「LLMsの実践的な導入」
Practical Implementation of LLMs
実践でのLLMの3つのレベル
これは、実践でのLarge Language Models (LLMs)の使用に関するシリーズの最初の記事です。ここでは、LLMsの概要と、それらとの作業の3つのレベルを紹介します。将来の記事では、OpenAIのパブリックAPIの使用方法、Hugging Face Transformers Pythonライブラリの使用方法、LLMsのファインチューニング方法、LLMのゼロからの構築方法など、LLMsの実践的な側面を探求します。
LLMとは何ですか?
LLMは、Large Language Modelの略で、AIと機械学習の最新のイノベーションです。この強力な新しいタイプのAIは、ChatGPTのリリースにより2022年12月に急速に普及しました。
AIのバズやテックニュースのサイクルから外れた世界で生活する人々にとっては、ChatGPTはGPT-3というLLMで動作するチャットインタフェースです(現在はGPT-3.5またはGPT-4にアップグレードされています)。
ChatGPTを使用したことがある場合、これがAOLインスタントメッセンジャーやクレジットカードのカスタマーケアのような従来のチャットボットではないことは明らかです。
これは違う感じがします。
LLMを「大きい」とする要素は何ですか?
「Large Language Model」という用語を聞いたとき、最初の質問の1つは、「通常の」言語モデルとはどう違うのかということでした。
言語モデルは、大きな言語モデルよりも一般的です。正方形はすべて長方形ですが、すべての長方形が正方形ではありません。すべてのLLMは言語モデルですが、すべての言語モデルがLLMではありません。
では、LLMを特別なものにするのは何でしょうか?
LLMを他の言語モデルと区別する2つの主要な特徴があります。1つは数量的な特徴であり、もう1つは質的な特徴です。
- 数量的に、LLMを特徴づけるのは、モデルで使用されるパラメータの数です。現在のLLMは1000億から1兆のパラメータを持っています[1]。
- 質的に、言語モデルが「大きい」場合、注目すべき特性であるエマージェントな特性が現れます。例えば、ゼロショット学習などがあります。これらは、言語モデルが十分に大きなサイズに達したときに突然現れる特性です。
ゼロショット学習
GPT-3(および他のLLM)の主要なイノベーションは、さまざまなコンテキストでゼロショット学習が可能であることです[2]。これは、ChatGPTが明示的にトレーニングされていなくてもタスクを実行できることを意味します。
高度に進化した人間にとっては、これは大したことではないかもしれませんが、このゼロショット学習の能力は、以前の機械学習のパラダイムとは鮮明に対照的です。
以前は、モデルは明示的にトレーニングを受ける必要がありました。例えば、言語翻訳、感情分析、文法エラーの識別などのタスクをコンピュータに実行させたい場合、それぞれのタスクには大量のラベル付きのトレーニング例が必要でした。しかし、今ではLLMsは明示的なトレーニングなしでこれらのことをすべて行うことができます。
LLMはどのように動作しますか?
ほとんどの最新のLLMを訓練するためのコアタスクは単語予測です。言い換えれば、ある単語のシーケンスが与えられた場合、次の単語の確率分布はどうなるのかを求めるということです。
たとえば、「Listen to your ____」というシーケンスが与えられた場合、最もありそうな次の単語は、heart, gut, body, parents, grandmaなどです。これは以下に示す確率分布のようになるかもしれません。
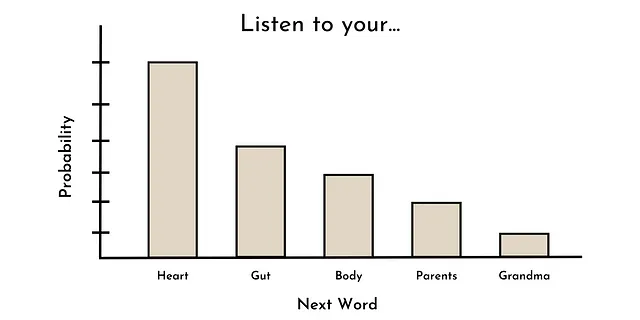
興味深いことに、これは過去に多くの(大規模でない)言語モデルが訓練された方法と同じです(例:GPT-1)[3]。しかし、なぜか、言語モデルがある程度のサイズ(約10Bのパラメータ)を超えると、ゼロショット学習などの(新たに現れる)能力が現れるようになる[1]。
なぜこれが起こるのかには明確な答えはない(現時点では推測の域を出ない)が、LLMは無数の潜在的な用途を持つ強力な技術であることは明らかです。
LLMsの使用の3つのレベル
ここでは、この強力な技術を実践でどのように使用するかについて説明します。無数のLLMの使用例がありますが、ここでは必要な技術的知識と計算リソースによって順に分類します。まずは最もアクセスしやすい方法から始めましょう。
レベル1:プロンプトエンジニアリング
実践でLLMを使用する最初のレベルはプロンプトエンジニアリングです。これはLLMをそのまま使用することを指します。つまり、モデルのパラメータを変更せずに使用することです。技術的に傾向がある人々はプロンプトエンジニアリングの考えに冷笑するようですが、これは実践的にLLMを使用する最もアクセスしやすい方法です(技術的、経済的にも)。
プロンプトエンジニアリングを行う方法は2つあります。簡単な方法と少し難しい方法です。
簡単な方法:ChatGPT(または他の便利なLLM UI)— この方法の利点は便利さです。ChatGPTのようなツールは直感的で無償かつノーコードでLLMを使用する方法を提供します(これ以上簡単な方法はありません)。
ただし、便利さにはコストがかかることがしばしばあります。この場合、このアプローチの2つの主な欠点があります。1つ目は機能の不足です。たとえば、ChatGPTはユーザーがモデルの入力パラメータ(例:温度や最大応答長)をカスタマイズすることを容易にはできません。これらはLLMの出力を調整する値です。2つ目は、ChatGPT UIとの対話を容易に自動化して大規模なユースケースに適用することができないことです。
これらの欠点は一部のユースケースにとって取引の不利な条件となるかもしれませんが、プロンプトエンジニアリングをさらに進めればこれらを解消することができます。
少し難しい方法:LLMと直接対話する— ChatGPTの欠点の一部をプログラム的なインタフェースを介して直接LLMと対話することで克服することができます。これは公開API(例:OpenAIのAPI)を介したり、Transformersなどのライブラリを使用してLLMをローカルで実行したりすることができます。
この方法ではプロンプトエンジニアリングは簡単ではありません(プログラミングの知識とAPIのコストが必要です)が、実践的にLLMを使用するためのカスタマイズ可能で柔軟な方法を提供します。このシリーズの次の記事では、このタイプのプロンプトエンジニアリングを行うための有料および無料の方法について説明します。
ここで定義したプロンプトエンジニアリングはほとんどのLLMの応用に対応できますが、特定のユースケースにおいては汎用モデルに頼ることで最適なパフォーマンスが得られない場合もあります。そのような場合には、次のレベルのLLMの使用方法に進むことができます。
レベル2:モデルの微調整
LLMの2番目のレベルはモデルの微調整です。これは、既存のLLMを取り、少なくとも1つの(内部の)モデルパラメータ(重みやバイアス)を変更して特定のユースケースに合わせて調整することを指します。このカテゴリには、転移学習(別のモデルを開発するために既存のLLMの一部を使用すること)も含まれます。
ファインチューニングは通常2つのステップで構成されます。 ステップ1:事前学習済みLLMの取得。 ステップ2:(通常数千もの)高品質なラベル付きの例が与えられた特定のタスクのためにモデルパラメータを更新します。
モデルパラメータは、LLMの入力テキストの内部表現を定義するものです。したがって、特定のタスクのためにこれらのパラメータを微調整することで、内部表現がファインチューニングタスクに最適化されます(少なくともそのようなアイデアです)。
これは、比較的少数の例と計算リソースで優れたモデルのパフォーマンスを生み出すための強力なアプローチです。
ただし、デメリットとして、プロンプトエンジニアリングよりもはるかに高度な技術力と計算リソースが必要です。将来の記事では、ファインチューニングの技術とPythonコードの例を紹介することで、このデメリットを軽減しようと試みます。
プロンプトエンジニアリングとモデルのファインチューニングは、おそらくLLMアプリケーションの99%をカバーできるでしょうが、さらに進む必要があるケースもあります。
レベル3:独自のLLMを構築する
LLMを実践的に使用するための第3の方法は、独自のLLMを構築することです。モデルパラメータの観点では、ここですべてのモデルパラメータをゼロから考え出します。
LLMは主にそのトレーニングデータの産物です。したがって、一部のアプリケーションでは、モデルトレーニングのためにカスタムの高品質テキストコーパスを作成する必要があるかもしれません。たとえば、臨床アプリケーションの開発のための医療研究コーパスなどです。
このアプローチの最大の利点は、特定のユースケースに完全にカスタマイズできるということです。これは究極の柔軟性です。ただし、通常の場合と同様に、柔軟性には利便性のコストがかかります。
LLMのパフォーマンスの鍵はスケールですので、ゼロからLLMを構築するには膨大な計算リソースと技術力が必要です。言い換えれば、これは週末の個人プロジェクトではなく、7-8Fの予算で数か月、もしくは数年をかけたチームの作業になるでしょう。
それにもかかわらず、このシリーズの将来の記事では、ゼロからLLMを開発するための人気のある技術について探求します。
結論
最近のLLMについて十分なほどのハイプがありますが、それらはAIの分野での強力なイノベーションです。ここでは、LLMとは何かを初めに説明し、実践的にどのように使用できるかをフレームワークとして提供しました。このシリーズの次の記事では、OpenAIのPython APIの初心者ガイドを紹介し、次のLLMユースケースをスタートさせるのに役立ちます。
リソース
連絡先:私のウェブサイト | 電話の予約 | 何でも聞いてください
ソーシャルメディア:YouTube 🎥 | LinkedIn | Twitter
サポート:メンバーになる ⭐️ | コーヒーを買ってください ☕️
データ起業家
データ領域の起業家のためのコミュニティ。👉 Discordに参加してください!
VoAGI.com
[1] Survey of Large Language Models. arXiv:2303.18223 [cs.CL]
[2] GPT-3 Paper. arXiv:2005.14165 [cs.CL]
[3] Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training. (GPT-1 Paper)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
