ヒッティングタイム予測:時系列確率予測の別の方法
Predicting Hitting Time Another Method of Time-Series Probability Prediction.
特定の値に到達するまでにかかる時間はどれくらいですか?
正確な予測を行う能力は、すべての時系列予測アプリケーションにとって基本的です。その目的に従って、データサイエンティストは、点予測の観点から誤差を最小化する最良のモデルを選択することに慣れています。それは正しいことですが、常に最善の効果的なアプローチではないかもしれません。
データサイエンティストは、確率的予測モデルの開発の可能性も考慮する必要があります。これらのモデルは、点推定とともに、将来の観測値が落ちる可能性がある上限と下限の信頼性バンドも生成します。確率的予測は、統計的または深層学習ソリューションの専売特許に見えるかもしれませんが、どのモデルでも確率的予測を生成することができます。この概念は、scikit-learnモデルで予測区間を推定する方法として、conformal predictionを紹介した 以前の記事で説明されています。
確かに、点予測は非技術的なステークホルダーに伝えるのがはるかに簡単です。同時に、予測の信頼性に関するKPIを生成する可能性は付加価値です。将来の数ミリメートルの雨量を報告するよりも、次の数時間に60%の雨が降る可能性があることを伝える方が情報量が多いかもしれません。
この記事では、特定のイベントまたは条件が発生する時間を推定するために使用される予測技術である、ヒッティングタイム予測を提案します。それは、conformal predictionに基づいているため正確であり、確率的に解釈可能であるため解釈可能であり、予測技術によって再現可能です。
ヒッティングタイム予測の紹介
ヒッティングタイム予測は、さまざまな分野で一般的に使用される概念です。これは、特定の閾値やレベルに到達する文脈で、あるイベントまたは条件が発生するまでにかかる時間を予測または推定することを示します。
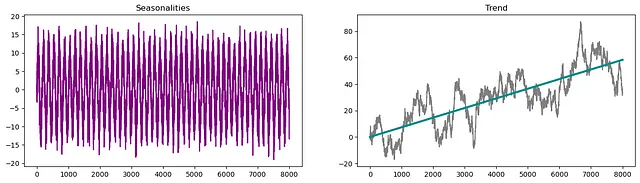
ヒッティングタイムの最も一般的な応用は、信頼性分析や生存分析などの分野に関連しています。これは、システムやプロセスが特定のイベント(故障や特定の状態に到達など)を経験するまでにかかる時間を推定することを含みます。金融業界では、ヒッティングタイムは、シグナル/インデックスが所望の方向に従う確率を決定するためにしばしば適用されます。
全体的に、ヒッティングタイム予測は、時間的な動態に従う特定のイベントが発生するまでにかかる時間に関する予測を行うことを含みます。
点予測から確率的予測へ
ヒッティングタイムを正しく推定するには、点予測から始める必要があります。最初のステップとして、望ましい予測アルゴリズムを選択します。この記事では、tspiralから簡単に利用できる再帰推定器を採用します。
model = ForecastingCascade( Ridge(), lags=range(1,24*7+1), use_exog=False,)私たちの目標は、各予測ポイントから予測分布を生成し、確率的な洞察を抽出することです。これは、コンフォーマル予測の理論を利用して、3段階のアプローチに従って行われます:
- 予測は、交差検証を通じてトレーニングセットから収集され、それらを平均化します。
CV = TemporalSplit(n_splits=10, test_size=y_test.shape[0])pred_val_matrix = np.full( shape=(X_train.shape[0], CV.get_n_splits(X_train)), fill_value=np.nan, dtype=float,)for i, (id_train, id_val) in enumerate(CV.split(X_train)): pred_val = model.fit( X_train[id_train], y_train[id_train] ).predict(X_train[id_val]) pred_val_matrix[id_val, i] = np.array( pred_val, dtype=float )pred_val = np.nanmean(pred_val_matrix, axis=1)- コンフォーマルスコアは、交差検証された予測と実際の値との絶対残差としてトレーニングデータ上で計算されます。
conformity_scores = np.abs( np.subtract( y_train[~np.isnan(pred_val)], pred_val[~np.isnan(pred_val)] ))- 将来の予測分布は、コンフォーマルスコアをテスト予測に加えることで得られます。
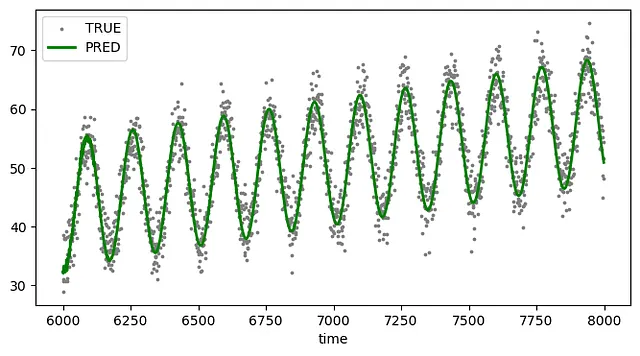
pred_test = model.fit( X_train, y_train).predict(X_test)estimated_test_distributions = np.add( pred_test[:, None], conformity_scores)![Predicted distribution on test data [image by the author]](https://miro.medium.com/v2/resize:fit:640/format:webp/0*ZR-L88qovOqG5ecg.png)
上記の手順に従うことで、将来の値がたどる可能性のある軌跡のコレクションを得ることができます。これにより、予測の確率的な表現を提供するために必要なすべてが揃います。
確率的からヒッティングタイム予測へ
将来の各時間点について、推定されたテスト分布内の値があらかじめ定義された閾値(ヒットターゲットレベル)を超えた回数が記録されます。このカウントは、各推定されたテスト分布内の値の数で単純に正規化することで確率に変換されます。
最後に、確率の配列に変換するために一連の単調増加確率を適用します。
THRESHOLD = 40prob_test = np.mean(estimated_test_distributions > THRESHOLD, axis=1)prob_test = pd.Series(prob_test).expanding(1).max()![Predicted vs real data points on test set plus hitting time probabilities [image by the author]](https://miro.medium.com/v2/resize:fit:640/format:webp/0*QT4kJ33gPz0CfLlw.png)
予測しようとしているイベントに関係なく、予測ポイントから単に確率曲線を生成することができます。解釈は明快であり、各予測時間点において、ターゲット系列があらかじめ定義されたレベルに達する確率を導出できます。
サマリー
この記事では、予測モデルに確率的な結果を提供する方法を紹介しました。奇妙で集中的な追加の推定技術の適用は必要ありません。単にポイント予測問題から始め、ヒッティングタイムアプローチを適用することで、タスクに確率的な概要を追加することができます。
私のGitHubリポジトリをチェックしてください
お問い合わせ先:Linkedin
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
