらの特徴はターゲットと比較して弱く相関していることを示しています。これは、より正確な予測を実行するために、既存の特徴を使用して、より重要な情報をキャプチャする新しい特徴を作成する機能エンジニアリングを実行する必要がある可能性があることを意味します。機能エンジニアリングについては、後で詳しく説明します。
ただし、新しい特徴を作成する前に、データセットの元の特徴だけを使用してどのようなパフォーマンスが得られるかを見ることも価値があります。次のステップは、おそらくよりエキサイティングになるでしょう。つまり、どのようなパフォーマンスが得られるかを確認するためにモデルをトレーニングすることです。
分類モデルのトレーニング
ユーザーがプレイをやめるかどうかを予測したいと考えているため、これは選択する必要があるラベルの数がいくつかある分類問題であり、二値分類問題になります(「Churn」に対応する「1」と「No Churn」に対応する「0」のうちの1つを割り当てる必要があります)。
このプロセスは、主にAutoGluonライブラリを使用して行われ、自動的に複数のモデルをトレーニングして、最良のパフォーマンスを達成したモデルを選択することによって行われます。これにより、個々のモデルを手動でトレーニングしてパフォーマンスを比較する必要がなくなります。
Actable AI プラットフォームで設定する必要がある多くのパラメータがあり、以下に私の選択肢が表示されています:
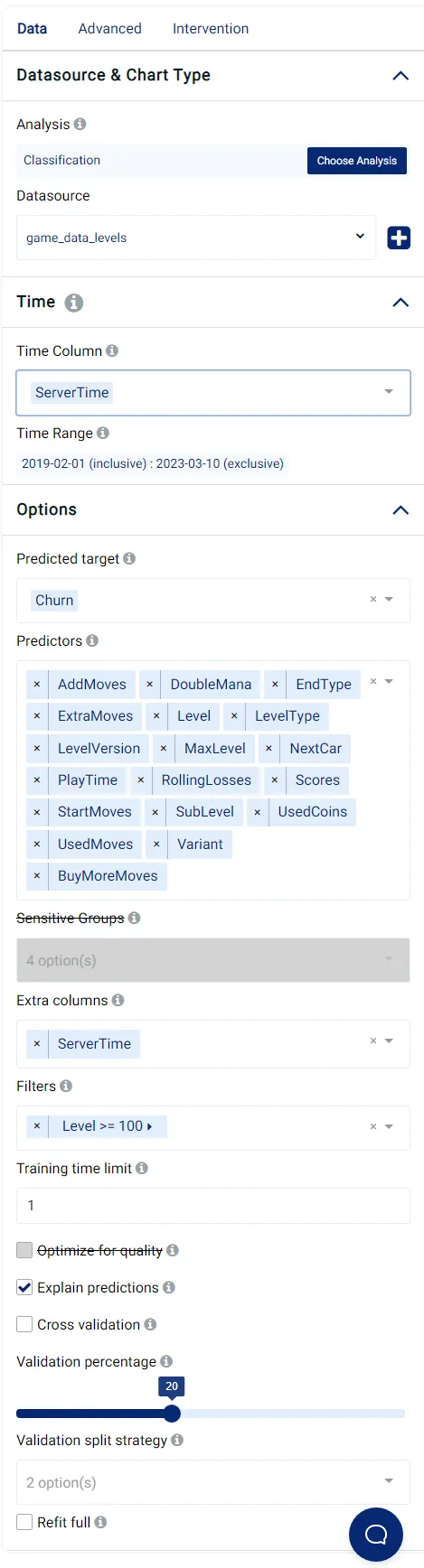
モデルの最適化に使用するメトリックも選択できます。私は受信者動作特性 (AUC ROC) 曲線下面積を使用しました。これは、先に議論したクラスの不均衡問題に対してはるかに感度が低いためです。値の範囲は0から1までであり、1は完璧なスコアを示します。
しばらくすると、結果が生成され表示されます。結果はこちらでも確認できます。多くの異なるメトリックが計算されます。これはすぐれた習慣であり、モデルのパフォーマンスのある側面に焦点を当てるために必要不可欠です。
最初に表示されるメトリックは、0.675の最適化メトリックです:
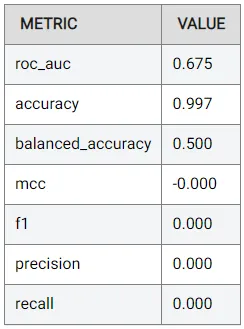
これはあまり良くありませんが、EDA中に特徴量がターゲットと弱く相関していたことを思い出せば、パフォーマンスが目立たないことは驚くことではありません。
この結果は、結果を理解することの重要性も示しています。通常、0.997 (つまり99.7%) の精度に非常に満足することがありますが、これはデータセットの非常に不均衡な性質によるものであり、あまり重要ではありません。一方、精度と再現率のようなスコアは、0.5の閾値に基づいており、最適な閾値とは限らないかもしれません。
ROC曲線と精度-再現率曲線も表示され、ここでもパフォーマンスがやや低いことが明確に示されています:
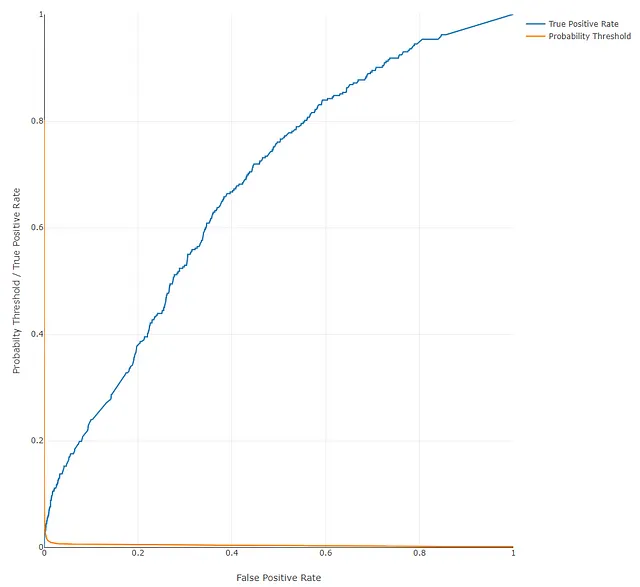
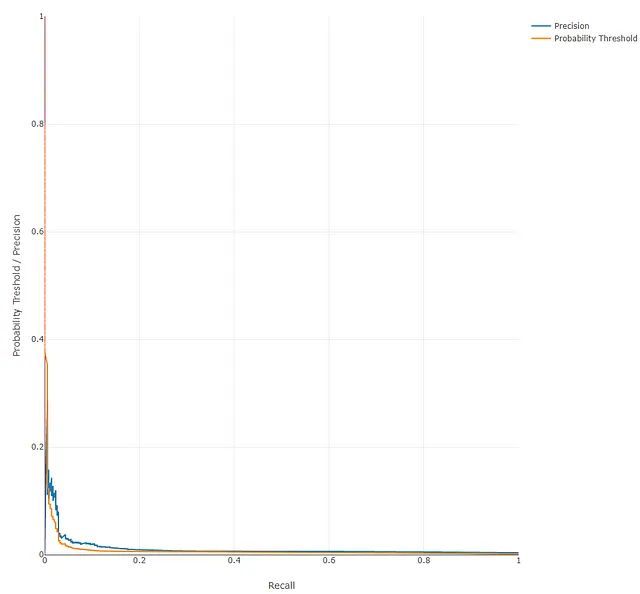
これらの曲線は、最終的なアプリケーションで使用する閾値を決定するためにも役立ちます。たとえば、偽陽性の数を最小限に抑えたい場合、モデルがより高い精度を得る閾値を選択し、対応する再現率を確認できます。
また、最良のモデルで推定された各クラスの確率 (この場合は1または0) も表示できます。これらの確率は、予測されたクラスを導出するのに使用されます (デフォルトでは、最も高い確率を持つクラスが予測されたクラスとして割り当てられます)。
また、最良のモデルの各特徴量の重要度も表示できます。これは、AutoGluonを介して置換重要度を使用して計算されます。P値も表示され、結果の信頼性を判断します:
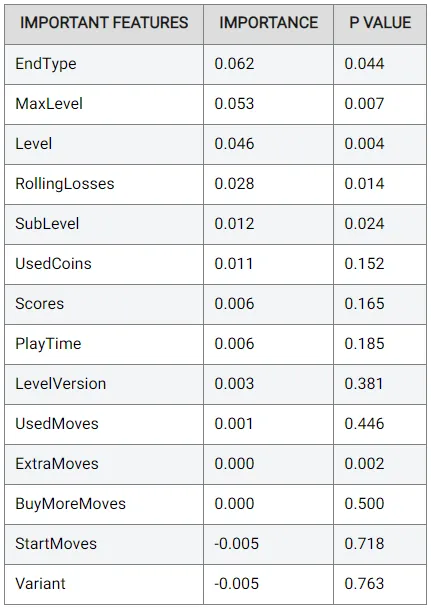
おそらく予想通りですが、最も重要な特徴量は EndType (レベルが終了した原因、たとえば勝利または敗北を示す) であり、次に MaxLevel (ユーザーがプレイした最高レベルで、より高い数字はプレイヤーがゲームに非常に熱心でアクティブであることを示します) です。
一方、UsedMoves (プレイヤーが実行した移動の数) は実質的に役に立たず、StartMoves (プレイヤーが利用可能な移動の数) はパフォーマンスを損なう可能性があります。これも理にかなっています。プレイヤーが使用した移動数とプレイヤーが利用可能な移動数自体は、高度に情報を伝えるものではありません。それらを比較することの方がはるかに有用である可能性があります。

説明可能なAIは、モデルの振る舞いを理解するためにますます重要になっています。そのため、シャプレー値などのツールが人気を集めています。これらの値は、予測されたクラスの確率における特徴の貢献を表します。例えば、最初の行では、RollingLossesの値が36の場合、そのプレーヤーについて予測されたクラス(クラス0、つまりゲームを続ける可能性がある人)の確率が低下します。
逆に、これは、他のクラス(クラス1、つまりプレーヤーが去る可能性があるクラス)の確率が増加することを意味します。これは、RollingLossesの高い値は、プレーヤーが連続して多くのレベルを失ったことを示し、失望によってゲームを止める可能性が高いためです。一方、RollingLossesの値が低い場合、プレーヤーがゲームを続ける可能性が高くなります。
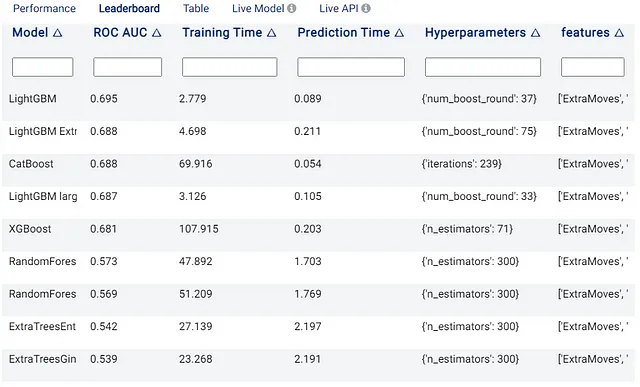
前述のように、いくつかのモデルをトレーニングして評価した後、最良のモデルが選択されます。この場合、最高のモデルはLightGBMであり、最も高速なモデルの1つでもあります:
モデルのパフォーマンスを向上させる
この時点で、モデルのパフォーマンスを向上させることができます。たとえば、「品質を最適化」オプションを選択して、どこまで改善できるか確認できます。このオプションは、一般的にパフォーマンスを向上させるいくつかのパラメータを設定しますが、トレーニング時間が遅くなる可能性があります。次の結果が得られました(こちらでも確認できます):
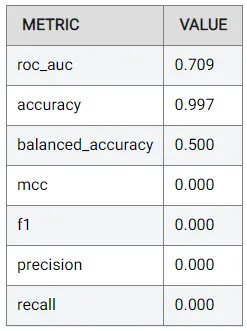
再びROC AUCメトリックに焦点を当てると、パフォーマンスは0.675から0.709に向上しました。これは非常に単純な変更に対してかなりの改善ですが、まだ理想的な状態には程遠いです。さらに改善するためには、他に何かできることがあるでしょうか?
新しい特徴を作成する
先に述べたように、特徴エンジニアリングを使用してこれを行うことができます。これには、既存の特徴から新しい特徴を作成することが含まれます。これらの特徴は、より強いパターンを捉え、予測される変数とより高い相関があるため、非常に役立ちます。
私たちの場合、データセットの特徴は、1つのレコードに関連する値に限定されているため、比較的狭い範囲にあります(つまり、ユーザーがプレイしたレベルの情報)。したがって、時間にわたってレコードを要約することで、より大局的な見方をすることが非常に役立ちます。この方法で、モデルはユーザーの歴史的な傾向についての知識を持つことになります。
たとえば、プレーヤーが使用した余分な動きの数を決定し、経験した難易度の尺度を提供できます。余分な動きが少なく、レベルが簡単だった場合、一方、多くの余分な動きが必要だった場合は、レベルが難しかったということになります。
また、過去数日間にプレイした時間をチェックして、ユーザーがゲームに没頭しているかどうか、そして遊び続ける可能性があるかどうかを確認することも良いアイデアです。プレーヤーがゲームをあまりプレイしていない場合、興味を失ってすぐにやめる可能性があります。
有用な特徴は、異なるドメインによって異なります。そのため、タスクに関連する情報を見つけることが重要です。たとえば、研究論文、事例、記事を探したり、フィールドで働いている経験豊富で精通している企業や専門家のアドバイスを求めたりすることで、一般的な特徴、特徴間の関係、潜在的な落とし穴、および最も有用な新しい特徴を把握することができます。これらのアプローチは、試行錯誤を減らし、特徴エンジニアリングのプロセスを加速するのに役立ちます。
最近、大規模言語モデル(LLMs)の進歩があった(例えば、ChatGPTというものを聞いたことがあるかもしれない…)、また、機能エンジニアリングのプロセスが未経験のユーザーにとっては少し困難かもしれないため、LLMsがどのようにして新しい機能を提供するためのアイデアを提供できるかを見てみたかった。私は以下の出力を生成しました:
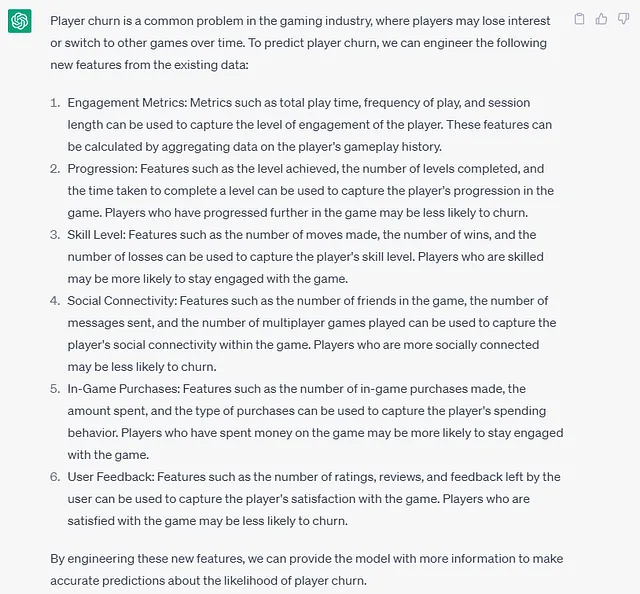
ChatGPTの回答は実際には非常に良く、上述の時間ベースの機能のいくつかを指摘しています。もちろん、必要な情報が利用できない場合、提案された機能をすべて実装できないことに注意してください。また、幻覚に陥る傾向があることがよく知られており、完全に正確な回答を提供しない可能性があることも覚えておいてください。
ChatGPTからより関連性の高い返答を得ることができます。たとえば、使用している機能を指定したり、プロンプトを使用することによってですが、これはこの記事の範囲外であり、読者の練習問題として残されています。それにもかかわらず、LLMsは始めるための初歩的なステップとして考えられますが、論文、プロフェッショナルなどからより信頼できる情報を求めることを強くお勧めします。
Actable AIプラットフォームでは、比較的よく知られたSQLプログラミング言語を使用して新しい機能を作成することができます。SQLに慣れていない人は、ChatGPTを使用してクエリを自動生成する方法が役立つ場合があります。しかし、私の限られた実験では、この方法の信頼性はやや不一致することがあることに注意してください。
意図した出力の正確な計算を保証するために、所望の出力が正しく計算されていることを確認するために、結果のサブセットを手動で検証することをお勧めします。これは、SQL Lab、Actable AIのSQLコードを書いて実行するためのインターフェースでクエリが実行された後に表示されるテーブルを確認することで簡単に行うことができます。
以下は、新しい列を生成するために使用したSQLコードです。これは、他の機能を作成したい場合に役立つはずです:
SELECT *, SUM("PlayTime") OVER UserLevelWindow AS "time_spent_on_level", (a."Max_Level" - a."Min_Level") AS "levels_completed_in_last_7_days", COALESCE(CAST("total_wins_in_last_14_days" AS DECIMAL)/NULLIF("total_losses_in_last_14_days", 0), 0.0) AS "win_to_lose_ratio_in_last_14_days", COALESCE(SUM("UsedCoins") OVER User1DayWindow, 0) AS "UsedCoins_in_last_1_days", COALESCE(SUM("UsedCoins") OVER User7DayWindow, 0) AS "UsedCoins_in_last_7_days", COALESCE(SUM("UsedCoins") OVER User14DayWindow, 0) AS "UsedCoins_in_last_14_days", COALESCE(SUM("ExtraMoves") OVER User1DayWindow, 0) AS "ExtraMoves_in_last_1_days", COALESCE(SUM("ExtraMoves") OVER User7DayWindow, 0) AS "ExtraMoves_in_last_7_days", COALESCE(SUM("ExtraMoves") OVER User14DayWindow, 0) AS "ExtraMoves_in_last_14_days", AVG("RollingLosses") OVER User7DayWindow AS "RollingLosses_mean_last_7_days", AVG("MaxLevel") OVER PastWindow AS "MaxLevel_mean"FROM ( SELECT *, MAX("Level") OVER User7DayWindow AS "Max_Level", MIN("Level") OVER User7DayWindow AS "Min_Level", SUM(CASE WHEN "EndType" = 'Lose' THEN 1 ELSE 0 END) OVER User14DayWindow AS "total_losses_in_last_14_days", SUM(CASE WHEN "EndType" = 'Win' THEN 1 ELSE 0 END) OVER User14DayWindow AS "total_wins_in_last_14_days", SUM("PlayTime") OVER User7DayWindow AS "PlayTime_cumul_7_days", SUM("RollingLosses") OVER User7DayWindow AS "RollingLosses_cumul_7_days", SUM("PlayTime") OVER UserPastWindow AS "PlayTime_cumul" FROM "game_data_levels" WINDOW User7DayWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" RANGE BETWEEN INTERVAL '7' DAY PRECEDING AND CURRENT ROW ), User14DayWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" RANGE BETWEEN INTERVAL '14' DAY PRECEDING AND CURRENT ROW ), UserPastWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW )) AS aWINDOW UserLevelWindow AS ( PARTITION BY "UserID", "Level" ORDER BY "ServerTime" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ), PastWindow AS ( ORDER BY "ServerTime" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ), User1DayWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND CURRENT ROW ), User7DayWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" RANGE BETWEEN INTERVAL '7' DAY PRECEDING AND CURRENT ROW ), User14DayWindow AS ( PARTITION BY "UserID" ORDER BY "ServerTime" RANGE BETWEEN INTERVAL '14' DAY PRECEDING AND CURRENT ROW )ORDER BY "ServerTime";このコードでは、ゲーム内のプレーヤーの旅の歴史的な文脈を提供するために、主に特徴計算中に使用される、過去の日数を定義する「ウィンドウ」が作成されます。最後の日、最後の週、または過去2週間などを考慮することができます。その範囲内にあるレコードが機能計算で使用され、その全ての機能が以下の通りです:
time_spend_on_level: レベルをプレイするユーザーが費やした時間。レベルの難易度を示します。levels_completed_in_last_7_days: 過去7日間(1週間)におけるユーザーのクリアしたレベルの数。レベルの難易度、忍耐力、ゲームへの没頭度を示します。total_wins_in_last_14_days: ユーザーがレベルを勝利した総数total_losses_in_last_14_days: ユーザーがレベルを失敗した総数win_to_lose_ratio_in_last_14_days: 勝利数と敗北数の割合 (total_wins_in_last_14_days/total_losses_in_last_14_days)UsedCoins_in_last_1_days: 前日の使用されたコインの数。ゲーム内通貨を消費するプレイヤーの意欲、レベルの難易度を示します。UsedCoins_in_last_7_days: 過去7日間(1週間)における使用されたコインの数UsedCoins_in_last_14_days: 過去14日間(2週間)における使用されたコインの数ExtraMoves_in_last_1_days: 前日にユーザーが使用した余分な動きの数。レベルの難易度を示します。ExtraMoves_in_last_7_days: 過去7日間(1週間)におけるユーザーが使用した余分な動きの数ExtraMoves_in_last_14_days: 過去14日間(2週間)におけるユーザーが使用した余分な動きの数RollingLosses_mean_last_7_days: 過去7日間(1週間)におけるユーザーの累積敗北数の平均値。レベルの難易度を示します。MaxLevel_mean: すべてのユーザーで到達した最大レベルの平均値。Max_Level: 過去7日間(1週間)においてプレイヤーが到達した最大レベル。MaxLevel_meanと併用することで、他のプレイヤーとの進捗を示します。Min_Level: 過去7日間(1週間)にユーザーがプレイした最小レベルPlayTime_cumul_7_days: 過去7日間(1週間)にユーザーがプレイした総時間。プレイヤーのゲームへの没頭度を示します。PlayTime_cumul: ユーザーがプレイした総時間(最初の利用可能なレコード以降)RollingLosses_cumul_7_days: 過去7日間(1週間)におけるユーザーの累積敗北数の合計。レベルの難易度を示します。
特定の行で新しい機能の値を計算する際には、過去のレコードのみを使用することが重要です。言い換えると、将来の観測値の使用は避ける必要があります。なぜなら、モデルが本番環境で展開される際には、将来の値にアクセスすることができないからです。
作成された機能に満足したら、新しいデータセットとしてテーブルを保存し、新しいモデルを実行して(うまくいけば)より良いパフォーマンスを得ることができます。
新しい(うまくいけば改善された)分類モデルのトレーニング
新しい列がどのように役立つかを確認する時が来ました。前と同じ手順を繰り返し、追加機能を含む新しいデータセットを使用することで、元のモデルとの公平な比較を有効にします。次の結果が得られます(こちらでも表示できます):
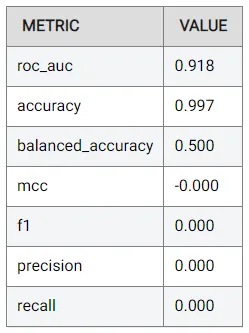
ROC AUC 値が 0.918 に改善され、元の値である 0.675 よりもはるかに良くなりました。品質に最適化されたモデル(0.709)よりもさらに優れています!これは、データを理解し、より豊富な情報を提供できる新しい特徴を作成することの重要性を示しています。
今度は、どの新しい特徴が実際に最も役立ったのかを見ることが興味深いでしょう。再び、特徴の重要度テーブルを確認することができます:
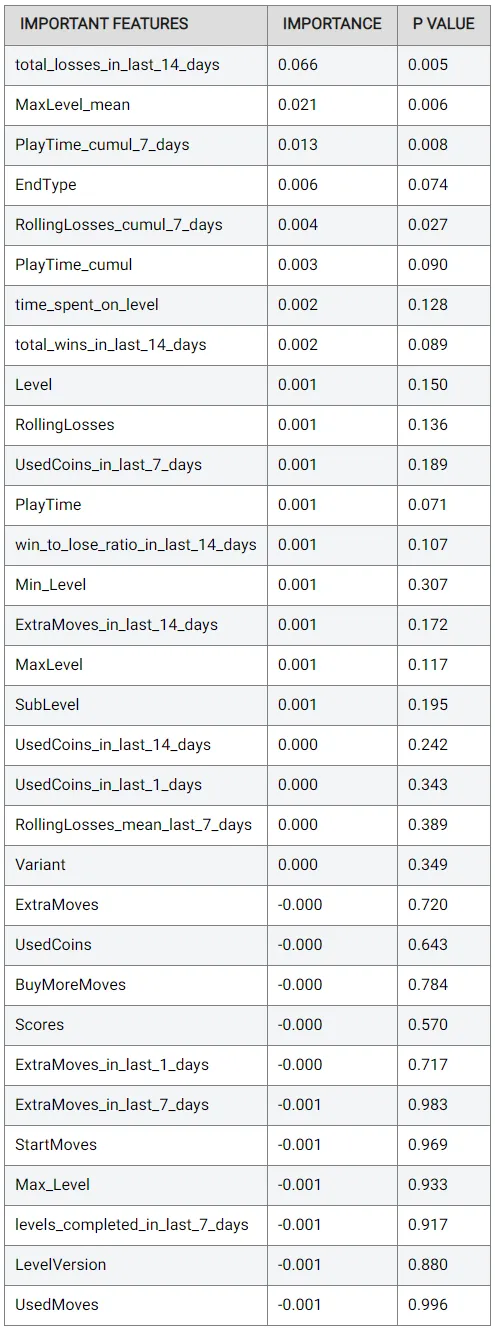
最後の2週間の敗北回数の総数がかなり重要であるようです。これは、プレイヤーがより頻繁にゲームに負けるほど、彼らがイライラしてプレイをやめる可能性が高くなるため、理にかなっています。
全ユーザーの平均最大レベルも重要であるようです。これも、プレイヤーが他のプレイヤーの大多数からどれだけ離れているかを決定するために使用できます。平均よりもはるかに高い場合、プレイヤーはゲームに没頭していることを示し、平均よりもはるかに低い値は、まだ動機付けが不十分であることを示す場合があります。
これらは、作成できるいくつかのシンプルな特徴の一部です。さらにパフォーマンスを向上させることができる他の特徴があります。これらの特徴を作成するための演習を読者に任せます。
品質に最適化されたモデルを以前と同じ時間制限でトレーニングしてもパフォーマンスが向上しなかった。しかし、これは使用される特徴が多くなっているため、最適化にはより多くの時間が必要かもしれないため、理解できます。ここで観察できるように、時間制限を6時間に増やすと、AUCに関してパフォーマンスが0.923に向上します:
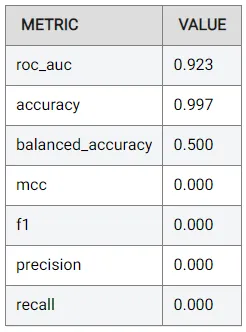
精度や再現率などのメトリックはまだかなり低いことに注意する必要があります。ただし、分類しきい値が0.5であることが前提条件であるため、これは最適ではない場合があります。実際、これが私たちが閾値を調整した場合にパフォーマンスのより包括的な画像を提供できるAUCに焦点を当てた理由でもあります。
トレーニングされたモデルのAUCによるパフォーマンスは次のようにまとめることができます:
┌─────────────────────────────────────────────────────────┬───────────┐│ モデル │ AUC (ROC) │├─────────────────────────────────────────────────────────┼───────────┤│ オリジナルの特徴 │ 0.675 ││ オリジナルの特徴 + 品質に最適化 │ 0.709 ││ エンジニアリングされた特徴 │ 0.918 ││ エンジニアリングされた特徴 + 品質に最適化 + より長い時間 │ 0.923 │└─────────────────────────────────────────────────────────┴───────────┘本番環境でのモデル展開
良いモデルを持っていても、新しいデータで使用できない場合は役に立ちません。機械学習プラットフォームは、トレーニングされたモデルを使用して将来の見えないデータに対して予測を生成する機能を提供する場合があります。たとえば、Actable AIプラットフォームでは、APIを使用して、プラットフォーム外のデータでモデルを使用できます。また、モデルをエクスポートしたり、生の値を挿入して即座に予測を取得することもできます。
ただし、モデルを定期的に将来のデータでテストし、予想どおりにパフォーマンスが維持されているかどうかを判断することが重要です。実際、新しいデータでモデルを再トレーニングする必要がある場合があります。これは、特性(例:特徴分布)が時間の経過とともに変化し、それがモデルの正確性に影響を与える可能性があるためです。
たとえば、会社が新しい方針を導入し、それが顧客の行動に影響を与える場合がありますが、新しい変更を反映する特徴がない場合、モデルは新しい方針を考慮できない場合があります。特徴を反映することができない劇的な変化がある場合は、古いデータでトレーニングおよび使用される1つのモデルと、新しいデータでトレーニングおよび使用される別のモデルの使用を検討する価値があります。これにより、モデルが異なる特性のデータで操作するように特化されるため、単一のモデルでは捉えるのが難しい特性を持つデータで動作します。
結論
この記事では、モバイルアプリでユーザーがプレイした各レベルに関する情報を含む実世界のデータセットを使用して、2週間後にプレイヤーがゲームをやめるかどうかを予測する分類モデルをトレーニングするために使用しました。
EDAからモデルトレーニング、特徴量エンジニアリングまで、全体の処理パイプラインが考慮されました。結果の解釈や改善方法についての議論が提供され、0.675から0.923(1.0が最大値である場合)に向上することができました。
作成された新しい特徴量は比較的シンプルですが、考慮すべき多くの特徴量が存在することは確かです。さらに、特徴量の正規化や標準化などの技術も考慮することができます。こことここでいくつかの役立つリソースが見つかります。
Actable AIプラットフォームに関して言えば、私はもちろん少し偏っているかもしれませんが、データサイエンティストや機械学習の専門家が行う必要のあるより煩雑なプロセスを簡素化するのに役立つと思います。以下の望ましい側面があります:
- Core MLライブラリはオープンソースであり、プログラミングに良い知識を持つ人なら誰でも安全に使用できます。Pythonを知っている人なら誰でも使用できます。
- Pythonを知らない人やコーディングに慣れていない人に対して、GUIは多くの分析や視覚化を簡単に使用できます。
- プラットフォームの使用を開始するのはあまり難しくありません(より技術的な情報が少ないため、知識の少ない人々が使用することを躊躇することがないようになっています)。
- 無料のティアでは、パブリックデータセット上で分析を実行できます。
- 多数のツールが利用可能です(この記事で考慮された分類以外)。
ただし、いくつかの欠点があり、以下のように改善されるべき側面もあります:
- 無料のティアでは、プライベートデータ上でMLモデルを実行することはできません。
- ユーザーインターフェースは少し時代遅れです。
- 一部の視覚化は不明確で、解釈が難しいことがあります。
- アプリが時々反応しなくなることがあります。
- 主要な結果を計算および表示する際に0.5以外の閾値を使用できないことがあります。
- 不均衡データのサポートはありません。
- プラットフォームから最大限の利益を引き出すためには、データサイエンスや機械学習の知識が依然として必要です(ただし、これは他のプラットフォームにも当てはまることでしょう)。
将来の記事では、他のプラットフォームを使用して、それぞれのプラットフォームに最適なユースケースを判断することを検討します。
それまでの間、この記事が興味深かったことを願っています!ご意見や質問があれば、お気軽にお知らせください!
この記事についてのご意見はありますか?LinkedInでメモ、コメント、または直接メッセージを投稿してください!
また、今後の記事の発行を通知するためにフォローしてください。
著者は、この記事を書いた当時Actable AIのデータサイエンティストでした。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
