PyTorchモデルのパフォーマンス分析と最適化—Part2
Performance analysis and optimization of PyTorch models - Part 2.
PyTorchプロファイラーとTensorBoardを使ったトレーニングステップでのCPU演算の特定と削減方法
これは、GPU上で実行されるPyTorchモデルの分析と最適化に関する一連の投稿の2番目の部分です。最初の投稿では、PyTorchプロファイラーとTensorBoardを使用してPyTorchモデルを反復的に分析および最適化するプロセスと、その重要な可能性を示しました。この投稿では、PyTorchのイーガー実行によって特に一般的なパフォーマンスの問題の1つに焦点を当てます。モデル実行の一部にCPUへの依存があるため、このような問題の存在と原因を特定することは非常に難しく、専用のパフォーマンス分析ツールの使用が必要です。この投稿では、PyTorchプロファイラーとPyTorchプロファイラーTensorBoardプラグインを使用して、このようなパフォーマンスの問題を特定するためのいくつかのヒントを共有します。
イーガー実行の利点と欠点
PyTorchの主な魅力の1つは、そのイーガー実行モードです。イーガーモードでは、モデルを構成する各PyTorch操作は、到達した直後に独立して実行されます。これは、GPUで実行するために最適化された単一のグラフにモデル全体が事前コンパイルされるグラフモードとは対照的です。通常、この事前コンパイルにより、パフォーマンスが向上します(例:こちらを参照)。イーガーモードでは、操作ごとにプログラミングコンテキストがアプリケーションに戻されるため、任意のテンソルにアクセスして評価することができます。これにより、MLモデルの構築、分析、およびデバッグが容易になります。一方、モデルにサブオプティマルなコードブロックが(時には偶然に)挿入されることにより、モデルをより攻撃されやすくします。私たちが示すように、このようなコードブロックを特定し、修正する方法を知っていることは、モデルの速度に重要な影響を与えることができます。
おもちゃの例
次のブロックでは、デモンストレーションに使用するおもちゃの例を紹介します。コードは、前の投稿の例と、このPyTorchチュートリアルで定義されている損失関数に基づいています。
まず、簡単な分類モデルを定義します。このアーキテクチャは、この投稿には関係ありません。
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optimimport torch.profilerimport torch.utils.dataimport torchvision.modelsimport torchvision.transforms as Tfrom torchvision.datasets.vision import VisionDatasetimport numpy as npfrom PIL import Image# サンプルモデルclass Net(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 8, 3, padding=1) self.conv2 = nn.Conv2d(8, 12, 3, padding=1) self.conv3 = nn.Conv2d(12, 16, 3, padding=1) self.conv4 = nn.Conv2d(16, 20, 3, padding=1) self.conv5 = nn.Conv2d(20, 24, 3, padding=1) self.conv6 = nn.Conv2d(24, 28, 3, padding=1) self.conv7 = nn.Conv2d(28, 32, 3, padding=1) self.conv8 = nn.Conv2d(32, 10, 3, padding=1) self.pool = nn.MaxPool2d(2, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = self.pool(F.relu(self.conv4(x))) x = self.pool(F.relu(self.conv5(x))) x = self.pool(F.relu(self.conv6(x))) x = self.pool(F.relu(self.conv7(x))) x = self.pool(F.relu(self.conv8(x))) x = torch.flatten(x, 1) # flatten all dimensions except batch return x次に、かなり標準的なクロスエントロピー損失関数を定義します。この損失関数が主な焦点となります。
def log_softmax(x): return x - x.exp().sum(-1).log().unsqueeze(-1)def weighted_nll(pred, target, weight): assert target.max() < 10 nll = -pred[range(target.shape[0]), target] nll = nll * weight[target] nll = nll / weight[target].sum() sum_nll = nll.sum() return sum_nll# カスタム損失の定義class CrossEntropyLoss(nn.Module): def forward(self, input, target): pred = log_softmax(input) loss = weighted_nll(pred, target, torch.Tensor([0.1]*10).cuda()) return loss最後に、データセットとトレーニングループを定義します:
# dataset with random images that mimics the properties of CIFAR10class FakeCIFAR(VisionDataset): def __init__(self, transform): super().__init__(root=None, transform=transform) self.data = np.random.randint(low=0,high=256,size=(10000,32,32,3),dtype=np.uint8) self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist() def __getitem__(self, index): img, target = self.data[index], self.targets[index] img = Image.fromarray(img) if self.transform is not None: img = self.transform(img) return img, target def __len__(self) -> int: return len(self.data)transform = T.Compose( [T.Resize(256), T.PILToTensor()])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)device = torch.device("cuda:0")model = Net().cuda(device)criterion = CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# training loop wrapped with profiler objectwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler(’./log/example’), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) labels = data[1].to(device=device, non_blocking=True) inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5 if step >= (1 + 4 + 3) * 1: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step()経験豊富なPyTorch開発者は、損失関数でいくつかの非効率なコード行が含まれていることにすでに気付いているかもしれません。同時に、これらの非効率性には明らかな問題はなく、この種の非効率性は珍しくありません。クロスエントロピー損失の実装において3つの問題を見つけることができるかどうか、自身のPyTorchの熟練度をテストしてみてください。次のセクションでは、これらの問題を自力で見つけることができなかった場合、PyTorchプロファイラとそれに関連するTensorBoardプラグインを使用して、問題を特定する方法を説明します。
前回の記事と同様に、実験を反復的に実行し、パフォーマンスの問題を特定し、修正しようとします。Amazon EC2 g5.2xlargeインスタンス(NVIDIA A10G GPUと8 vCPUを搭載)を使用し、公式AWS PyTorch 2.0 Dockerイメージを使用して実験を実行します。トレーニング環境の選択はやや任意的であり、そのコンポーネントのどれかを推奨するものではありません。
初期パフォーマンス結果
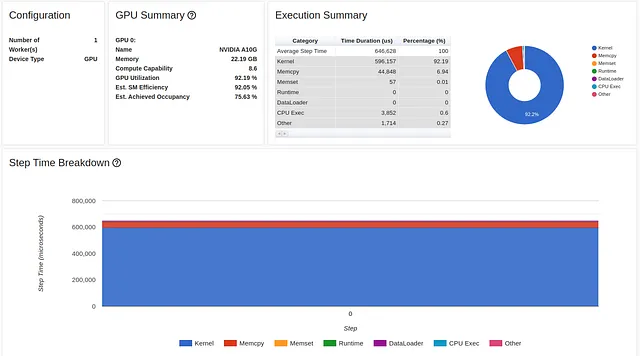
以下の画像は、スクリプトのパフォーマンスレポートの概要タブを示しています。
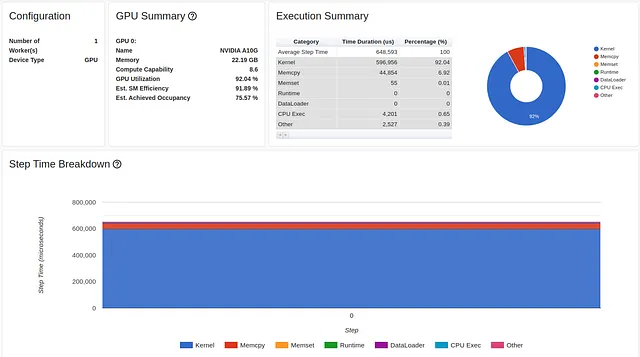
GPU利用率は比較的高い92.04%であり、ステップ時間は216ミリ秒です。(前回の記事と同様に、torch-tb-profilerバージョン0.4.1の概要は、3つのトレーニングステップのステップ時間を合計します。)このレポートだけでは、モデルに問題があるとは思わないかもしれません。しかし、パフォーマンスレポートのトレースビューはまったく異なる物語を語っています。
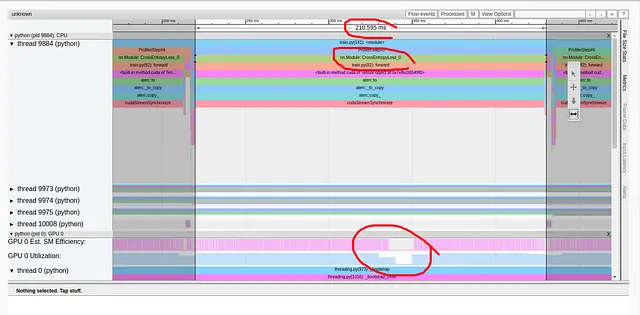
上記のように、クロスエントロピー損失の順伝播だけで、トレーニングステップの216ミリ秒中211ミリ秒を占めています!これは何かが間違っていることを明確に示しています。私たちの損失関数は、モデルに比べて少数の計算しか含まれておらず、ステップ時間の98%を占めるべきではありません。コールスタックをよく見ると、私たちの疑いを強めるいくつかの関数呼び出しがあることがわかります。これには、「to」、「copy_」、「cudaStreamSynchronize」などが含まれます。この組み合わせは通常、データがCPUからGPUにコピーされていることを示しています。これは、私たちが損失計算の途中で発生させたくないことです。この場合、私たちのパフォーマンス問題も、画像で強調されているように、GPU利用率の短い低下と一致しています。ただし、これは常にそうではありません。GPU利用率の低下は、パフォーマンスの問題と一致しない場合があるか、まったく見られない場合があります。
私たちは今、私たちの損失関数にパフォーマンスの問題があり、それがホストからGPUにテンソルをコピーすることに関連している可能性が高いことを知っています。ただ、これだけでは問題の原因となっているコードの正確な行を特定するには不十分かもしれません。そこで、各コード行をラベル付きのtorch.profiler.record_functionコンテキストマネージャでラップして、プロファイリング分析を再実行します。
# custom loss definitionclass CrossEntropyLoss(nn.Module): def forward(self, input, target): with torch.profiler.record_function('log_softmax'): pred = log_softmax(input) with torch.profiler.record_function('define_weights'): weights = torch.Tensor([0.1]*10).cuda() with torch.profiler.record_function('weighted_nll'): loss = weighted_nll(pred, target, torch.Tensor([0.1]*10).cuda()) return lossラベルの追加により、重みの定義、より正確には、重みのGPUへのコピーが問題のあるコード行であることが特定されるようになりました。
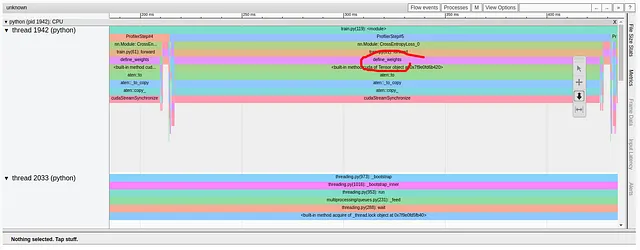
最適化 #1: トレーニングステップから余分なホストからGPUへのコピーを削除する
最初の問題を特定したら、修正は非常に簡単です。以下のコードブロックでは、重みベクトルを損失初期化関数で一度だけGPUにコピーします。
class CrossEntropyLoss(nn.Module): def __init__(self): super().__init__() self.weight = torch.Tensor([0.1]*10).cuda() def forward(self, input, target): with torch.profiler.record_function('log_softmax'): pred = log_softmax(input) with torch.profiler.record_function('weighted_nll'): loss = weighted_nll(pred, target, self.weight) return loss以下は、この修正後のパフォーマンス分析結果です。

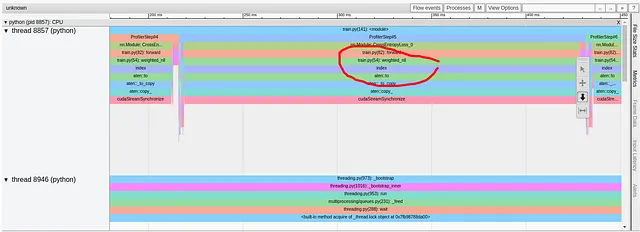
残念なことに、最初の最適化はステップ時間にほとんど影響を与えませんでした。Trace Viewレポートを見ると、修正する必要がある新しい深刻なパフォーマンスの問題があることがわかります。
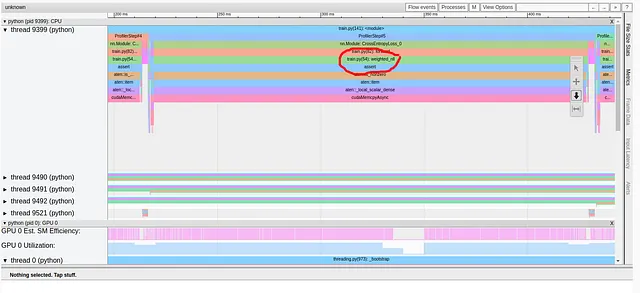
新しいレポートでは、weighted_nll関数から問題が発生していることが示されています。以前と同様に、torch.profiler.record_functionを使用して問題のあるコード行を特定しました。この場合、assert呼び出しです。
def weighted_nll(pred, target, weight): with torch.profiler.record_function('assert'): assert target.max() < 10 with torch.profiler.record_function('range'): r = range(target.shape[0]) with torch.profiler.record_function('index'): nll = -pred[r, target] with torch.profiler.record_function('nll_calc'): nll = nll * weight[target] nll = nll/ weight[target].sum() sum_nll = nll.sum() return sum_nllこの問題は、以前のパフォーマンス問題によって隠されていたため、ベースの実験でも存在していました。性能最適化の過程で、以前に他の問題によって隠されていた深刻な問題がこのように突然現れることは珍しくありません。
呼び出しスタックのより詳細な分析により、「item」、「_local_scalar_dense」、「cudaMemcpyAsync」に対する呼び出しが示されます。これは、データがGPUからホストにコピーされていることを示すものです。実際に、CPUで実行されるアサートコールは、GPUに存在するターゲットテンソルにアクセスする必要があり、非常に効率が悪いデータコピーが発生します。
最適化#2:トレーニングステップから冗長なGPU-to-hostコピーを削除する
入力ラベルの合法性を検証することは正当な理由があるかもしれませんが、トレーニングのパフォーマンスにこんなにも悪影響を与えるべきではありません。私たちの場合、問題を修正するのは、アサートをデータ入力パイプラインに移動し、ラベルがGPUにコピーされる前に実行するだけです。アサートを削除した後も、パフォーマンスはほとんど変わりません:
重要な注意点:通常、フォワードパスでホストとGPU間のコピーを減らすことを目指しますが、GPUでサポートされていないカーネルが必要な場合(例えば)、またはCPUで特定のカーネルを実行することでパフォーマンスが向上する場合(例えば)、これが望ましくない場合があります。
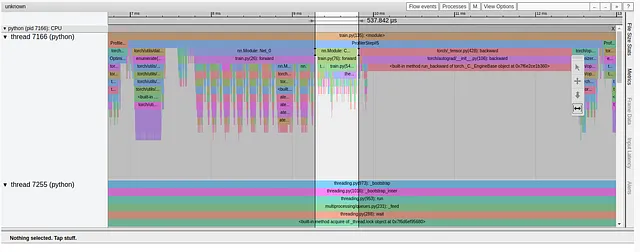
トレースビューを分析すると、次のパフォーマンスの問題が明らかになります:
再び、以前の最適化により、今回はpredテンソルのインデックス付け時に新しい深刻なパフォーマンス問題が明らかになりました。インデックスはrとtargetテンソルによって定義されます。ターゲットテンソルはすでにGPUに存在している一方、以前の行で定義されたrテンソルは存在しません。これにより、再び非効率なホストからGPUへのデータコピーが発生します。
最適化#3:rangeをtorch.arangeで置き換える
Pythonのrange関数は、CPU上でリストを出力します。トレーニングステップにリストが存在する場合は、警告が必要です。以下のコードブロックでは、rangeの使用をtorch.arangeで置き換え、出力テンソルをGPU上で直接作成するように構成します。
def weighted_nll(pred, target, weight): with torch.profiler.record_function('range'): r = torch.arange(target.shape[0], device="cuda:0") with torch.profiler.record_function('index'): nll = -pred[r, target] with torch.profiler.record_function('nll_calc'): nll = nll * weight[target] nll = nll/ weight[target].sum() sum_nll = nll.sum() return sum_nllこの最適化の結果は以下の通りです:

これで話が進みました!!ステップ時間が5.8ミリ秒に低下し、パフォーマンスが3700%向上しました。
更新されたトレースビューにより、損失関数が非常に合理的な0.5ミリ秒に低下したことが示されています。
しかし、まだ改善の余地があります。損失計算の大部分を占めるweighted_nll関数のTrace Viewをよく見てみましょう。
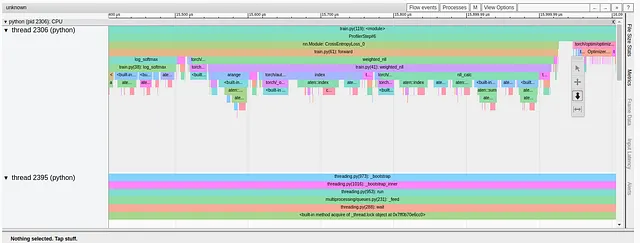
トレースからわかるように、この関数は複数の小さなブロックから形成されており、最終的には個々のCUDAカーネルにマップされます。これらのカーネルは、CudaLaunchKernel呼び出しを介してGPUにロードされます。可能であれば、より高レベルなPyTorch演算子(たとえばtorch.nn.NLLLoss)を優先することで、CPUとGPUの相互作用量を減らし、GPUカーネルの合計数を減らすことが望ましいです。このような関数は、基礎となる操作を「融合」することが前提とされており、全体のカーネル数を減らす必要があるためです。
最適化#4:カスタムNLLをtorch.nn.NLLLossに置き換える
以下のコードブロックには、torch.nn.NLLLossを使用するように更新された損失定義が含まれています。
class CrossEntropyLoss(nn.Module): def __init__(self): super().__init__() self.weight = torch.Tensor([0.1]*10).cuda() def forward(self, input, target): pred = log_softmax(input) nll = torch.nn.NLLLoss(self.weight) loss = nll(pred, target) return lossここで、私たちは別の一般的なエラーを導入する自由を与えました。高レベルの関数を使用することで、ステップ時間を5.8ミリ秒から5.3ミリ秒にさらに短縮することができます。
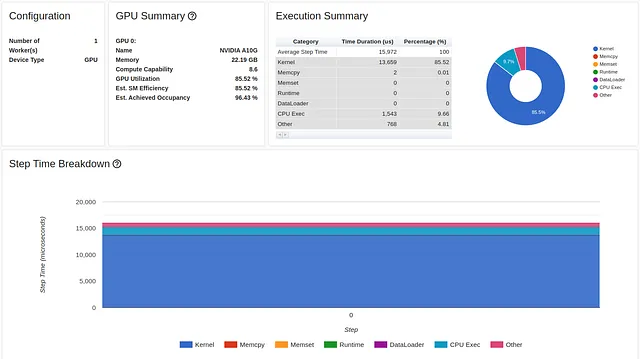
ただし、Trace Viewをよく見ると、損失関数のかなりの部分がtorch.nn.NLLLossオブジェクトの初期化に費やされていることがわかります。
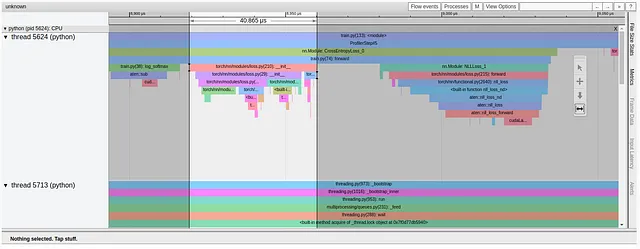
損失関数を振り返ってみると、トレーニングステップの各イテレーションで新しいNLLLossオブジェクトを初期化していることがわかります。自然に、オブジェクトの初期化はCPU上で行われます。私たちの場合は比較的速いですが、トレーニングステップ中にやる必要のあることを避けたいと考えています。
最適化#5:トレーニングステップでオブジェクトの初期化を避ける
以下のコードブロックでは、単一のtorch.nn.NLLLossインスタンスがinit関数で作成されるように損失実装を変更しました。
class CrossEntropyLoss(nn.Module): def __init__(self): super().__init__() self.weight = torch.Tensor([0.1]*10).cuda() self.nll = torch.nn.NLLLoss(self.weight) def forward(self, input, target): pred = log_softmax(input) loss = self.nll(pred, target) return loss結果は、ステップ時間が5.2ミリ秒にさらに改善されました。
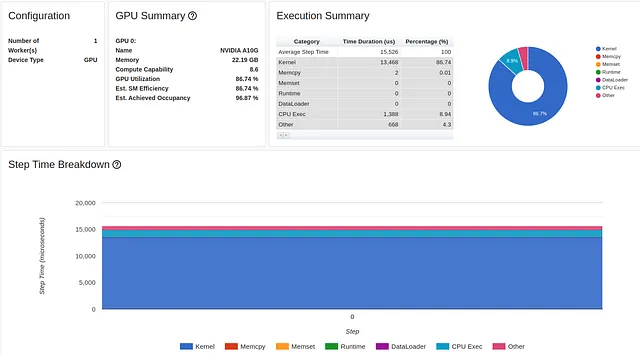
最適化#6:カスタム損失の代わりにtorch.nn.CrossEntropyLossを使用する
PyTorchには、組み込みのtorch.nn.CrossEntropyLossが含まれています。これを評価し、カスタム損失実装と比較します。
criterion = torch.nn.CrossEntropyLoss().cuda(device)その結果、ステップ時間は、合計パフォーマンスの4200%の向上(最初の216ミリ秒に比べて)の新しい低水準である5ミリ秒になりました。
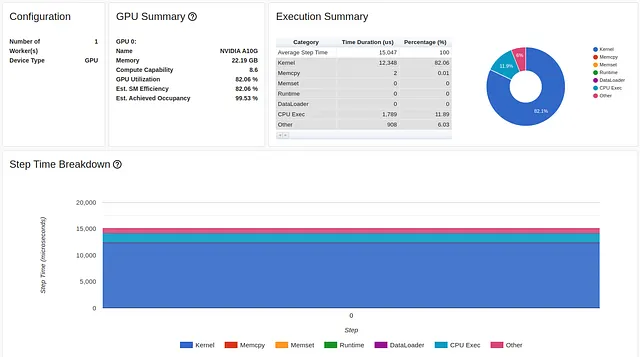
ロス計算のフォワードパスのパフォーマンス改善は、さらに劇的です。211ミリ秒から始まり、以下のように、わずか79マイクロ秒にまで低下しました。
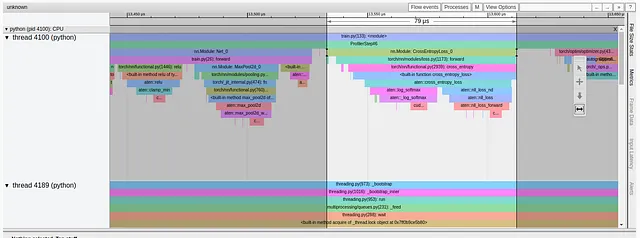
最適化#7:損失関数をコンパイルする
最後の最適化試行では、torch.compile APIを使用して損失関数をグラフモードで実行するように構成します。この投稿で詳しく説明し、この投稿の前編で示したように、torch.compileは、カーネルフュージョンやアウトオブオーダー実行などの技術を使用して、トレーニングアクセラレータに最適な方法で損失関数を低レベルのコンピュートカーネルにマッピングします。
criterion = torch.compile(torch.nn.CrossEntropyLoss().cuda(device))以下の画像は、この実験のTrace Viewの結果を示しています。
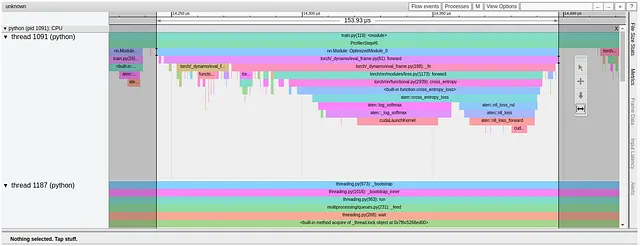
最初に見えるのは、「OptimizedModule」と「dynamo」という用語を含む用語の出現であり、これらはtorch.compileの使用を示唆しています。また、実際には、モデルのコンパイルにより、カーネルフュージョンの追加の機会が特定されなかったため、損失関数によってロードされるカーネルの数は減少しませんでした。実際に、私たちの場合、損失のコンパイルは、フォワードパスの損失関数の時間を79から154マイクロ秒に増加させました。CrossEntropyLossは、この最適化から利益を得るには十分な重要性がないようです。
最初の損失関数にtorchコンパイルを適用して、最適な方法でコードをコンパイルすることができないのはなぜですか?これにより、前述のステップバイステップの最適化に関する説明のすべての手間が省略できます。このアプローチの問題は、PyTorch 2.0コンパイル(この執筆時点で)がGPUからCPUへのいくつかのタイプのクロスオーバーを最適化することができるが、いくつかのタイプはグラフコンパイルをクラッシュさせ、その他のタイプは単一の大きなグラフではなく複数の小さなグラフを作成することになるためです。最後のカテゴリはグラフブレークを引き起こし、実質的にtorch.compile機能のパフォーマンス向上能力を制限します。(これを解決する方法の1つは、fullgraphフラグをTrueに設定してtorch.compileを呼び出すことです。)このオプションの詳細については、以前の投稿を参照してください。
結果
以下の表に、実行した実験の結果をまとめます。
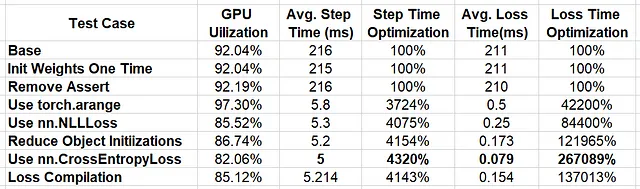
私たちの連続した最適化により、驚異的な4143%のパフォーマンス向上が実現しました!私たちはかなり無邪気に見える損失関数から始めました。私たちのアプリケーションの動作を詳しく分析しないと、何も問題がないと考え、必要以上に41倍も支払い続ける可能性がありました。
最終試験では、GPUの利用率が大幅に低下したことに気付いたかもしれません。これは、さらなるパフォーマンス最適化の可能性を示しています。私たちのデモンストレーションは終わりに近づいていますが、私たちの仕事はまだ終わっていません。ここからの進め方についてのアイデアについては、以前の投稿を参照してください。
結論
学んだことをいくつかまとめてみましょう。サマリーを2つに分けます。1つ目では、トレーニングパフォーマンスに影響を与える可能性のあるコーディング習慣について説明します。2つ目では、パフォーマンスプロファイリングのためのいくつかのヒントをお勧めします。これらの結論は、この投稿で共有した例に基づいていますが、機械学習モデルは特性や動作が大きく異なるため、独自のプロジェクトの詳細に基づいてこれらの結論を評価することを強くお勧めします。
コーディングのヒント
モデルのフォワードパスの実装方法は、そのパフォーマンスに重要な影響を与えることがあります。ここでは、この投稿でカバーした例に基づくいくつかの推奨事項を紹介します。
- フォワードパスで定数テンソルを初期化しないでください。代わりにコンストラクタで行ってください。
- フォワードパスでGPU上に存在するテンソルにアサートを使用しないでください。データ入力パイプラインに移動するか、必要なデータ検証を実行するためのPyTorchの組み込みメソッドがあるかどうかを確認してください。
- リストの使用を避けてください。デバイス上にテンソルを直接作成するためにtorch.arangeを使用できるかどうかを確認してください。
- 独自の損失実装を作成する代わりに、torch.nn.NLLLossやtorch.nn.CrossEntropyLossなどのPyTorchオペレータを使用してください。
- フォワードパスでオブジェクトを初期化しないでください。代わりにコンストラクタで行ってください。
- 適切な場合には、torch.compileを使用することを検討してください。
パフォーマンス分析のヒント
私たちが示したように、Tensorboard PyTorch Profilerプラグインのトレースビューは、モデルのパフォーマンス問題を特定する上で重要でした。以下では、私たちの例からいくつかの主要なポイントをまとめています。
- 高いGPU利用率は、コードが最適に実行されていることを必ずしも示していません。
- 予想よりも長い時間がかかるコードの部分に注意してください。
- torch.profiler.record_functionを使用して、パフォーマンスの問題を特定してください。
- GPU利用率の低下は、パフォーマンスの問題の原因と必ずしも一致していません。
- ホストからGPUへの意図しないデータコピーに注意してください。これらは通常、Trace Viewで検索できる「to」、「copy_」、「cudaStreamSynchronize」の呼び出しで識別されます。
- GPUからホストへの意図しないデータコピーに注意してください。これらは通常、Trace Viewで検索できる「item」、「cudaStreamSynchronize」の呼び出しで識別されます。
まとめ
この投稿では、トレーニングステップのフォワードパス中のCPUとGPUの間の冗長な相互作用から生じるパフォーマンスの問題に焦点を当てました。PyTorch Profilerやその関連するTensorBoardプラグインなどのパフォーマンスアナライザを使用して、このような問題を特定し、大幅なパフォーマンス改善を促進する方法を示しました。
前の投稿と同様に、モデルアーキテクチャやトレーニング環境など、トレーニングプロジェクトの詳細に応じて、成功した最適化への道筋は大きく異なることを強調します。実際には、ここで紹介した技術のいくつかは、パフォーマンスにほとんど影響を与えないか、むしろ悪化させることがあります。また、私たちが選んだ正確な最適化とその適用順序は、多少恣意的でした。プロジェクトの具体的な詳細に基づいて、自分自身のツールや技術を開発し、最適化の目標を達成することを強くお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- SRGANs:低解像度と高解像度画像のギャップを埋める
- このGoogleのAI論文は、さまざまなデバイスで大規模な拡散モデルを実行するために画期的なレイテンシー数値を集めるための一連の最適化を提示しています
- LLM-Blenderに会いましょう:複数のオープンソース大規模言語モデル(LLM)の多様な強みを活用して一貫して優れたパフォーマンスを達成するための新しいアンサンブルフレームワーク
- WAYVE社がGAIA-1を発表:ビデオ、テキスト、アクション入力を活用して現実的な運転ビデオを作成する自律性のための新しい生成AIモデル
- MIT教授が議会に語る「AIにおいて私たちは転換点にあります」
- 宇宙における私たちの位置を理解する
- 写真を撮るだけで、財産の査定を簡単にする






