「機械学習における特徴エンジニアリングへの実践的なアプローチ」
Practical Approach to Feature Engineering in Machine Learning

フィーチャー学習は、機械学習の重要な要素ですが、しばしばあまり話題にされず、多くのガイドやブログ記事はMLライフサイクルの後半に焦点を当てています。このサポートステップによって、機械学習モデルはより正確かつ効率的になり、生データを具体的で使いやすい形に変換することができます。これがなければ、完全に最適化されたモデルを構築することは不可能です。
この記事では、機械学習におけるフィーチャー学習の仕組みと、簡単で実践的な手順での実装方法について説明します。さらに、MLのいくつかの欠点についても議論し、この重要なプロセスの包括的な概要を提供します。
- 機械学習(ML)の実験トラッキングと管理のためのトップツール(2023年)
- Google AIは、アーキテクチャシミュレータにさまざまな種類の検索アルゴリズムを接続するための、マシンラーニングのためのオープンソースのジム「ArchGym」を紹介しました
- 「生成型AIとMLOps:効率的で効果的なAI開発のための強力な組み合わせ」
フィーチャーエンジニアリングとは何ですか?
フィーチャーエンジニアリングは、データセットを処理し、特定のタスクに関連する使用可能な数値セットに変換する重要な機械学習(ML)の技術です。
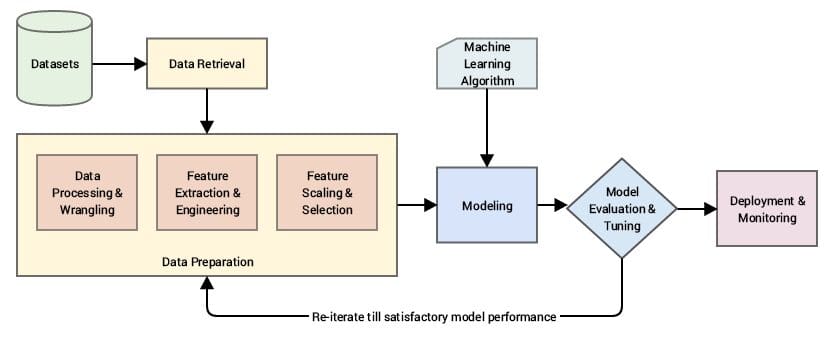
フィーチャーとは、データセット内の列として現れる分析されるデータ要素です。これらのデータ要素を修正、ソート、正規化することにより、モデルをより最適なパフォーマンスにすることができます。フィーチャー学習は、これらのデータ要素を変更して関連性を持たせ、より正確なモデルを作成し、使用される変数が少ないため、より迅速な応答時間を実現します。
フィーチャーエンジニアリングのプロセスは以下のように分解できます:
- データの問題点(不完全なフィールド、不整合、その他の異常など)を修正するための分析が行われます。
- モデルの動作に関連性のない変数は削除されます。
- 重複するデータは破棄されます。
- レコードを相関させ、正規化します。
なぜフィーチャーエンジニアリングは機械学習において非常に重要ですか?
フィーチャーエンジニアリングがなければ、機能を正確に実行できる予測モデルを設計することはできません。フィーチャー学習はまた、必要な時間と計算リソースを削減し、モデルをより効率的にします。
データのフィーチャーは、予測モデルがどのように動作するかを決定し、各モデルを訓練して望ましい結果を得るのに役立ちます。これは、特定の機能に完全に適用できないデータでも適切な結果を得るために変更できることを意味します。フィーチャー学習はまた、後のデータ分析に費やす時間を大幅に削減します。
フィーチャーエンジニアリング:メリットとデメリット
フィーチャー学習は重要ですが、明らかなメリットに加えていくつかの制限もあります。以下にリストされています。
フィーチャーエンジニアリング:メリット
- エンジニアリングされたフィーチャーを持つモデルは、より高速なデータ処理が可能です。
- モデルが簡素化され、より簡単にメンテナンスできます。
- 予測と推定がより正確になります。
フィーチャーエンジニアリング:デメリット
- フィーチャーエンジニアリングは時間のかかるプロセスです。
- 効果的なフィーチャーリストを構築するには、深い分析が必要です。これには、データセット、モデルの処理動作、およびビジネスコンテキストの徹底的な理解が含まれます。
機械学習におけるフィーチャーエンジニアリングの実践的な手法:6つのステップ
フィーチャーリングの可能性と制約についての理解を深めたので、以下の6つの主要なステップでのプロセスについて考えてみましょう。
#1 データの準備
フィーチャーエンジニアリングのプロセスの最初のステップは、さまざまなソースから収集された生データを使用可能な形式に変換することです。使用可能なML形式には、.csc、.tfrecords、.json、.xml、および.avroがあります。データの準備には、クレンジング、統合、取り込み、およびロードなどの一連のプロセスが必要です。
#2 データの分析
分析段階、または探索段階とも呼ばれるこのステージでは、データセットから洞察と記述統計情報が取得され、データをより理解するために可視化されます。その後、相関する変数とその特性を特定し、クリーニングされます。
#3 改善
データの分析とクレンジングが完了したら、欠損値の追加、正規化、変換、スケーリングなどによってデータを改善する時です。データはまた、カテゴリカルデータを表す質的/ 離散変数であるダミー値を追加することでさらに変更することもできます。
#4 構築
特徴は手動またはアルゴリズム(たとえばtSNEやPrincipal Component Analysis(PCA)など)を使用して手動または自動で構築することができます。特徴構築にはほぼ無限のオプションがありますが、解決策は常に問題に依存します。
#5 選択
特徴/変数/属性の選択は、モデルが予測する変数に最も関連性のあるもののみを選択することで、入力変数(特徴列)の数を減らします。これにより、より高速な処理速度と計算リソースの使用量の削減が可能となります。
特徴選択の技術には以下のものがあります:
- 関係のない特徴を削除するフィルター。
- 複数の特徴を使用するためにMLモデルをトレーニングするラッパー。
- フィルターとラッパーを組み合わせたハイブリッドモデル。
たとえば、フィルターベースの手法は、特徴が目標変数と十分に相関しているかどうかを統計的なテストによって判断します。
#6 評価と検証
評価プロセスは、選択された特徴を使用してトレーニングデータのモデルの精度を決定します。精度レベルが必要な基準を満たしている場合、モデルは検証されます。そうでない場合は、特徴選択の段階を繰り返す必要があります。
特徴エンジニアリングのユースケース
では、機械学習における特徴エンジニアリングの3つの一般的なユースケースを見てみましょう。
同じデータセットからの追加の洞察
多くのデータセットには、日付、年齢などの任意の値が含まれており、これらを異なる形式に変換して特定の情報を提供することができます。たとえば、日付と期間の詳細をクロス参照することで、ユーザーの行動(ウェブサイトの訪問頻度や滞在時間など)を判断することができます。
予測モデル
正しい特徴の選択は、さまざまな産業に対して予測モデルを構築するのに役立ちます。公共交通機関など、特定の日にどれくらいの乗客がサービスを利用するかを判断するのに役立つ産業もあります。
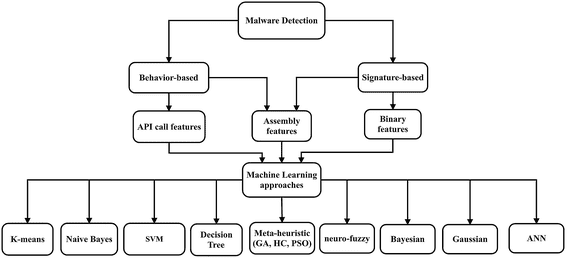
マルウェア検出
マニュアルによるマルウェア検出は非常に困難であり、ほとんどのニューラルネットワークもこの点で問題を抱えています。しかし、特徴エンジニアリングはマニュアル技術とニューラルネットワークを組み合わせて異常な振る舞いを強調することができます。
機械学習における特徴エンジニアリングの結論
特徴エンジニアリングは、機械学習モデルを構築する際の重要な段階であり、この段階を正しく行うことで、MLモデルの精度が向上し、計算リソースの使用量が減少し、処理速度が向上することができます。
特徴エンジニアリングプロセスは、初期データの準備から検証までの6つの段階に分けることができます。特定のタスクに対して最も関連性のあるデータ要素のみを選択します。 Nahla Daviesはソフトウェア開発者兼テックライターです。テクニカルライティングに専念する前に、サムスン、タイム・ワーナー、Netflix、ソニーなどのクライアントを含むInc. 5,000の体験ブランド機関でリードプログラマーとして勤務していました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






