Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
'Pic2Word Mapping from photos to words for zero-shot composition image search.'
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。
画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。
しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。
これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。
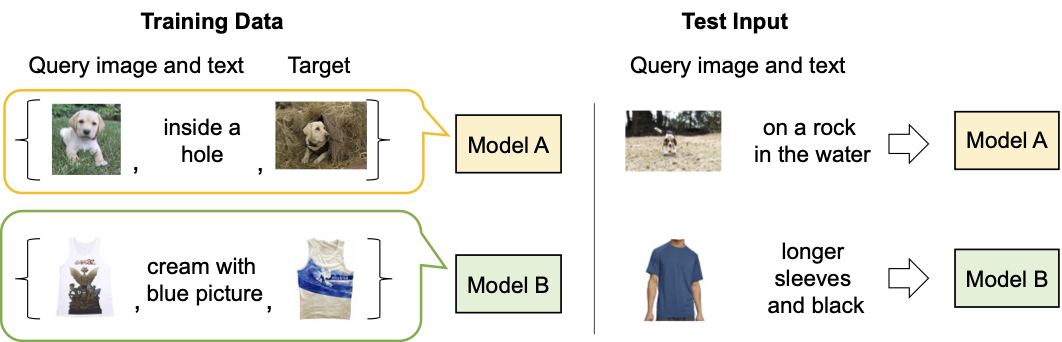 |
| 既存の組み合わせ画像検索モデルの説明。 |
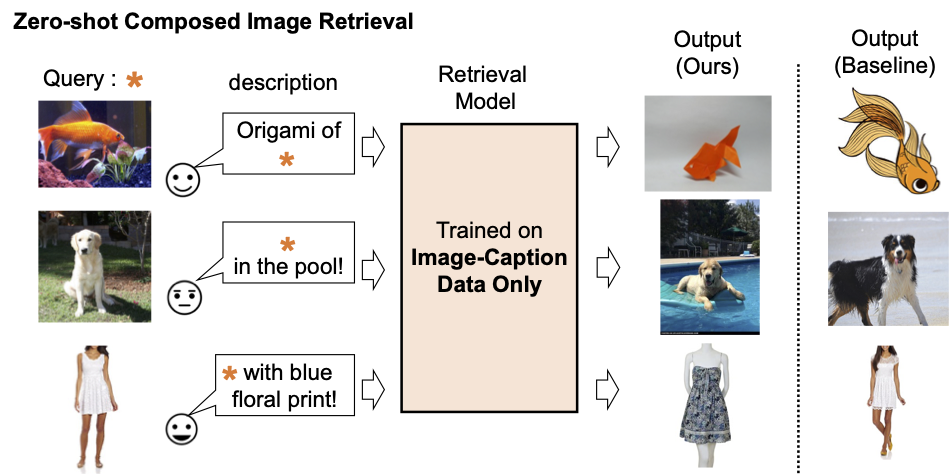 |
| 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 |
手法の概要
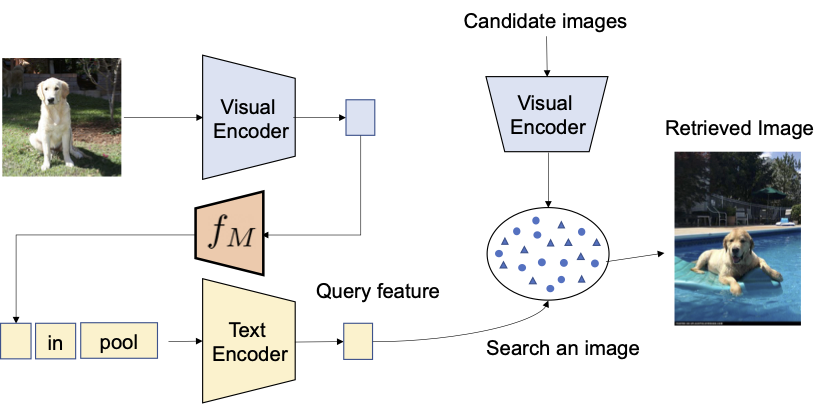
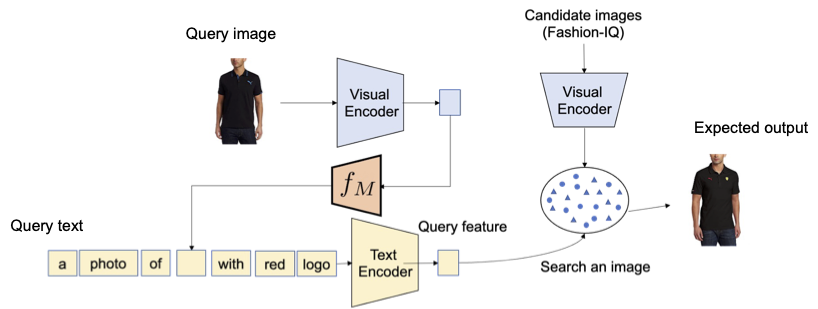
私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。
 |
| 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 |
トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。
 |
| トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 |
評価
さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。
ドメイン変換
まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。
教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。
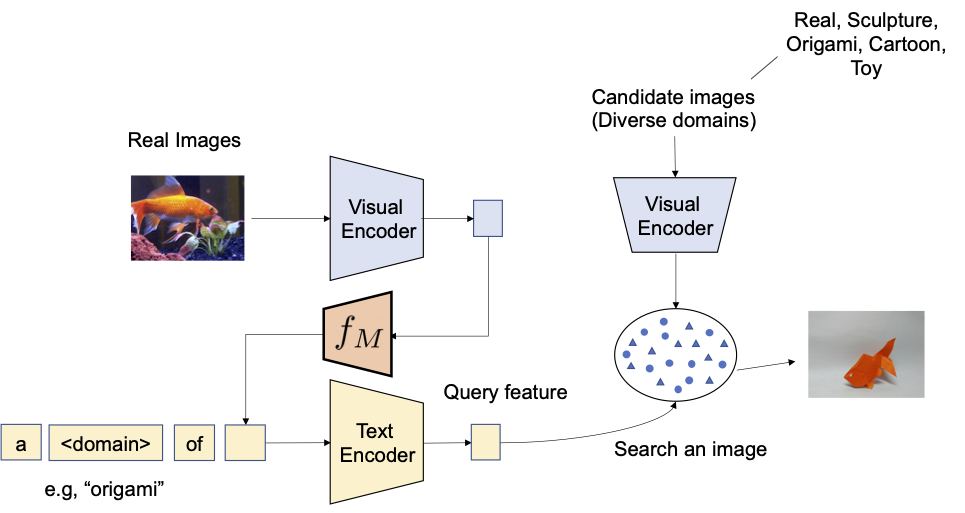 |
| 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 |
下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。
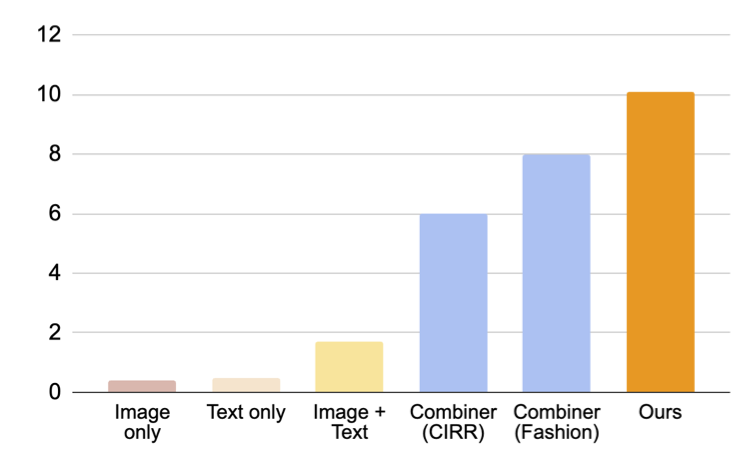 |
| ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。 |
ファッション属性の組み合わせ
次に、Fashion-IQデータセットを使用して、衣服の色、ロゴ、袖の長さなどのファッション属性の組み合わせを評価します。下の図は、クエリに対して望ましい出力を示しています。
 |
| ファッション属性のCIRの概要。 |
下の図では、CB(我々の手法と同じアーキテクチャを使用する)を含むベースラインとの比較を示しています。また、CIRモデルのトレーニングに三つ組を使用した教師ありベースラインの比較も行います:(i) CBは我々の手法と同じアーキテクチャを使用し、(ii) CIRPLANT、ALTEMIS、MAAFはResNet50などのより小さなバックボーンを使用します。これらの手法との比較により、ゼロショットアプローチがこのタスクでどれだけ優れているかを理解することができます。
CBは我々の手法を上回っていますが、我々の手法はより小さなバックボーンを持つ教師ありベースラインよりも優れたパフォーマンスを示しています。この結果から、頑健なCLIPモデルを活用することで、アノテーションされた三つ組を必要とせずに非常に効果的なCIRモデルをトレーニングすることができることが示唆されています。
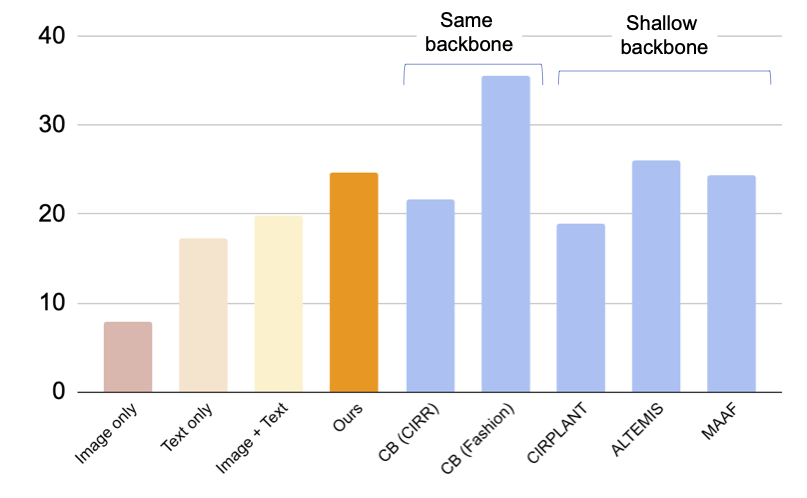 |
| Fashion-IQデータセットにおける合成画像検索の結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)(高い方が良い)。水色のバーは三つ組を使用してモデルをトレーニングしています。なお、我々の手法はこれらの教師ありベースラインと浅い(小さな)バックボーンで同等のパフォーマンスを発揮します。 |
質的結果
下の図にいくつかの例を示します。教師ありトレーニングデータを必要としないベースラインの手法(テキスト+画像特徴の平均)と比較して、我々の手法は目標の画像を正確に検索することができます。
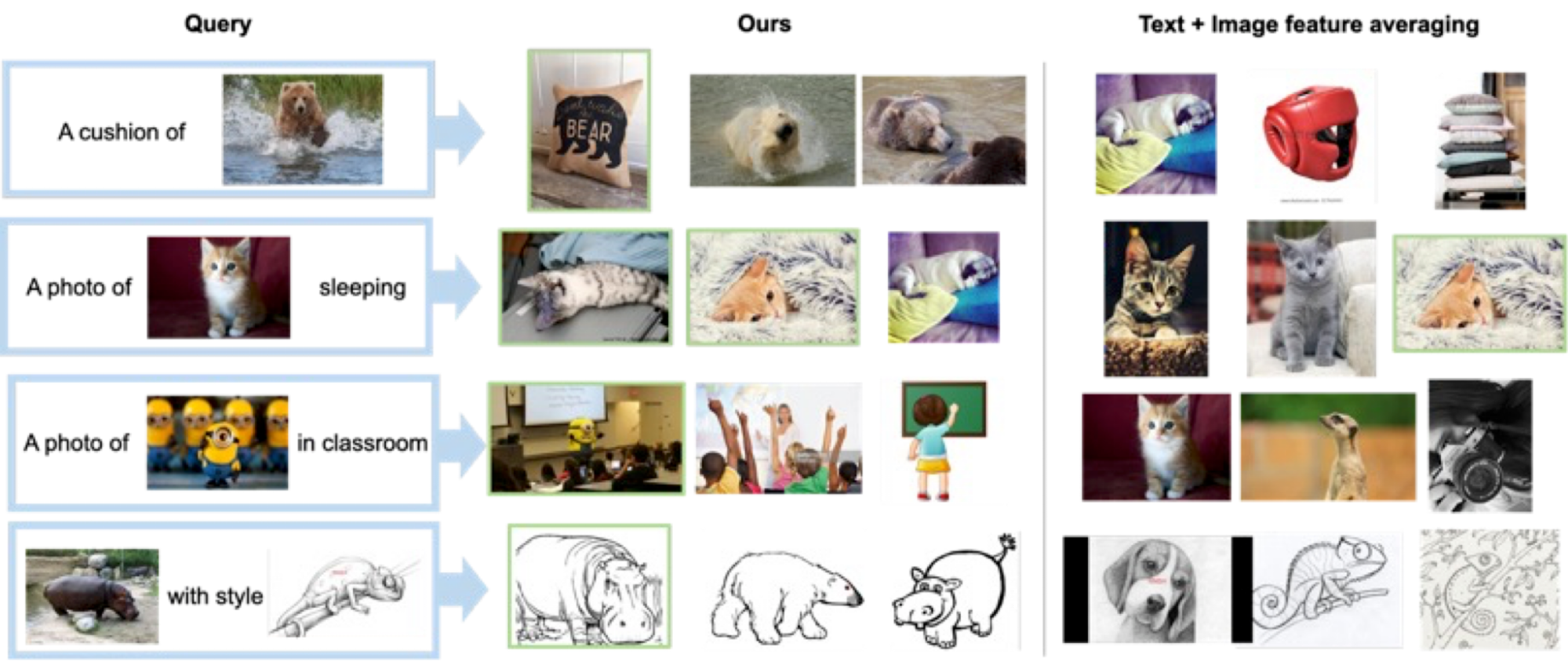 |
| さまざまなクエリ画像とテキストの説明に対する質的な結果。 |
結論と今後の課題
本記事では、ZS-CIRのための画像から単語へのマッピング方法であるPic2Wordを紹介しました。画像を単語トークンに変換することで、画像とキャプションのデータセットのみを使用してCIRモデルを実現することを提案しています。さまざまな実験により、画像キャプションのデータセットで訓練されたモデルの効果を検証し、多様なCIRタスクでの訓練の有効性を示しています。現在の作業では画像データのみを使用していますが、キャプションデータを使用してマッピングネットワークを訓練することが潜在的な将来の研究方向です。
謝辞
この研究は、Kuniaki Saito、Kihyuk Sohn、Xiang Zhang、Chun-Liang Li、Chen-Yu Lee、Kate Saenko、Tomas Pfisterによって行われました。また、Zizhao ZhangとSergey Ioffeには貴重なフィードバックをいただきました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






