「探索的データ分析の改善のための実践的なヒント」
Practical tips for improving exploratory data analysis
EDAを簡単かつ美しくするための短いガイド
はじめに
機械学習モデルを使用する前に、探索的データ解析(EDA)は必須のステップです。EDAプロセスには、データアナリストやデータサイエンティストから焦点と忍耐が必要です。分析されたデータから意味のある洞察を得るためには、しばしば1つまたは複数の可視化ライブラリを積極的に使用することが必要です。
この記事では、個人的な経験に基づいて、EDA手順を簡単にし、より速くするためのいくつかのヒントを共有します。特に、EDAに対抗しながら学んだ3つの重要なアドバイスを提供します。
- タスクに最も適した非自明なチャートを使用すること。
- 可視化ライブラリの機能を最大限に活用すること。
- 同じものをより速く作る方法を探すこと。
注:この記事のインフォグラフィックス作成には、Kaggle [2] の風力発電データを使用します。さあ始めましょう!
ヒント1:非自明なチャートの使用に怯えないこと
私は、風力エネルギーの分析と予測に関連する研究論文に取り組んでいたときに、このヒントの適用方法を学びました [1]。このプロジェクトのEDAを行っている間、相互に最も強い影響を持つ風パラメータの関係を反映するサマリーマトリックスを作成する必要がありました。最初に思い浮かんだアイデアは、データサイエンス/データ分析プロジェクトでよく見かける「古き良き」相関行列を作成することでした。
- レコメンドシステムの評価指標 — 概要
- 「2023年に必要な機械学習エンジニアの10の必須スキル」
- 「DeepMindによるこのAI研究は、シンプルな合成データを使用して、大規模な言語モデル(LLM)におけるおべっか使用を減らすことを目指しています」
ご存知のように、相関行列は変数間の線形関係を定量化し要約するために使用されます。以下のコードスニペットでは、風力発電データの特徴量列にcorrcoef関数が使用されています。ここでは、Seabornのheatmap関数も使用して、相関行列配列をヒートマップとしてプロットしています。
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdimport numpy as np# データ読み込みdata = pd.read_csv('T1.csv')print(data)# 列名を短くするためにリネームdata.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# マトリックスの作成correlation_matrix = np.corrcoef(data[cols].values.T)hm = sns.heatmap(correlation_matrix, cbar=True, annot=True, square=True, fmt='.3f', annot_kws={'size': 15}, cmap='Blues', yticklabels=['P', 'Ws', 'Power_curve', 'Wa'], xticklabels=['P', 'Ws', 'Power_curve', 'Wa'])# 画像を保存plt.savefig('image.png', dpi=600, bbox_inches='tight')plt.show()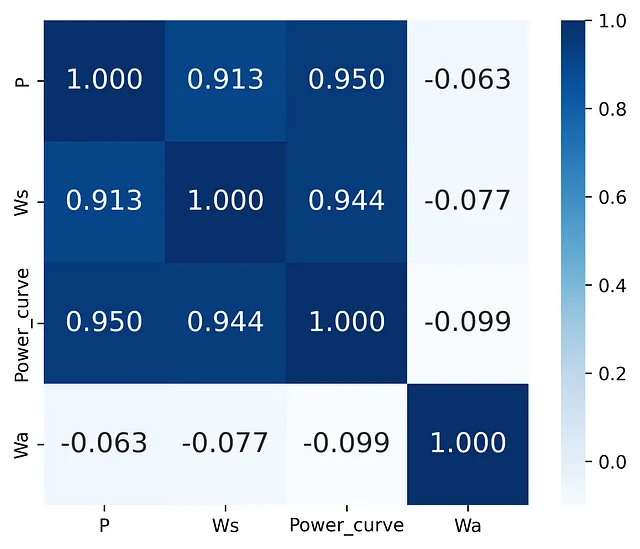
得られたグラフィカル結果を分析すると、風速と有効出力の間に強い相関があることがわかりますが、このような可視化を使用する場合、結果を解釈するのは簡単ではないと思います。なぜなら、ここでは数字だけが表示されているからです。
相関行列のよい代替手段は、散布図行列です。散布図行列を使用すると、データセットの異なる特徴量間のペアごとの相関関係を一箇所で視覚化することができます。この場合は、sns.pairplotを使用する必要があります。
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pd# データ読み込みdata = pd.read_csv('T1.csv')print(data)# 列名を短くするためにリネームdata.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# マトリックスの作成sns.pairplot(data[cols], height=2.5)plt.tight_layout()# 画像を保存plt.savefig('image2.png', dpi=600, bbox_inches='tight')plt.show()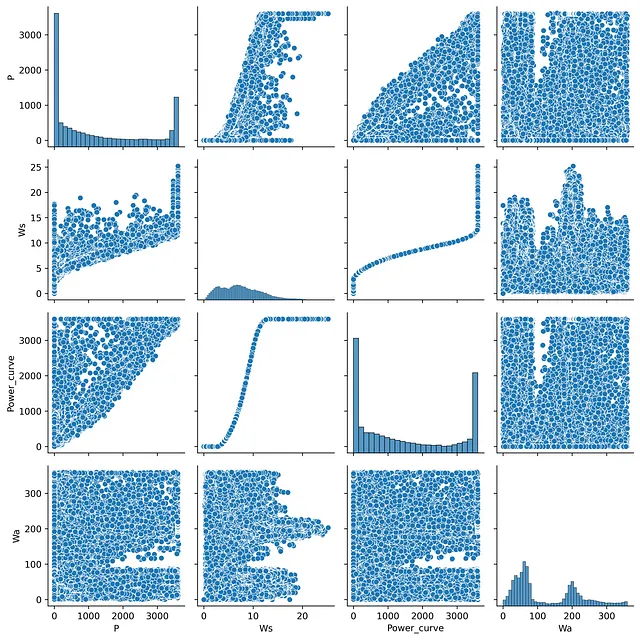
散布図行列を見ることで、データの分布や外れ値の有無を素早く確認することができます。ただし、この種のグラフの主な欠点は、データをペアごとにプロットするアプローチによる重複の存在に関連しています。
最終的に、上記のグラフを1つに組み合わせることにしました。下部左側には選択したパラメータの散布図が表示され、上部右側には異なるサイズと色のバブルが表示されます。大きな円は、研究対象のパラメータ間により強い線形相関があることを意味します。行列の対角線には各特徴の分布が表示されます。ここでのピークが狭い場合、特定のパラメータがあまり変化しないことを示しますが、他の特徴は変化します。
この要約行列のビルドコードは以下の通りです。ここでは、マップはfig.map_lower、fig.map_diag、fig.map_upperの3つのパーツで構成されます:
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# データの読み込みdata = pd.read_csv('T1.csv')print(data)# 列名を短くするために列名を変更data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# 行列の構築def correlation_dots(*args, **kwargs): corr_r = args[0].corr(args[1], 'pearson') ax = plt.gca() ax.set_axis_off() marker_size = abs(corr_r) * 3000 ax.scatter([.5], [.5], marker_size, [corr_r], alpha=0.5, cmap = 'Blues', vmin = -1, vmax = 1, transform = ax.transAxes) font_size = abs(corr_r) * 40 + 5sns.set(style = 'white', font_scale = 1.6)fig = sns.PairGrid(data, aspect = 1.4, diag_sharey = False)fig.map_lower(sns.regplot)fig.map_diag(sns.histplot)fig.map_upper(correlation_dots)# 画像を保存plt.savefig('image3.jpg', dpi = 600, bbox_inches = 'tight')plt.show()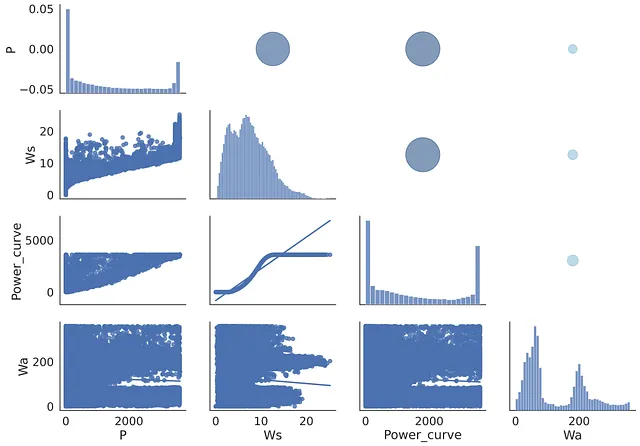
要約行列は、以前に研究された2つの図の利点を組み合わせています。下部(左側)は散布図行列を模倣し、上部(右側)は相関行列の数値結果をグラフで表示しています。
Tip 2: 可視化ライブラリの機能を最大限に活用する
時折、EDAの結果を同僚やクライアントにプレゼンする必要があるため、可視化はこのタスクで私の主要な助手です。私は常に矢印や注釈など、図にさまざまな要素を追加して、より魅力的で読みやすいものにしようとします。
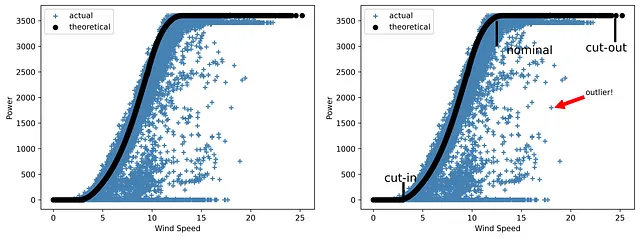
上記で議論した風力プロジェクトのEDA実装ケースに戻りましょう。風力エネルギーに関して、最も重要なパラメータの1つはパワーカーブです。風力タービン(または風力発電所)のパワーカーブは、さまざまな風速で生成される電力量を示すグラフです。低速風速ではタービンは動作しません。運転開始は通常2.5〜5 m/sの範囲にあります。12〜15 m/sの速度では定格電力に達します。最後に、各タービンには安全に動作できる風速の上限があります。このカットアウト速度の限界に達すると、風力タービンは速度が運転範囲に戻るまで電力を生成しません。
研究対象のデータセットには、理論的なパワーカーブ(製造業者による典型的なカーブで、外れ値はありません)と、風力と速度の関係をプロットした場合に得られる実際のカーブが含まれています。後者には通常、タービンの故障、不正確なSCADA測定、または予定外のメンテナンスなどによる理想的な理論的形状から外れた多数の点が含まれている可能性があります。
以下は、追加のアイテムを除いたパワーカーブの両方を表示する画像を作成します。まず、凡例を除いたものです:
import pandas as pd
import matplotlib.pyplot as plt
# データの読み込み
data = pd.read_csv('T1.csv')
print(data)
# 列名を短くするために列名を変更
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'}, inplace=True)
# プロットの作成
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='実測値')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='理論値')
plt.xlabel('風速')
plt.ylabel('パワー')
plt.legend(loc='best')
# 画像の保存
plt.savefig('image4.png', dpi=600, bbox_inches='tight')
plt.show()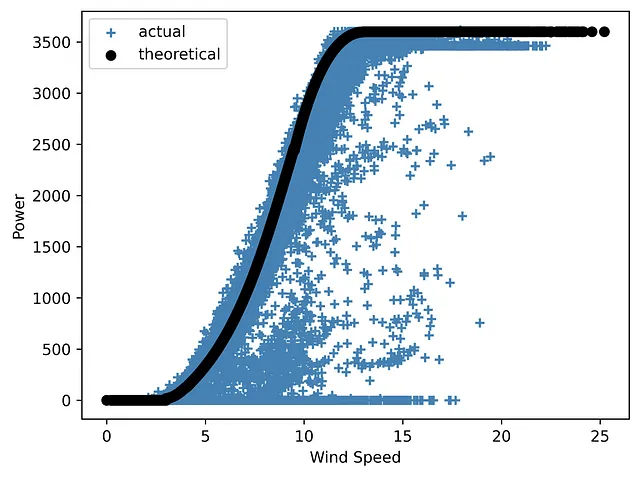
ご覧のように、グラフには追加の詳細が必要です。
しかし、カットイン、ノミナル、カットアウトの速度が示されたグラフの3つの主要な領域を強調するために線を追加し、外れ値を示す矢印付きのノートを追加した場合、グラフはどのようになるでしょうか。
この場合のグラフの見た目を確認しましょう:
import pandas as pd
import matplotlib.pyplot as plt
# データの読み込み
data = pd.read_csv('T1.csv')
print(data)
# 列名を短くするために列名を変更
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'}, inplace=True)
# プロットの作成
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='実測値')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='理論値')
# 垂直線、テキストノート、矢印を追加
plt.vlines(x=3.05, ymin=10, ymax=350, lw=3, color='black')
plt.text(1.1, 355, r"カットイン", fontsize=15)
plt.vlines(x=12.5, ymin=3000, ymax=3500, lw=3, color='black')
plt.text(13.5, 2850, r"ノミナル", fontsize=15)
plt.vlines(x=24.5, ymin=3080, ymax=3550, lw=3, color='black')
plt.text(21.5, 2900, r"カットアウト", fontsize=15)
plt.annotate('外れ値!', xy=(18.4,1805), xytext=(21.5,2050),
arrowprops={'color':'red'})
plt.xlabel('風速')
plt.ylabel('パワー')
plt.legend(loc='best')
# 画像の保存
plt.savefig('image4_2.png', dpi=600, bbox_inches='tight')
plt.show()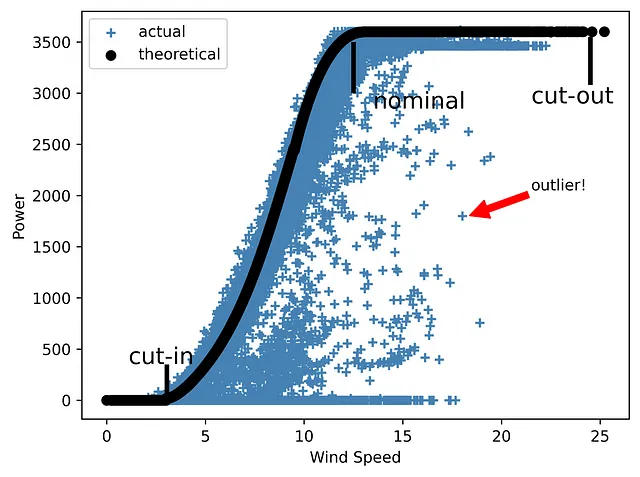
ヒント3: 同じ作業をより速く行う方法を常に見つける
風データを分析する際には、風エネルギーの潜在能力について包括的な情報を持つことがよくあります。そのため、風速が風向にどのように依存するかを示すグラフが必要です。
風力の変動を示すために、次のコードを使用できます:
import pandas as pd
import matplotlib.pyplot as plt
# データの読み込み
data = pd.read_csv('T1.csv')
print(data)
# 列名を短くするために列名を変更
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'}, inplace=True)
# 10分ごとのデータを1時間ごとの時間計測にリサンプリング
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
# 風力のダイナミクスをプロット
group_data.plot(kind='line')
plt.ylabel('パワー')
plt.xlabel('日付/時間')
plt.title('発電量(1時間ごとにリサンプリング)')
# 画像の保存
plt.savefig('wind_power.png', dpi=600, bbox_inches='tight')
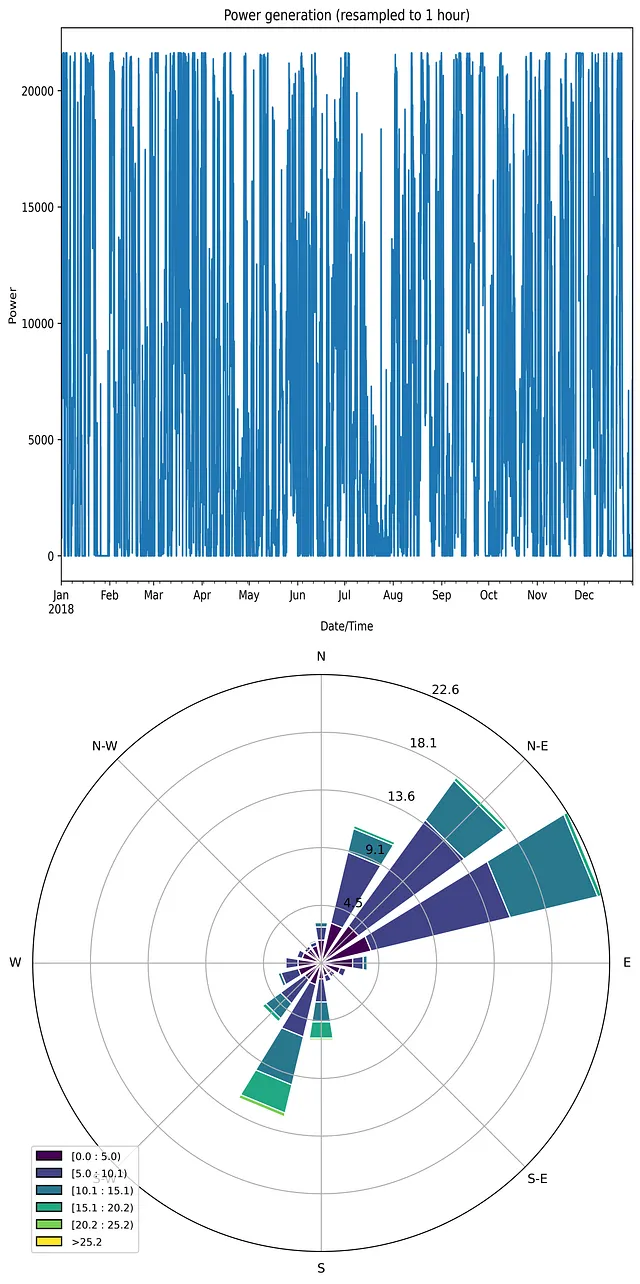
plt.show()以下は結果のプロットです:
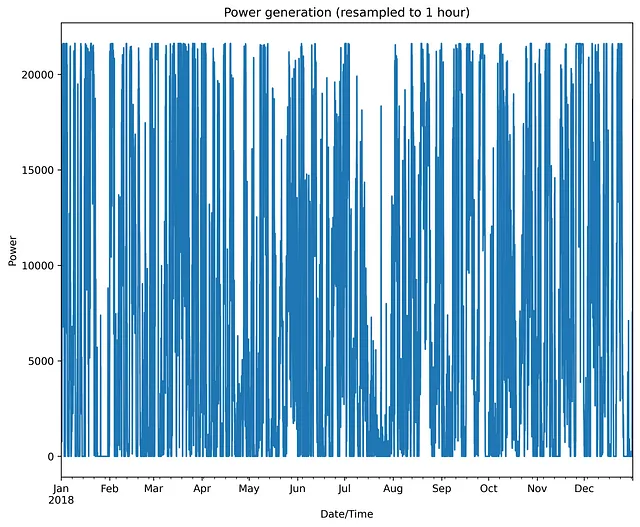
ご注意の通り、風力のダイナミクスのプロファイルは非常に複雑で不規則な形状をしています。
風薫図または極座標ローズプロットは、典型的に風速による風向の分布を表すための特別な図表です[3]。このような可視化を簡単に作成できるmatplotlibライブラリのwindroseモジュールがあります。以下のようなコードです:
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom windrose import WindroseAxes# データの読み込みdata = pd.read_csv('T1.csv')print(data)# タイトルを短くするために列名を変更data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)wd = data['Wa']ws = data['Ws']# 正規化された風薫図をスタックヒストグラムの形式でプロットax = WindroseAxes.from_ax()ax.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')ax.set_legend()# 図を保存plt.savefig('windrose.png', dpi = 600, bbox_inches = 'tight')plt.show()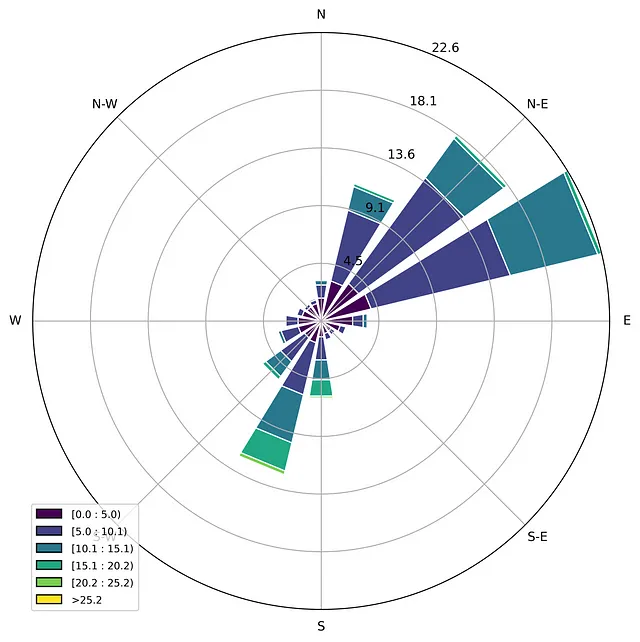
風薫図を見ると、主な風向きは北東と南西の2つであることがわかります。
しかし、これらの2つの画像を1つに結合するにはどうすればよいでしょうか?最も明らかなオプションはadd_subplotを使用することです。ただし、windroseライブラリの特殊性のため、これは直接的なタスクではありません:
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom windrose import WindroseAxes# データの読み込みdata = pd.read_csv('T1.csv')print(data)# タイトルを短くするために列名を変更data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)data['Date/Time'] = pd.to_datetime(data['Date/Time'])fig = plt.figure(figsize=(10,8))# 両方のプロットをサブプロットとしてプロットax1 = fig.add_subplot(211)group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()group_data.plot(kind='line')ax1.set_ylabel('Power')ax1.set_xlabel('Date/Time')ax1.set_title('Power generation (resampled to 1 hour)')ax2 = fig.add_subplot(212, projection='windrose')wd = data['Wa']ws = data['Ws']ax = WindroseAxes.from_ax()ax2.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')ax2.set_legend()# 図を保存plt.savefig('image5.png', dpi=600, bbox_inches='tight')plt.show()この場合、結果は以下のようになります:
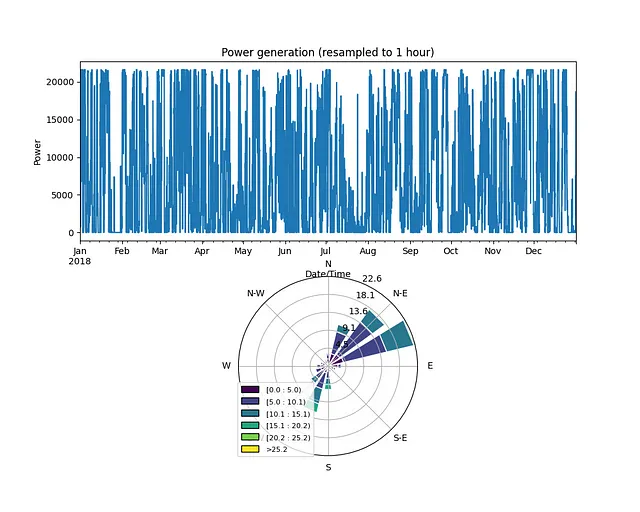
ここでの主な欠点は、2つのサブプロットのサイズが異なることであり、それによって風薫図の周りに多くの白い空白スペースが存在することです。
作業を簡単にするために、Python Imaging Library(PIL)[4]を使ってわずか11行のコードを使用することをお勧めします:
import numpy as np
import PIL
from PIL import Image
# マージする画像のリスト
list_im = ['wind_power.png', 'windrose.png']
imgs = [PIL.Image.open(i) for i in list_im]
# すべての画像を最小のサイズにリサイズ
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
images_comb = np.vstack((np.asarray(i.resize(min_shape)) for i in imgs))
images_comb = PIL.Image.fromarray(images_comb)
# 画像を保存
images_comb.save('image5_2.png', dpi=(600, 600))
ここでは、2つの画像が同じサイズであるため、出力が少し見栄えが良くなっています。コードは最小の画像を選び、他の画像をそのサイズに合わせてリスケールします。
ちなみに、PILを使用して水平方向にもスタッキングすることができます。例えば、’silent’(静止)と’talkative’(話し好き)なパワーカーブチャートを比較して対比してみましょう。
import numpy as np
import PIL
from PIL import Image
list_im = ['image4.png', 'image4_2.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 最小の画像を選び、他の画像をそのサイズに合わせる(任意の画像形状がここにある)
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.hstack((np.asarray(i.resize(min_shape)) for i in imgs))
# 美しい画像を保存
imgs_comb = PIL.Image.fromarray(imgs_comb)
imgs_comb.save('image4_merged.png', dpi=(600, 600))
結論
この記事では、EDAプロセスをより簡単にするための3つのヒントを共有しました。これらのアドバイスが自分自身にとって有益であり、データのタスクにも適用し始めることを願っています。
これらのヒントは、常にEDAを行う際に適用しようとする公式に完全に一致しています:カスタマイズ → 項目化 → 最適化。
では、なぜこれが重要なのかというと、実際には重要なのです:
- 現在直面している特定のニーズに合わせてチャートをカスタマイズすることが非常に重要です。例えば、多くのインフォグラフィックを作成する代わりに、サマリーマトリックスのように複数のインフォグラフィックを1つに組み合わせる方法を考えます。このマトリックスは、散布図と相関チャートの両方の強みを組み合わせています。
- すべてのチャートはそれ自体で語るべきです。したがって、チャート上の重要な要素を項目化して詳細かつ読みやすいものにする方法を知る必要があります。’silent’(静止)と’talkative’(話し好き)なパワーカーブの違いがどれだけ大きいかを比較してみてください。
- そして最後に、すべてのデータスペシャリストは、EDAプロセスを最適化する方法を学ぶべきです(そして生活をより簡単にするために)。2つの画像を1つにマージする必要がある場合、必ずしも
add_subplotオプションを常に使用する必要はありません。
他に何かありますか?EDAは、データを扱う際の非常に創造的で興味深いステップです(そして非常に重要であることは言うまでもありません)。
インフォグラフィックをダイヤモンドのように輝かせ、プロセスを楽しむことを忘れないでください!
参考文献リスト
- Paper “Data-driven applications for wind energy analysis and prediction: The case of”La Haute Borne” wind farm”. https://doi.org/10.1016/j.dche.2022.100048
- Wind Power Generated Data: https://www.kaggle.com/datasets/bhavikjikadara/wind-power-generated-data?resource=download
- Tutorial about a windrose library: https://windrose.readthedocs.io/en/latest/index.html
- PIL library: https://pillow.readthedocs.io/en/stable/index.html
読んでくれてありがとう!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ConDistFLとの出会い:CTデータセットにおける臓器と疾患のセグメンテーションのための革新的なフェデレーテッドラーニング手法」
- 「PUGに会ってください:メタAIによるアンリアルエンジンを使用したフォトリアルで意味的に制御可能なデータセットを用いた堅牢なモデル評価に関する新しいAI研究」
- USCとMicrosoftの研究者は、UniversalNERを提案します:ターゲット指向の蒸留で訓練され、13,000以上のエンティティタイプを認識し、43のデータセット上でChatGPTのNER精度を9%F1上回る新しいAIモデルです
- インフォグラフィックスでデータ可視化をどのように使用するか?
- 「データの可視化を改善するための4つの必須リソース」
- 高パフォーマンスなリアルタイムデータモデルの構築ガイド
- 「データサイエンスは難しいのか?現実を知ろう」
