「Transformerモデルの実践的な導入 BERT」
Practical Introduction to Transformer Model BERT
ハンズオンチュートリアル
BERTを使用して最初の感情分析モデルを構築するためのハンズオンチュートリアル
前書き: この記事は、指定されたトピックに関する情報の要約を提供します。オリジナルの研究とはみなされません。この記事に含まれる情報とコードは、過去のさまざまなオンライン記事、研究論文、書籍、オープンソースのコードから読んだり見たりしたものに影響を受けている可能性があります。
目次
- BERTの紹介
- 事前学習と微調整
- ハンズオン: BERTを使用した感情分析
- 結果の解釈
- まとめ
NLPでは、Transformerモデルのアーキテクチャは、テキスト情報の理解と生成能力を大幅に向上させる革新的なものでした。
このチュートリアルでは、よく知られたTransformerベースのモデルであるBERTについて詳しく説明し、ベースのBERTモデルを感情分析のために微調整する手順を実演します。
BERTの紹介
BERTは、Googleの研究者によって2018年に発表されたパワフルな言語モデルで、Transformerアーキテクチャを使用しています。LSTMやGRUなど、過去に存在したモデルアーキテクチャの枠組みを超えるもので、過去と未来の両方の文脈を同時に考慮しています。これは、”attention mechanism(注意機構)”によるもので、モデルが生成する表現において文中の単語の重要性を考慮することができます。
- 「Text2Cinemagraphによるダイナミックな画像の力を探索:テキストプロンプトからシネマグラフを生成するための革新的なAIツール」
- 「生成型AIアプリケーションにおける効果的なプロンプトエンジニアリング原則」
- 「Underrepresented Groupsの存在下での学習について」
BERTモデルは、次の2つのNLPタスクで事前学習されます:
- Masked Language Model(MLM)
- Next Sentence Prediction(NSP)
そして、感情分析などのさまざまな下流のNLPタスクでベースモデルとして使用されます(このチュートリアルでカバーします)。
事前学習と微調整
BERTの強力さは、2つのステップから成るプロセスに由来しています:
- 事前学習は、BERTが大量のデータで訓練されるフェーズです。その結果、文内のマスクされた単語(MLMタスク)を予測し、文が別の文に続くかどうかを予測することを学習します(NSPタスク)。このステージの出力は、言語の一般的な「理解」を持つ事前学習済みのNLPモデルです。
- 微調整は、事前学習済みBERTモデルを特定のタスクにさらに訓練する段階です。モデルは事前学習されたパラメータで初期化され、全体のモデルが下流のタスクで訓練されます。これにより、BERTは言語の理解を特定のタスクの具体的な要件に合わせて微調整することができます。
ハンズオン: BERTを使用した感情分析
完全なコードはGitHubのJupyter Notebookとして利用できます
このハンズオン演習では、IMDB映画のレビューデータセット[4](ライセンス: Apache 2.0)で感情分析モデルを訓練します。このデータセットでは、レビューがポジティブかネガティブかがラベル付けされています。また、Hugging Faceのtransformersライブラリを使用してモデルを読み込みます。
まず、すべてのライブラリを読み込みましょう
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matrix, roc_curve, aucfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer# エポック数とサンプル数を設定するnum_epochs = 10num_samples = 100 # すべてのデータを使用する場合は、-1に設定しますまず、データセットとモデルのトークナイザを読み込みます。
# ステップ1: データセットとモデルのトークナイザを読み込むdataset = load_dataset('imdb')tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')次に、ポジティブクラスとネガティブクラスの分布を可視化するプロットを作成します。
# データの探索train_df = pd.DataFrame(dataset["train"])sns.countplot(x='label', data=train_df)plt.title('クラスの分布')plt.show()
次に、テキストをトークン化してデータセットを前処理します。BERTのトークナイザーを使用し、テキストをBERTの語彙に対応するトークンに変換します。
# ステップ2: データセットの前処理def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
その後、トレーニングデータセットと評価データセットを準備します。すべてのデータを使用したい場合は、num_samples変数を-1に設定できます。
if num_samples == -1: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42)else: small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(num_samples)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(num_samples)) 次に、事前学習済みのBERTモデルを読み込みます。分類タスクに適したBERTモデルであるAutoModelForSequenceClassificationクラスを使用します。
このチュートリアルでは、小文字の英語テキストで学習された「bert-base-uncased」バージョンのBERTを使用します。
# ステップ3: 事前学習済みモデルの読み込みmodel = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)さて、トレーニングの引数を定義し、モデルをトレーニングするためのTrainerインスタンスを作成する準備が整いました。
# ステップ4: トレーニングの引数を定義training_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epochs)# ステップ5: Trainerのインスタンスを作成してモデルをトレーニングするtrainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset)trainer.train()結果の解釈
モデルをトレーニングした後、評価します。混同行列とROC曲線を計算して、モデルの性能を把握します。
# ステップ6: 評価predictions = trainer.predict(small_eval_dataset)# 混同行列cm = confusion_matrix(small_eval_dataset['label'], predictions.predictions.argmax(-1))sns.heatmap(cm, annot=True, fmt='d')plt.title('Confusion Matrix')plt.show()# ROC曲線fpr, tpr, _ = roc_curve(small_eval_dataset['label'], predictions.predictions[:, 1])roc_auc = auc(fpr, tpr)plt.figure(figsize=(1.618 * 5, 5))plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver operating characteristic')plt.legend(loc="lower right")plt.show()
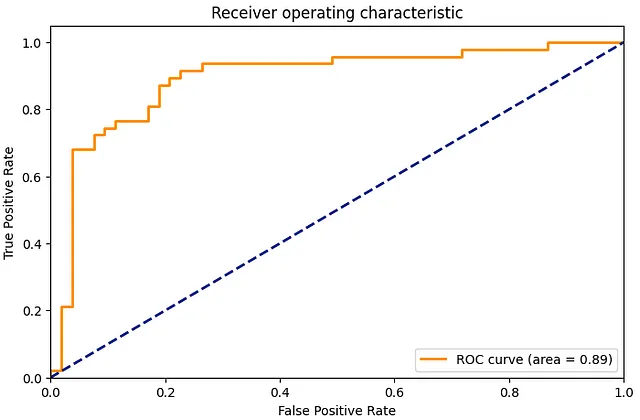
混同行列は、予測結果が実際のラベルとどのように一致するかを詳細に分析します。一方、ROC曲線は、異なる閾値設定における真陽性率(感度)と偽陽性率(1−特異度)のトレードオフを示しています。
最後に、モデルを実際に使用してサンプルテキストの感情を推論してみましょう。
# ステップ7:新しいサンプルに対する推論
sample_text = "これは素晴らしい映画です。私は本当に楽しんでいます。"
sample_inputs = tokenizer(sample_text, padding="max_length", truncation=True, max_length=512, return_tensors="pt")
# 入力をデバイスに移動する(GPUが利用可能な場合)
sample_inputs.to(training_args.device)
# 予測を行う
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print("ポジティブな感情")
else:
print("ネガティブな感情")
まとめ
IMDbの映画レビューの感情分析の例を通じて、BERTを実際のNLP問題に適用する方法を明確に理解していただけたことを願っています。ここで示したPythonコードは、異なるタスクやデータセットに対応するために調整や拡張が可能であり、より洗練された正確な言語モデルの実現に役立ちます。
参考文献
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).
[3] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., … & Rush, A. M. (2019). Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[4] Lhoest, Q., Villanova del Moral, A., Jernite, Y., Thakur, A., von Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., Davison, J., Šaško, M., Chhablani, G., Malik, B., Brandeis, S., Le Scao, T., Sanh, V., Xu, C., Patry, N., McMillan-Major, A., Schmid, P., Gugger, S., Delangue, C., Matussière, T., Debut, L., Bekman, S., Cistac, P., Goehringer, T., Mustar, V., Lagunas, F., Rush, A., & Wolf, T. (2021). Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 175–184). Online and Punta Cana, Dominican Republic: Association for Computational Linguistics. Retrieved from https://aclanthology.org/2021.emnlp-demo.21
お読みいただきありがとうございます。ご意見やフィードバックがありましたら、コメント、LinkedInでのメッセージ、またはメール(smhkapadia[at]gmail.com)でお気軽にお問い合わせください。
この記事がお役に立ちましたら、ぜひ他の記事もご覧ください。
ドメイン適応:事前学習済みNLPモデルの微調整
どのドメインでも事前学習済みNLPモデルの微調整のステップバイステップガイド
towardsdatascience.com
自然言語処理の進化
言語モデルの開発の歴史的な視点
VoAGI.com
Pythonにおけるレコメンデーションシステム:LightFM
LightFMを使用してPythonでレコメンデーションシステムを構築するステップバイステップガイド
towardsdatascience.com
トピックモデルの評価:潜在ディリクレ配分(LDA)
解釈可能なトピックモデルの構築に向けたステップバイステップガイド
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- アリババのChatGPTの競合相手、統一千文と出会ってください:その大規模言語モデルは、Tmall Genieスマートスピーカーや職場メッセージングプラットフォームのDingTalkに組み込まれる予定です
- 「ニューラルネットワークとディープラーニング:教科書(第2版)」
- 「FalconAI、LangChain、およびChainlitを使用してチャットボットを作成する」
- スタンフォード大学とGoogleからのこのAI論文は、生成エージェントを紹介しています生成エージェントは、人間の振る舞いをシミュレートするインタラクティブな計算エージェントです
- 「SegGPT」にお会いください:コンテキスト推論を通じて画像または動画の任意のセグメンテーションタスクを実行する汎用モデル
- 「識別可能であるが可視性がない:プライバシー保護に配慮した人物再識別スキーム(論文要約)」
- 「トップAIコンテンツ生成ツール(2023年)」





