「AIを活用した言語学習のためのパーソナルボイスボット」
Personal Voice Bot for AI-based language learning

新しい言語を習得する最も効果的な方法は何でしょうか?話すことです!しかし、新しい単語やフレーズを他の人の前で試すことはどれだけ挑戦的であるか、私たちはみな知っています。他の人からの判断や恥ずかしさから解放され、忍耐強く理解のある友人と一緒に練習できるとしたらどうでしょうか?
あなたが探している忍耐強く理解のある友人は、LLMによってパワーアップされた仮想的な言語チューターかもしれません!これは、自宅の快適な空間から言語をマスターするための画期的な方法になるかもしれません。
最近、大規模な言語モデルが登場し、私たちのやり方を変えています。これらの強力なツールは、人間のように応答するチャットボットを作成し、さまざまな生活の側面に迅速に統合され、さまざまな方法で使用されています。特に興味深い用途の1つは、言語学習、特に話す練習です。
数年前にドイツに引っ越したとき、新しい言語を学び、話す機会を見つけることがどれだけ難しいかを実感しました。クラスや言語グループは高価で、忙しいスケジュールに合わせるのが難しい場合もあります。これらの課題に直面した個人として、私はアイデアを思いつきました:なぜチャットボットを話す練習に使用しないのでしょうか?ただし、テキストだけでは不十分です。言語学習には書くこと以上の要素が含まれるため、AIパワードのチャットボットを音声からテキストへ、テキストから音声への変換と組み合わせることで、まるで実際の人と話しているような学習体験を作り出すことができました。
- 「DenseDiffusionとの出会い:テキストから画像生成における密なキャプションとレイアウト操作に対処するためのトレーニング不要のAI技術」
- 「Amazon LexとAmazon Kendra、そして大規模な言語モデルを搭載したAWSソリューションのQnABotを使用して、セルフサービス型の質問応答を展開してください」
- 「クラスの不均衡:ランダムオーバーサンプリングからROSEへ」
本記事では、選んだツールを共有し、プロセスを説明し、音声コマンドと音声応答を介したAIチャットボットによる話す練習の概念を紹介します。プロジェクトのパイプラインは、音声からテキストへの変換、言語モデルの使用、テキストから音声への変換の3つのメインセクションで構成されます。以下でそれぞれについて説明します。
1. 音声からテキストへの変換
私の言語チューターの音声認識は、ユーザーの話し言葉入力とAIのテキストベースの理解との間の橋渡しを行い、応答を生成します。これは、声による対話を可能にするための重要なコンポーネントであり、没入感のある効果的な言語学習体験に貢献します。
正確な変換は、チャットボットとのスムーズな対話にとって重要です。発音、アクセント、文法がキーファクターとなる言語学習の文脈では、さまざまな音声認識ツールを使用して、Pythonで話し言葉をテキストで変換することができます。例えば、OpenAIのWhisperやGoogle Cloudの音声テキスト変換などがあります。
言語チュータープロジェクトに音声認識ツールを選ぶ際には、精度、言語サポート、コスト、オフラインソリューションが必要かどうかなどの考慮事項を考慮する必要があります。
Googleにはインターネット接続が必要なPython APIがあり、1ヶ月に60分の変換が無料で利用できます。Googleとは異なり、OpenAIはWhisperモデルを公開し、十分な計算能力がある限りインターネットの速度に依存せずにローカルで実行することができます。なので、私は変換のレイテンシーをできるだけ低くするためにWhisperを選びました。
2. 言語モデル
言語モデルは、このプロジェクトの中核です。私はChatGPTとそのAPIに非常に精通しているため、このプロジェクトにもそれを使用することにしました。ただし、十分な計算能力がある場合は、Llamaをローカルに展開して無料で使用することもできます。ChatGPTは多少の費用がかかりますが、コードのわずかな行だけで実行できるため、はるかに便利です。
応答の一貫性を高め、特定のテンプレートでそれらを持つために、言語モデルのファインチューニング(例:ChatGPTのファインチューニング方法)も行うことができます。模範的な文とそれに対応する最適な応答を生成し、それらをファインチューニングのトレーニングにフィードする必要があります。ただし、私が構築した基本的なチューターにはファインチューニングは必要ありませんので、プロジェクトでは一般的なGPT3.5-turboを使用します。
以下に、PythonでChatGPTのAPIを介したユーザーとChatGPTの対話を容易にするAPI呼び出しの例を示します。まず、まだアカウントを持っていない場合は、OpenAIのアカウントを開設し、ChatGPTとの対話に必要なAPIキーを設定する必要があります。手順はこちらに記載されています。
APIキーを設定したら、openai.ChatCompletion.createメソッドを使用してテキストを生成できます。このメソッドには2つのパラメータが必要です。1つ目はAPI経由でアクセスする特定のGPTモデルを指定するmodelパラメータで、2つ目はChatGPTとの対話の構造を含むmessagesパラメータです。messagesパラメータは、roleとcontentの2つの主要なコンポーネントで構成されています。
以下は、プロセスを説明するためのコードスニペットです:
# 行動を設定してメッセージを初期化します。
messages = [{"role": "system", "content": "ここに行動を入力してください。"}]
# ユーザーとの会話を続けるための無限ループを開始します。
while True:
content = input("ユーザー: ") # ユーザーからの入力を取得して応答します。
messages.append({"role": "user", "content": content}) # ユーザーの入力をメッセージに追加します。
# ユーザーの入力に対してOpenAI GPT-3.5モデルを使用して応答を生成します。
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
chat_response = completion.choices[0].message.content # APIの応答からチャットの応答を抽出します。
print(f'ChatGPT: {chat_response}') # 応答を表示します。
# チャットの履歴を保存するために、アシスタントの役割で応答をメッセージに追加します。
messages.append({"role": "assistant", "content": chat_response})system役割は、メッセージリストの先頭にコンテンツ内の指示を追加することで、ChatGPTの振る舞いを決定するために定義されています。- チャット中、ユーザーからの
userメッセージは、メンションされた音声認識モデルを介して受信され、ChatGPTからの応答を得るために使用されます。 - 最後に、ChatGPTの応答は
assistant役割でメッセージリストに追加され、会話履歴が記録されます。
3. テキストから音声への変換
音声からテキストへの変換のセクションでは、ユーザーが音声コマンドを使用して実際の人との会話のような体験をシミュレートする方法について説明しました。この感覚をさらに高め、よりダイナミックでインタラクティブな学習体験を作り出すために、次のステップではテキスト出力をgTTSなどのテキストから音声への変換ツールを使用して聴覚的な音声に変換します。これにより、より魅力的で理解しやすい体験が生まれるだけでなく、言語学習の重要な側面であるリーディングではなくリスニングを通じた理解の課題にも対応します。この音響要素を統合することで、現実世界の言語使用に近い包括的な練習を促進しています。
Googleのテキストから音声への変換(gTTS)やIBM Watsonのテキストから音声への変換など、さまざまなTTSツールがあります。このプロジェクトでは、gTTSを選択しました。なぜなら、非常に使いやすく、自然な音声品質を備えており、無料で利用できるからです。gTTSライブラリを使用するには、テキストを音声に変換するためにGoogleのサーバーへのアクセスが必要なため、インターネット接続が必要です。
パイプラインの詳細な説明
パイプラインに入る前に、Githubのページでコード全体を見ていただくと、以下の説明でいくつかのセクションを参照することができます。
次の図は、リアルタイムで声を基にした会話型の学習体験を設定するために設計されたAIパワードバーチャル言語チューターのワークフローを説明しています:
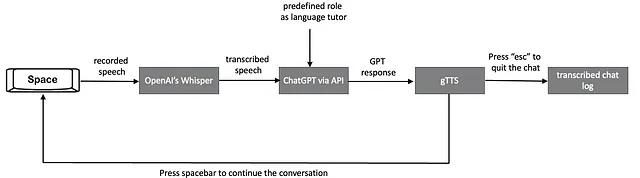
- ユーザーは、自分の発話を記録するために録音を開始します。これは、スペースバーを押して保持することで実現され、スペースバーを離すと録音が停止します。この押して話す機能を可能にするPythonコードのセクションについて説明します。
以下のグローバル変数は、録音プロセスの状態を管理するために使用されます:
recording = False # 現在録音中であることを示します。
done_recording = False # ユーザーが音声コマンドの録音を完了したことを示します。
stop_recording = False # ユーザーが会話を終了したいことを示します。listen_for_keys関数は、キーの押下とリリースをチェックするためのものです。スペースバーとエスケープボタンの状態に基づいて、グローバル変数を設定します。
def listen_for_keys():
# 録音を制御するためのキープレスを監視する関数
global recording, done_recording, stop_recording
while True:
if keyboard.is_pressed('space'): # スペースバーを押すと録音が開始されます。
stop_recording = False
recording = True
done_recording = False
elif keyboard.is_pressed('esc'): # 'esc'キーを押すと録音が停止します。
stop_recording = True
break
elif recording: # スペースバーを離すと録音が停止します。
recording = False
done_recording = True
break
time.sleep(0.01)コールバック関数は、録音時にオーディオデータを処理するために使用されます。録音フラグをチェックして、受信したオーディオデータを記録するかどうかを判断します。
def callback(indata, frames, time, status): # 録音中の各オーディオブロックごとに呼び出される関数 if recording: if status: print(status, file=sys.stderr) q.put(indata.copy())press2record関数は、ユーザーがスペースバーを押して押し続けると音声録音を処理するメイン関数です。
録音状態を管理するためのグローバル変数を初期化し、サンプルレートを決定し、録音されたオーディオを一時ファイルに保存します。
その後、SoundFileオブジェクトを開き、オーディオデータを書き込むためのInputStreamオブジェクトを作成します。これには先述のcallback関数が使用されます。キーの押下を監視するスレッドが開始され、特に録音のためのスペースバーと停止のための「esc」キーを監視します。ループ内で関数は録音フラグをチェックし、録音がアクティブであればオーディオデータをファイルに書き込みます。録音が停止された場合、関数は-1を返します。それ以外の場合は、録音されたオーディオのファイル名を返します。
def press2record(filename, subtype, channels, samplerate): # キーが押されたときに録音を処理する関数 global recording, done_recording, stop_recording stop_recording = False recording = False done_recording = False try: # サンプルレートが指定されていない場合は決定する if samplerate is None: device_info = sd.query_devices(None, 'input') samplerate = int(device_info['default_samplerate']) print(int(device_info['default_samplerate'])) # ファイル名が指定されていない場合は一時ファイルを作成する if filename is None: filename = tempfile.mktemp(prefix='captured_audio', suffix='.wav', dir='') # 書き込み用にサウンドファイルを開く with sf.SoundFile(filename, mode='x', samplerate=samplerate, channels=channels, subtype=subtype) as file: with sd.InputStream(samplerate=samplerate, device=None, channels=channels, callback=callback, blocksize=4096) as stream: print('Spacebarを押して録音を開始し、離して停止するか、Escキーを押して終了します') listener_thread = threading.Thread(target=listen_for_keys) # リスナーを別スレッドで開始 listener_thread.start() # 録音されたオーディオをファイルに書き込む while not done_recording and not stop_recording: while recording and not q.empty(): file.write(q.get()) # 録音が停止された場合は-1を返す if stop_recording: return -1 except KeyboardInterrupt: print('ユーザーによって中断されました') return filename最後に、get_voice_command関数はpress2recordを呼び出してユーザーの音声コマンドを録音します。
def get_voice_command(): # ... saved_file = press2record(filename="input_to_gpt.wav", subtype = args.subtype, channels = args.channels, samplerate = args.samplerate) # ...- 音声コマンドを一時的な.wavファイルにキャプチャして保存した後、トランスクリプションフェーズに入ります。この段階では、録音されたオーディオがWhisperを使用してテキストに変換されます。.wavファイルのトランスクリプションタスクを単純に実行する対応するスクリプトは以下の通りです:
def get_voice_command(): # ... result = audio_model.transcribe(saved_file, fp16=torch.cuda.is_available()) # ...このメソッドは2つのパラメーターを受け取ります。録音されたオーディオファイルのパスであるsaved_fileと、対応するハードウェアでCUDAが利用可能な場合にパフォーマンスを向上させるためにFP16精度を使用するかどうかのオプションフラグです。単純に変換されたテキストが返されます。
- 次に、変換されたテキストはChatGPTに送信され、
interact_with_tutor()関数で適切な応答を生成します。対応するコードセグメントは次のようになります:
def interact_with_tutor(): # チャットアシスタントの動作を設定するためのシステムロールを定義 messages = [ {"role": "system", "content" : "Du bist Anna, meine deutsche Lernpartnerin. Du wirst mit mir chatten. Ihre Antworten werden kurz sein. Mein Niveau ist B1, stell deine Satzkomplexität auf mein Niveau ein. Versuche immer, mich zum Reden zu bringen, indem du Fragen stellst, und vertiefe den Chat immer."} ] while True: # ユーザーの音声コマンドを取得 command = get_voice_command() if command == -1: # 録音が停止された場合はチャットログを保存して終了 save_response_to_pkl(messages) return "チャットが停止しました。" # ユーザーのコマンドをメッセージ履歴に追加 messages.append({"role": "user", "content": command}) # チャットアシスタントからの応答を生成 completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages ) # 応答からテキストを抽出 chat_response = completion.choices[0].message.content # 応答からテキストを抽出 print(f'ChatGPT: {chat_response} \n') # アシスタントの応答を表示 messages.append({"role": "assistant", "content": chat_response}) # アシスタントの応答をメッセージ履歴に追加 # ...関数interact_with_tutorは、会話全体にわたってChatGPTの振る舞いを形成するためのChatGPTのシステムロールを定義して開始します。私の目標はドイツ語の練習なので、システムロールをそれに合わせて設定しました。仮想チューターには「アンナ」という名前を付け、彼女の応答を調整するために私の言語能力レベルを設定しました。さらに、彼女に質問をすることで会話を興味深く保つように指示しました。
次に、ユーザーの音声コマンドが「ユーザー」という役割でメッセージリストに追加されます。このメッセージはその後ChatGPTに送信されます。whileループ内で会話が続くと、ユーザーコマンドとGPTの応答の完全な履歴がメッセージリストに記録されます。
- ChatGPTのそれぞれの応答の後、gTTSを使ってテキストメッセージを音声に変換します。
def interact_with_tutor(): # ... # テキスト応答を音声に変換する speech_object = gTTS(text=messages[-1]['content'],tld="de", lang=language, slow=False) speech_object.save("GPT_response.wav") current_dir = os.getcwd() audio_file = "GPT_response.wav" # 音声応答を再生する play_wav_once(audio_file, args.samplerate, 1.0) os.remove(audio_file) # 一時的な音声ファイルを削除するgTTS()関数には4つのパラメータがあります:text、tld、lang、slowです。 textパラメータには、音声に変換したいmessagesリストの最後のメッセージの内容([-1]で示される)が割り当てられます。 tldパラメータは、Google Translateサービスのトップレベルドメインを指定します。これを"de"に設定することで、ドイツ語の発音とイントネーションが適切になるようにします。 langパラメータは、テキストを話す言語を指定します。このコードでは、language変数が'de'に設定されており、テキストがドイツ語で話されることを意味します。slow=False: slowパラメータは音声の速度を制御します。これをFalseに設定すると、音声は通常の速度で話されます。 Trueに設定すると、音声はよりゆっくりと話されます。
- ChatGPTの応答の変換された音声は、一時的な.wavファイルとして保存され、ユーザーに再生された後に削除されます。
interact_with_tutor関数は、ユーザーがスペースバーを押して会話を続ける限り、繰り返し実行されます。- ユーザーが「esc」を押すと、会話が終了し、会話全体がpickleファイル
chat_log.pklに保存されます。後で分析に使用できます。
コマンドラインの使用方法
スクリプトを実行するには、ターミナルで次のようにPythonコードを実行します:
sudo python chat.pysudoが必要な理由は、スクリプトがマイクにアクセスし、キーボードライブラリを利用する必要があるためです。Anacondaを使用している場合は、「管理者として実行」でAnacondaターミナルを起動して完全なアクセス権限を与えることもできます。
以下は、コードが私のラップトップ上で実行される様子を示すデモビデオです。パフォーマンスを感じることができます:
著者作成のデモビデオ
最終的な考察
私はChatGPTのシステムロールを設定し、gTTs関数内のパラメータをドイツ語に合わせることでチューターの言語をドイツ語に設定しました。ただし、簡単に他の言語に切り替えることもできます。ターゲット言語に設定するのに数秒しかかかりません。
特定のトピックについてチャットしたい場合は、ChatGPTのシステムロールにそれを追加することもできます。例えば、面接の練習に使うこともできます。また、応答を調整するために言語レベルを指定することもできます。
重要な注意点は、チャットの全体的な速度はインターネット接続(ChatGPT APIとgTTSのため)およびハードウェア(Whisperのローカル展開のため)に依存するということです。私の場合、私の入力後の全体的な応答時間は4〜10秒の間になります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






