Mageを使用してデータパイプラインでの振る舞い駆動開発を実装してください
Please implement behavior-driven development in a data pipeline using Mage.
データパイプラインの品質と生産性を最大化する
前回の記事では、データパイプラインにおけるテストの重要性と、データテストとユニットテストの作成方法について多くの話をしました。テストは重要な役割を果たしますが、開発サイクルの中で常に最もエキサイティングな部分ではありません。そのため、多くの現代的なデータスタックでは、データテストの実装を迅速化するためのフレームワークやプラグインが導入されています。また、Pytest、unittestなどのPythonのユニットテストフレームワークは長い間存在しており、エンジニアがデータパイプラインやPythonアプリケーションのユニットテストを効率的に作成するのに役立ってきました。
この記事では、2つのモダンな技術、ビヘイビア駆動開発(BDD)とMage(モダンなデータパイプラインツール)を組み合わせたセットアップを紹介したいと思います。これら2つの技術を組み合わせることで、シームレスな開発者体験を提供しながら、データパイプラインの高品質なユニットテストを作成することを目指します。
ビヘイビア駆動開発(BDD)とは何ですか?
ビジネス向けのデータパイプラインを構築する際には、複雑でトリッキーなビジネスロジックに遭遇する可能性が高いです。例えば、年齢、所得、過去の購入に基づいて顧客セグメンテーションを定義することがあります。以下の例は、ビジネスロジックが持つ複雑さの一部にすぎません。各属性内の属性と粒度が増えるにつれて、ますます複雑になる可能性があります。日常の仕事での例を考えてみてください!
1. 19歳から60歳までの人々で、過去の購入が多い場合は「プレミアム」です。2. 19歳から60歳までの人々で、所得が高い場合は「プレミアム」です。3. 60歳以上で、所得が高く、過去の購入が多い場合は「プレミアム」です。4. それ以外の場合は「ベーシック」です。では、ビジネスルールはどこに文書化すべきであり、文書とコードの同期をどのように保証すればよいのでしょうか。一般的なアプローチの1つは、コードと一緒にコメントを含めることです。または、自己説明的で理解しやすいコードを書くことを目指します。しかし、古くなったコメントやステークホルダーが理解するのが難しいコードのリスクが依然として存在します。
- 企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
- トップ7の列操作でより効果的にPandasデータフレームを使用する
- Taipy:ユーザーフレンドリーな本番用データサイエンティストアプリケーションを構築するためのツール
最終的に求めているのは、「ドキュメントとしてのコード」の解決策であり、エンジニアとビジネスステークホルダーの両方に利益をもたらすものです。これがBDDが提供できるものです。もしあなたが「データコントラクト」の概念に詳しい場合、BDDはデータソースではなくステークホルダーを重視したデータコントラクトの一形態と見なすことができます。特に複雑なビジネスロジックを持つデータパイプラインには非常に有益であり、「機能またはバグ」という議論を防ぐのに役立ちます。
BDDは、ソフトウェアが望ましいビジネスの成果を達成することを保証するために、ステークホルダーと開発者間の協力とコミュニケーションを重視するソフトウェア開発のアプローチです。行動は、期待される入力と出力を示すシナリオで説明されます。各シナリオは、「Given-When-Then」という特定の形式で記述され、各ステップが特定の条件やアクションを説明します。
顧客セグメンテーションの例でシナリオがどのように見えるか見てみましょう。フィーチャーファイルは英語で書かれているため、ビジネスステークホルダーによって理解され、彼らはそれに貢献することさえできます。エンジニアとステークホルダーの間の契約のようなものであり、エンジニアは要件を正確に実装する責任があり、ステークホルダーはすべての必要な情報を提供することが期待されています。
ステークホルダーとエンジニアの間に明確な契約があることにより、実装エラーによる「ソフトウェアのバグ」と、要件の不足による「機能要求」を正しく分類することができます。
フィーチャーファイル(著者作成)
次のステップは、フィーチャーからテストコードを生成することで、そこで接続が行われます。Pytestコードは、ドキュメントと実装コードの間の橋渡しとなります。それらの間に不整合がある場合、テストは失敗し、ドキュメントと実装の同期の必要性が示されます。

以下はテストコードの例です。例を短く保つため、最初のシナリオのテストコードのみを実装します。Givenステップでは、この場合、顧客の年齢、所得、過去の購入データを例から取得し、シナリオの期待される出力とWhenステップの結果を比較します。
機能ファイルの1番目のシナリオのテストコード(作者作成)
コードを更新せずに最初のシナリオで指定された年齢範囲の変更を想像してみてください。その場合、コードに矛盾する期待値があるため、テストはすぐに失敗します。
Mageとは何ですか?
これまでにBDDの可能性を見てきて、Pythonを使用して実装する方法を学びました。さて、BDDをデータパイプラインに取り入れる時間です。データオーケストレーションに関しては、Pythonベースの最初のオーケストレータであるAirflowが、データパイプラインの実行に最も一般的に使用されるツールとなりました。
しかし、完璧ではありません。たとえば、KubernetesOperatorなどのオペレータを使用する場合、プロダクション環境外でパイプラインをテストすることは困難です。さらに、DAGはボイラープレートコードや複雑な設定で混雑し、各タスクの目的(インジェクション、変換、エクスポートなど)を明確にするのがより直感的ではありません。さらに、Airflowは最終データアセットの品質よりもタスクの成功した実行に関心があり、データ駆動型のオーケストレーションツールには焦点を当てていません。
データエンジニアリングコミュニティが成長するにつれ、Airflowの欠点を補うために多くのAirflowの代替ツールが登場しました。Mageは、Airflowの現代的な置き換えと見なされる成長しているデータパイプラインツールの1つです。Mageの4つの設計コンセプトにより、開発サイクルの始まりから違いを感じることができます。

Mageには、エンジニアがパイプラインを迅速に編集およびテストできる非常に直感的なUIがあります。
各パイプラインは、@data_loader、@transformer、@data_exporterなどの複数のタイプのブロックで構成されており、明確な目的があります。これは私のお気に入りの機能の1つです。各タスクの目的がすぐに理解できるため、ボイラープレートコードに巻き込まれるのではなく、ビジネスロジックに集中できます。
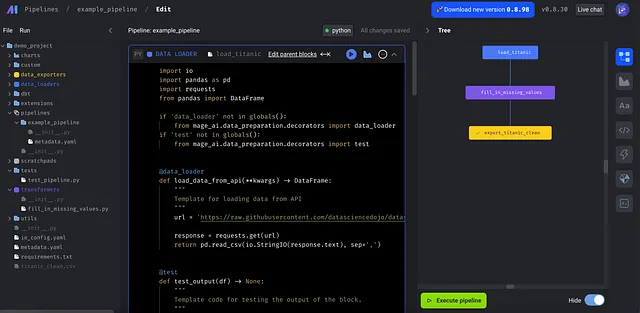
BDD + Mage
通常のデータパイプラインには、インジェクション、変換、エクスポートの3つの主要なステップがあります。変換は、すべての複雑なビジネスロジックが実装される場所であり、複数の変換ステップが組み込まれるのは珍しくありません。
インジェクションタスクと変換タスクの明確な分離により、変換ロジックにBDDを適用するのは非常に簡単で直感的です。実際、それは通常のPython関数のテストのように感じますが、データパイプラインの一部であるという事実を無視しています。
ユーザーセグメンテーションの例に戻りましょう。ビジネスルールは@transformerブロックに配置する必要があり、ローダーとエクスポートから分離されています。
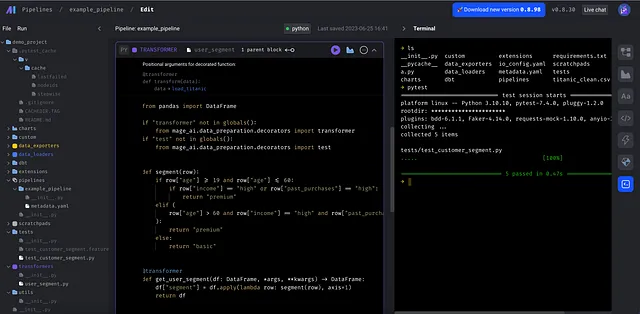
同じ@transformerブロックは、ローダーがpandasデータフレームを返す限り、複数のパイプラインに接続できます。テストを実行するには、ターミナルまたはCI/CDパイプラインでpytestコマンドを実行するだけです。トリガーなどのパイプラインの設定は別のファイルにあり、メインのパイプラインファイルをできるだけシンプルに保ちます。
これをAirflowで実装した場合に何が起こるか想像してみましょう。複雑な例ではありませんので、Airflowは確かにうまく処理できます。ただし、MageからAirflowに切り替えた時に「えー」と感じるいくつかの詳細があります。
- DAGファイルは、各DAGがメタデータを定義するための大きなコードブロックを持つため、混乱します。Mageでは、構成はyamlファイルに移動されるため、パイプラインファイルは簡潔に保たれます。
@dag( dag_id="user_segment", schedule_interval="0 0 * * *", start_date=pendulum.datetime(2023, 1, 1, tz="UTC"), catchup=False, dagrun_timeout=datetime.timedelta(minutes=60),)2. データの受け渡しはAirflowでは難しいです。Airflowでは、XCOMを使用してタスク間でデータを受け渡すことができます。しかし、データフレームなどの大規模なデータセットを直接XCOMを介して渡すことは推奨されていません。回避策として、まずデータを一時的なストレージに保存する必要がありますが、これは不必要なエンジニアリングの努力のように思えます。 Mageはデータの受け渡しを自然に処理し、データセットのサイズを気にする必要がありません。
3. 技術的には、AirflowはいくつかのバージョンのPythonパッケージをサポートしていますが、大きなコストがかかります。KubernetesPodOperatorとPythonVirtualenvOperatorを使用すると、タスクを独立した環境で実行できます。ただし、別のオペレータを使用するなど、Airflowにデフォルトで備わっている便利さはすべて失われます。対照的に、Mageは一元化されたrequirements.txtを使用してこの課題に対処し、すべてのタスクがMageのすべてのネイティブ機能にアクセスできるようにします。
結論
この記事では、テストの品質と開発者の体験を向上させるという目標のもと、2つのテクノロジーを組み合わせました。BDDは、特徴ファイルとしてコードベースに直接埋め込まれた契約を作成することにより、ステークホルダーとエンジニアの間の協力を向上させることを目指しています。一方、Mageは開発者の体験を最優先に考えた、データパイプラインツールです。データをまさに第一級の市民として扱います。
これがあなたにインスピレーションを与え、少なくとも1つのテクノロジーを日常の業務に取り入れるモチベーションを感じていただければ幸いです。適切なツール選択は確かにチームの生産性を向上させることができます。あなたの意見を知りたいです。コメントで教えてください。乾杯!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
