‘Perceiver IO どんなモダリティにも対応するスケーラブルな完全注意モデル’
Perceiver IO スケーラブルな完全注意モデル
TLDR
私たちはPerceiver IOをTransformersに追加しました。これは、テキスト、画像、音声、ビデオ、ポイントクラウドなど、あらゆる種類のモダリティ(それらの組み合わせも含む)に対応した最初のTransformerベースのニューラルネットワークです。以下のスペースをご覧いただくと、いくつかの例をご覧いただけます。
- 画像間のオプティカルフローの予測
- 画像の分類。
また、いくつかのノートブックも提供しています。
以下に、モデルの技術的な説明をご覧いただけます。
はじめに
Transformerは、元々Vaswaniらによって2017年に紹介され、機械翻訳の最先端(SOTA)の結果を改善するというAIコミュニティでの革命を引き起こしました。2018年には、BERTがリリースされ、トランスフォーマーエンコーダ専用のモデルで、自然言語処理(NLP)のベンチマーク(特にGLUEベンチマーク)を圧倒的に上回りました。
- TransformersとRay Tuneを使用したハイパーパラメータの検索
- fairseqのwmt19翻訳システムをtransformersに移植する
- 🤗 APIのお客様のためにTransformerの推論を100倍高速化する方法
その後まもなくして、AI研究者たちはBERTのアイデアを他の領域にも適用し始めました。以下にいくつかの例を挙げます。
- Facebook AIのWav2Vec2は、このアーキテクチャをオーディオに拡張できることを示しました。
- Google AIのVision Transformer(ViT)は、このアーキテクチャがビジョンに非常に適していることを示しました。
- 最近では、Google AIのVideo Vision Transformer(ViViT)もこのアーキテクチャをビデオに適用しました。
これらのすべての領域で、大規模な事前トレーニングとこの強力なアーキテクチャの組み合わせにより、最先端の結果が劇的に改善されました。
ただし、Transformerのアーキテクチャには重要な制約があります。自己注意機構により、計算およびメモリの両方でスケーリングが非常に悪くなります。各レイヤーでは、すべての入力をクエリとキーの生成に使用し、ペアごとのドット積を計算します。したがって、高次元データに自己注意を適用するには、ある形式の前処理が必要です。たとえば、Wav2Vec2では、生の波形を時間ベースの特徴のシーケンスに変換するために、特徴エンコーダを使用してこの問題を解決しています。Vision Transformer(ViT)は、画像を重ならないパッチのシーケンスに分割し、「トークン」として使用します。Video Vision Transformer(ViViT)は、ビデオから重ならない時空間の「チューブ」を抽出し、「トークン」として使用します。Transformerを特定のモダリティで動作させるためには、通常はトークンのシーケンスに離散化する必要があります。
パーシーバー
パーシーバーは、この制約を解決するために、入力ではなく一連の潜在変数に自己注意メカニズムを使用することを目指しています。入力(テキスト、画像、音声、ビデオなど)は、潜在変数とのクロスアテンションにのみ使用されます。これにより、計算が安価である潜在空間で主な計算が行われるため、入力サイズには二次的な依存関係がありません。Transformerエンコーダは入力サイズに対して線形の依存関係しか持たず、潜在的な注意はそれに依存しません。これに続くPerceiver IOと呼ばれる論文では、著者たちはこのアイデアを拡張し、Perceiverが任意の出力も処理できるようにしました。アイデアは似ています。出力は潜在変数とのクロスアテンションにのみ使用されます。このブログ投稿全体を通じて、”Perceiver”と”Perceiver IO”という用語を同義に使用してPerceiver IOモデルを指すために使用します。
次のセクションでは、HuggingFace TransformersでのPerceiver IOの実装を通じて、Perceiver IOが実際にどのように機能するかについて詳しく見ていきます。以下のセクションでは、どのようにしてPerceiverが任意の種類のモダリティを事前処理および事後処理するかについて、テンソルの形状を用いて詳細に説明します。
HuggingFace TransformersのすべてのPerceiverの派生バリアントは、PerceiverModelクラスに基づいています。 PerceiverModelを初期化するには、3つの追加のインスタンスをモデルに提供することができます。
- プリプロセッサ
- デコーダ
- ポストプロセッサ。
これらのすべてはオプションです。 preprocessorは、すでにinputs(テキスト、画像、音声、ビデオなど)を埋め込んでいない場合にのみ必要です。 decoderは、Perceiverエンコーダの出力(つまり、潜在変数の最後の隠れ状態)を、分類のロジットやオプティカルフローなど、より有用なものにデコードする場合にのみ必要です。 postprocessorは、デコーダの出力を特定の特徴に変換する場合にのみ必要です(これは、自動エンコーディングを行う場合にのみ必要であり、後で詳しく見るようになります)。アーキテクチャの概要は、以下のように示されます。

Perceiverのアーキテクチャ。
言い換えると、inputs(どんなモダリティでも、またはそれらの組み合わせでもかまいません)は、最初にpreprocessorを使用してオプションで前処理されます。次に、前処理された入力は、Perceiverエンコーダの潜在変数とのクロスアテンション操作を実行します。この操作では、潜在変数がクエリ(Q)を生成し、前処理された入力がキーと値(KV)を生成します。この操作の後、Perceiverエンコーダは、潜在変数の埋め込みを更新するために(繰り返し可能な)セルフアテンション層のブロックを使用します。エンコーダは、最後に、潜在変数の最後の隠れ状態を含む形状(バッチサイズ、num_latents、d_latents)のテンソルを生成します。次に、分類のログットのようなもっと有用なものに潜在変数の最終的な隠れた状態をデコードするために、オプションのdecoderがあります。これは、訓練可能な埋め込みを使用してクエリ(Q)を生成し、潜在変数を使用してキーと値(KV)を生成するクロスアテンション操作を実行することによって行われます。最後に、オプションのpostprocessorがあります。これは、デコーダの出力を特定の特徴に後処理するために使用できます。
まず、Perceiverがテキストでどのように実装されるかを示しましょう。
テキスト用のPerceiver
Perceiverを使用してテキスト分類を実行する場合を考えてみましょう。Perceiverのセルフアテンション機構のメモリと時間の要件は、入力のサイズに依存しませんので、生のUTF-8バイトをモデルに直接提供することができます。これは有益です。なぜなら、BERTやRoBERTaなどのよく知られたTransformerベースのモデルは、WordPiece、BPE、SentencePieceなどの明示的なトークン化方法を使用しているため、有害である可能性があるからです。BERT(シーケンス長512のサブワードトークンを使用する)との公平な比較のために、著者らは2048バイトの入力シーケンスを使用しました。バッチ次元も追加すると、モデルのinputsの形状は(バッチサイズ、2048)になります。 inputsには、テキストの1つの部分のバイトID(BERTのinput_idsに似ています)が含まれています。テキストを2048の長さにパディングされたバイトIDのシーケンスに変換するために、PerceiverTokenizerを使用できます:
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "hello world"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_idsこの場合、PerceiverTextPreprocessorをモデルの前処理器として提供し、inputs(つまり各バイトIDを対応するベクトルに変換し、絶対位置エンコーディングを追加する)を処理するようにします。デコーダとして、モデルにPerceiverClassificationDecoderを提供します(これは潜在変数の最後の隠れ状態を分類のログットに変換します)。後処理器は必要ありません。言い換えると、テキスト分類のためのPerceiverモデル(HuggingFace TransformersではPerceiverForSequenceClassificationと呼ばれる)は次のように実装されます:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)ここで、デコーダは訓練可能な位置エンコーディング引数で初期化されていることがわかります。なぜでしょうか?まあ、Perceiver IOの動作を詳細に見てみましょう。初期化時に、PerceiverModelは内部的に次のような潜在変数のセットを定義します:
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))Perceiver IOの論文では、256の潜在変数を使用し、潜在変数の次元を1280に設定しています。バッチ次元も追加すると、Perceiverの潜在変数の形状は(バッチサイズ、256、1280)になります。最初に、初期化時に提供する前処理器がUTF-8バイトIDを埋め込みベクトルに変換します。したがって、PerceiverTextPreprocessorは、(バッチサイズ、2048)の形状のinputsをテンソルの形状(バッチサイズ、2048、768)に変換します。各バイトIDがサイズ768のベクトルに変換されると仮定します(これはPerceiverConfigのd_model属性によって決まります)。
その後、Perceiver IOは、形状(バッチサイズ、256、1280)のラテント(クエリを生成する)と形状(バッチサイズ、2048、768)の前処理済み入力(キーと値を生成する)の間でクロスアテンションを適用します。この初期のクロスアテンション操作の出力は、クエリ(この場合はラテント)と同じ形状のテンソルです。つまり、クロスアテンション操作の出力は(バッチサイズ、256、1280)の形状です。
次に、自己注意層の(繰り返し可能な)ブロックが適用され、ラテントの表現が更新されます。これらは入力(つまりバイト)の長さに依存しないことに注意してください。これらはクロスアテンション操作中にのみ使用されました。Perceiver IOの論文では、テキストモデルのラテントの表現を更新するために、26個の自己注意層(それぞれが8つのアテンションヘッドを持つ)の単一のブロックが使用されました。これらの26個の自己注意層の後に出力されるテンソルの形状は、エンコーダーへの最初の入力と同じ形状であることに注意してください:(バッチサイズ、256、1280)。これらはまた、ラテントの「最後の隠れた状態」とも呼ばれます。これは、BERTに提供するトークンの「最後の隠れた状態」と非常に似ています。
では、最終的な隠れた状態の形状は(バッチサイズ、256、1280)です。素晴らしいですが、実際にはこれらを形状(バッチサイズ、num_labels)の分類ロジットに変換したいですよね。Perceiverはこれをどのように出力させることができるのでしょうか?
これは、「PerceiverClassificationDecoder」によって処理されます。アイデアは、入力をラテント空間にマッピングする際に行われたことと非常に似ています:クロスアテンションを使用するのです。ただし、今回はラテント変数がキーと値を生成し、任意の形状のテンソル(この場合は形状(バッチサイズ、1、num_labels)のテンソル)を提供します。このテンソルは、トレーニングの初めにランダムに初期化され、エンドツーエンドでトレーニングされます。見るように、ダミーのシーケンス長次元1を提供するだけです。QKVアテンション層の出力は常にクエリの形状と同じ形状を持つため、デコーダは形状(バッチサイズ、1、num_labels)のテンソルを出力します。その後、デコーダはこのテンソルを単純に形状(バッチサイズ、num_labels)に圧縮し、一気に形状(バッチサイズ、num_labels)の分類ロジットを得ます。
素晴らしいですね!Perceiverの著者はまた、BERTと同様にPerceiverをマスク言語モデリングのために事前学習することが容易であることも示しています。このモデルはHuggingFace Transformersでも利用可能であり、PerceiverForMaskedLMと呼ばれています。PerceiverForSequenceClassificationとの唯一の違いは、デコーダとしてPerceiverClassificationDecoderではなくPerceiverBasicDecoderを使用することです。これにより、ラテントを形状(バッチサイズ、2048、1280)のテンソルにデコードし、その後、言語モデリングヘッドを追加して形状(バッチサイズ、2048、vocab_size)のテンソルに変換します。Perceiverの語彙サイズは、256のUTF-8バイトIDと6つの特殊トークンのみであり、英語のWikipediaとC4でPerceiverを事前学習し、ファインチューニング後にGLUEで全体のスコア81.8を達成できることを著者は示しています。
画像のためのPerceiver
テキスト分類を実行するためにPerceiverを適用する方法を見てきましたが、画像分類を行うためにPerceiverを適用するのは非常に簡単です。唯一の違いは、モデルに異なる「preprocessor」を提供することで、これによって画像「inputs」が埋め込まれます。Perceiverの著者は実際に3つの異なる前処理方法を試しました:
- ピクセル値を平坦化し、カーネルサイズ1の畳み込み層を適用し、学習された絶対1D位置埋め込みを追加する。
- ピクセル値を平坦化し、固定の2Dフーリエ位置埋め込みを追加する。
- 2D畳み込み+最大プール層を適用し、固定の2Dフーリエ位置埋め込みを追加する。
これらの各々はTransformersライブラリで実装されており、それぞれPerceiverForImageClassificationLearned、PerceiverForImageClassificationFourier、PerceiverForImageClassificationConvProcessingと呼ばれています。これらはPerceiverImagePreprocessorの設定のみが異なります。では、PerceiverForImageClassificationLearnedについて詳しく見てみましょう。以下のようにPerceiverModelを初期化します:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverForImageClassificationLearned(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)PerceiverImagePreprocessorクラスは、prep_type = “conv1x1″として初期化され、学習可能な位置エンコーディングの引数が追加されています。このプリプロセッサは、詳細にどのように機能するのでしょうか?モデルに画像のバッチを提供すると仮定します。例えば、まず解像度224で中央クロッピングと色チャネルの正規化を適用し、inputsの形状が(batch_size, num_channels, height, width) = (batch_size, 3, 224, 224)となるとします。この場合、次のようにPerceiverFeatureExtractorを使用できます。
from transformers import PerceiverFeatureExtractor
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(image, return_tensors="pt").pixel_values上記で定義した設定のPerceiverImagePreprocessorは、まずカーネルサイズ(1, 1)の畳み込み層を適用して、inputsを形状(batch_size, 256, 224, 224)のテンソルに変換します。つまり、チャネル次元が増加します。次に、チャネル次元を最後に配置します。これにより、形状が(batch_size, 224, 224, 256)のテンソルが得られます。次に、空間の次元(高さ+幅)を平坦化し、形状が(batch_size, 50176, 256)のテンソルが得られます。次に、学習可能な1D位置エンコーディングと連結します。位置エンコーディングの次元数は256で定義されているため(上記のnum_channels引数を参照)、形状が(batch_size, 50176, 512)のテンソルが得られます。このテンソルは、ラテントとのクロスアテンション操作に使用されます。
著者は、すべての画像モデルに512のラテントを使用し、ラテントの次元を1024と設定しています。したがって、ラテントは形状が(batch_size, 512, 1024)のテンソルです(バッチ次元を追加する場合)。クロスアテンション層は、クエリの形状が(batch_size, 512, 1024)であり、キー+値の形状が(batch_size, 50176, 512)であるものを入力として受け取ります。そして、クエリと同じ形状のテンソルを出力するため、形状が(batch_size, 512, 1024)の新しいテンソルを生成します。次に、6つのセルフアテンション層のブロックが反復的に適用され(8回)、形状が(batch_size, 512, 1024)の最終的なラテントの隠れ状態が生成されます。これらを分類のロジットに変換するには、テキスト分類用のものと同様にPerceiverClassificationDecoderが使用されます。このデコーダは、ラテントをキー+値として使用し、形状が(batch_size, 1, num_labels)の学習可能な位置エンコーディングをクエリとして使用します。クロスアテンション操作の出力は、形状が(batch_size, 1, num_labels)のテンソルであり、これは形状が(batch_size, num_labels)の分類のロジットに圧縮されます。
Perceiverの著者は、このモデルが画像分類のために主に設計されたモデル(ResNetやViTなど)と比較して強力な結果を達成できることを示しています。JFTでの大規模な事前学習の後、conv+maxpoolのプリプロセッシングを使用したモデル(PerceiverForImageClassificationConvProcessing)はImageNetで84.5のトップ1精度を達成します。驚くべきことに、2D構造の画像に関する特権的な情報を持たないにもかかわらず、完全に学習された1D位置エンコーディングのモデル(PerceiverForImageClassificationLearned)は、トップ1精度72.7を達成します。
光流のためのパーシーバー
著者は、光流に対してもパーシーバーを使用することが容易であることを示しています。光流は、コンピュータビジョンの数十年前からの問題であり、さまざまな広範な応用があります。光流の紹介については、このブログ投稿を参照してください。同じシーンの2つの画像(例:ビデオの連続フレームの2つ)が与えられた場合、最初の画像の各ピクセルの2D変位を推定するタスクです。既存のアルゴリズムはかなり手作業で設計されており、複雑ですが、パーシーバーを使用すると比較的簡単になります。このモデルはTransformersライブラリで実装され、PerceiverForOpticalFlowとして利用できます。実装は以下のようになります:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)上記のコードでは、PerceiverImagePreprocessorがプリプロセッサとして使用され(つまり、潜在変数とのクロスアテンション操作のために2つの画像を準備するために使用され)、PerceiverOpticalFlowDecoderがデコーダとして使用されます(つまり、潜在変数の最終的な隠れ状態を実際の予測フローにデコードするために使用されます)。各フレームに対して、著者は各ピクセルの周囲に3 x 3のパッチを抽出し、各ピクセルに対して3 x 3 x 3 = 27の値を生成します(各ピクセルには3つのカラーチャンネルもあります)。著者はトレーニング解像度を(368, 496)として使用しています。トレーニングの各例ごとにサイズが(368, 496)の2つのフレームを上下に積み重ねると、モデルへのinputsの形状は(batch_size, 2, 27, 368, 496)になります。
上記で定義された設定を持つプリプロセッサは、最初にフレームをチャネル次元に沿って連結し、形状が(batch_size, 368, 496, 54)のテンソルを生成します(チャネル次元も最後に移動すると仮定しています)。著者は論文(8ページ)で、チャネル次元に沿った連結が意味を持つ理由を説明しています。次に、空間次元がフラット化され、形状が(batch_size, 368*496, 54) = (batch_size, 182528, 54)のテンソルが生成されます。次に、位置エンベディング(各エンベディングの次元は258)が連結され、最終的なプリプロセスされた入力の形状が(batch_size, 182528, 322)になります。これらは、潜在変数とのクロスアテンションを実行するために使用されます。
著者は光流モデルに2048の潜在変数を使用しています(はい、2048です!)。各潜在変数の次元は512です。したがって、潜在変数の形状は(batch_size, 2048, 512)になります。クロスアテンション後、潜在変数の埋め込みを更新するために、24個のセルフアテンション層(各層には16個のアテンションヘッドがある)のブロックが適用されます。
潜在変数の最終的な隠れ状態を実際の予測フローにデコードするために、PerceiverOpticalFlowDecoderは単純に形状が(batch_size, 182528, 322)のプリプロセスされた入力をクロスアテンション操作のクエリとして使用します。次に、これらは形状が(batch_size, 182528, 2)のテンソルに投影されます。最後に、これをオリジナルの画像サイズに再スケールし、形状が(batch_size, 368, 496, 2)の予測フローを取得します。著者は、AutoFlowでトレーニングされた大規模な合成データセットである400,000の注釈付き画像ペアを使用して、SintelやKITTIなどの重要なベンチマークで最先端の結果を提供していると主張しています。
以下のビデオは、2つの例で予測されたフローを示しています。

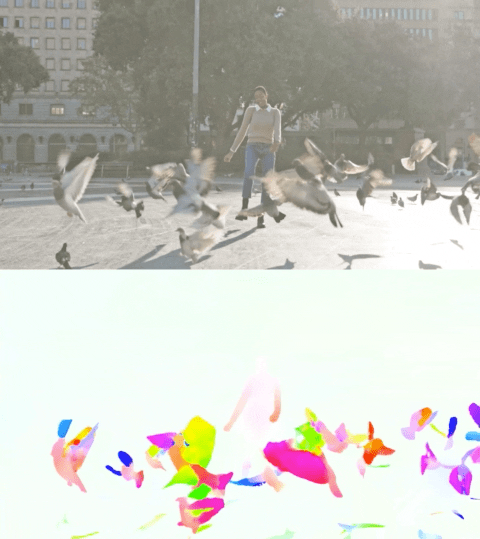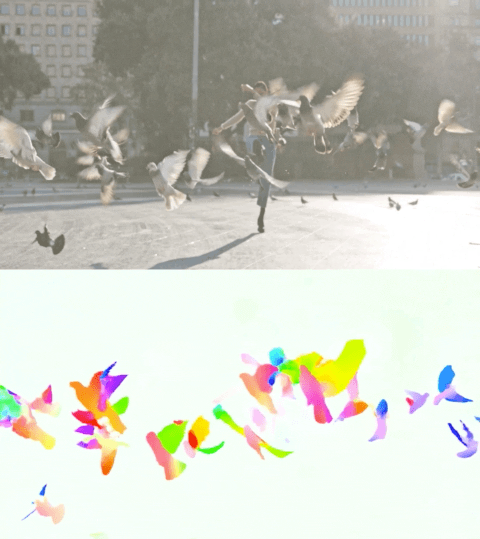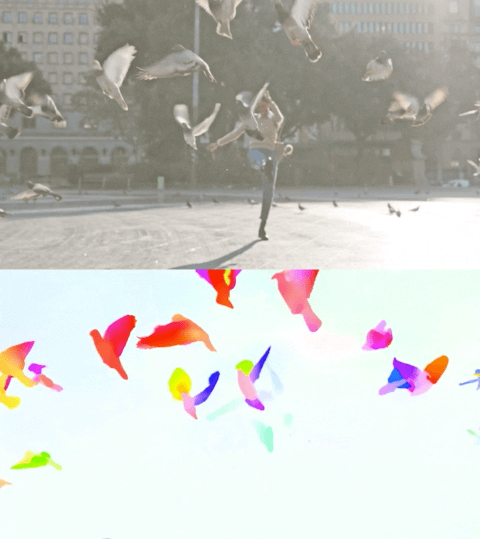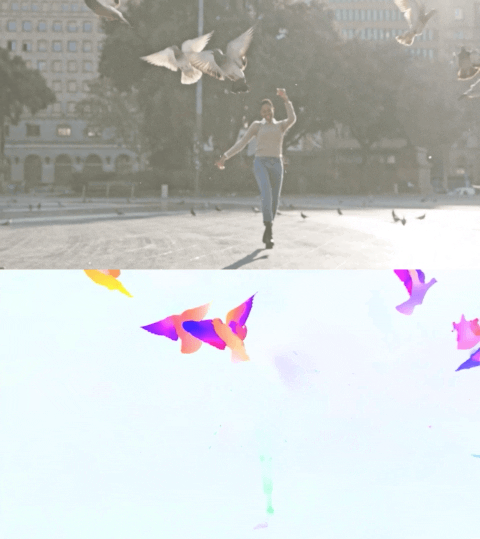

Perceiver IOによる光流の推定。各ピクセルの色はモデルによって推定された運動の方向と速度を示し、右側の凡例に示されています。
マルチモーダル自己符号化のためのPerceiver
著者はまた、Perceiverをマルチモーダル自己符号化に使用しています。マルチモーダル自己符号化の目標は、アーキテクチャによって引き起こされるボトルネックの存在下で、マルチモーダル入力を正確に再構築できるモデルを学習することです。著者はKinetics-700データセットでモデルをトレーニングしました。このデータセットでは、各例は画像(つまりフレーム)のシーケンス、音声、およびクラスラベル(700種類の可能なラベルの1つ)から構成されます。このモデルはHuggingFace Transformersでも実装されており、PerceiverForMultimodalAutoencodingとして利用できます。簡潔さのために、このモデルの定義のコードは省略しますが、重要な点はPerceiverMultimodalPreprocessorを使用してinputsをモデルのために準備するということです。このプリプロセッサは最初に各モダリティ(画像、音声、ラベル)のための対応するプリプロセッサをそれぞれ使用します。例えば、解像度が224×224の16フレームのビデオと30,720の音声サンプルを持つ場合、モダリティは次のように前処理されます:
- 画像は、(バッチサイズ、16、3、224、224)の形状の実際のフレームのシーケンスであり、
PerceiverImagePreprocessorを使用して(バッチサイズ、50176、243)の形状のテンソルに変換されます。これは「スペース→深さ」変換であり、その後に固定の2Dフーリエ位置埋め込みが連結されます。 - 音声は、(バッチサイズ、30720、1)の形状を持ち、
PerceiverAudioPreprocessorを使用して(バッチサイズ、1920、401)の形状のテンソルに変換されます(これには生の音声に固定のフーリエ位置埋め込みが連結されます)。 - クラスラベルは、(バッチサイズ、700)の形状を持ち、
PerceiverOneHotPreprocessorを使用して(バッチサイズ、1、700)の形状のテンソルに変換されます。言い換えると、このプリプロセッサは単純にダミーの時間(インデックス)次元を追加します。モデルをビデオ分類器として機能させるために、評価時にクラスラベルをゼロのテンソルで初期化することに注意してください。
次に、PerceiverMultimodalPreprocessorは、モダリティ固有の学習可能な埋め込みを使用して、時系列方向に沿って連結が可能になるように、前処理されたモダリティをパディングします。この場合、最もチャネル次元が高いモダリティはクラスラベルです(700チャネルあります)。著者は最小のパディングサイズを4とし、したがって各モダリティは704チャネルを持つようにパディングされます。それらは次に連結されるため、最終的な前処理済みの入力は(バッチサイズ、50176 + 1920 + 1、704)=(バッチサイズ、52097、704)の形状のテンソルです。
著者は784個の潜在変数を使用し、各潜在変数の次元は512です。したがって、潜在変数は(バッチサイズ、784、512)の形状を持ちます。クロスアテンションの後、クエリとして機能するため、同じ形状のテンソルが再び得られます。次に、8つの自己アテンション層(各層には8つのアテンションヘッドがあります)からなる単一のブロックが適用され、潜在変数の埋め込みが更新されます。
次に、PerceiverMultimodalDecoderがあります。このデコーダは最初に各モダリティに対して出力クエリを作成します。ただし、1回のフォワードパスで完全なビデオをデコードすることはできないため、著者は代わりにチャンクごとに自動エンコードします。各チャンクでは、各モダリティの特定のインデックス次元がサブサンプリングされます。例えば、ビデオを128個のチャンクで処理する場合、デコーダのクエリは次のように生成されます:
- 画像のモダリティでは、デコーダークエリの総サイズは16x3x224x224 = 802,816です。ただし、最初のチャンクを自動エンコードする際には、最初の802,816/128 = 6272の値をサブサンプルします。画像の出力クエリの形状は(batch_size, 6272, 195)であり、195は固定フーリエ位置埋め込みが使用されているためです。
- 音声のモダリティでは、合計の入力値は30,720です。しかし、最初の30720/128/16 = 15の値のみをサブサンプルします。したがって、音声クエリの形状は(batch_size, 15, 385)です。ここで、385は固定フーリエ位置埋め込みが使用されているためです。
- クラスラベルのモダリティでは、サブサンプルする必要はありません。したがって、サブサンプルされたインデックスは1に設定されます。ラベルの出力クエリの形状は(batch_size, 1, 1024)です。クエリにはサイズ1024のトレーニング可能な位置埋め込みが使用されます。
プリプロセッサと同様に、PerceiverMultimodalDecoderは、モダリティ固有のクエリを時間の次元に沿って連結できるように、異なるモダリティを同じチャネル数にパディングします。ここでは、クラスラベルが再び最も多くのチャネル数(1024)を持ち、著者は最小パディングサイズを2として強制するため、すべてのモダリティは1026のチャネルを持つようにパディングされます。連結後、最終的なデコーダークエリの形状は(batch_size, 6272 + 15 + 1, 1026) = (batch_size, 6288, 1026)となります。このテンソルはクロスアテンション操作でクエリを生成し、潜在変数はキーと値として機能します。したがって、クロスアテンション操作の出力は形状が(batch_size, 6288, 1026)のテンソルです。次に、PerceiverMultimodalDecoderは、出力チャネルを減らすために線形層を使用して形状が(batch_size, 6288, 512)のテンソルを生成します。
最後に、PerceiverMultimodalPostprocessorがあります。このクラスは、デコーダーの出力を各モダリティの実際の再構成に後処理します。まず、デコーダーの出力の時間次元を異なるモダリティに応じて分割します:画像の場合は形状が(batch_size, 6272, 512)のテンソル、音声の場合は形状が(batch_size, 15, 512)のテンソル、クラスラベルの場合は形状が(batch_size, 1, 512)のテンソルです。次に、各モダリティの対応する後処理が適用されます:
- 画像の後処理(Transformersでは
PerceiverProjectionPostprocessorと呼ばれる)は単純に(batch_size, 6272, 512)のテンソルを形状が(batch_size, 6272, 3)のテンソルに変換します。つまり、最終次元をRGB値にプロジェクトします。 PerceiverAudioPostprocessorは(batch_size, 15, 512)のテンソルを形状が(batch_size, 240)のテンソルに変換します。PerceiverClassificationPostprocessorは最初の(そして唯一の)インデックスを取り、形状が(batch_size, 700)のテンソルを取得します。
これにより、それぞれのモダリティの再構成を含むテンソルが得られます。ビデオ全体をチャンクごとに自動エンコードするため、各チャンクの再構成を連結してビデオ全体の最終的な再構成を得る必要があります。以下に例を示します:



上:元のビデオ(左)、最初の16フレームの再構成(右)。ビデオはUCF101データセットから取得されたものです。下:再構成された音声(論文から取得)。

上記ビデオの予測されたトップ5のラベル。クラスラベルをマスキングすることで、Perceiverはビデオ分類器になります。
このアプローチにより、モデルは3つのモダリティ間の共同分布を学習します。著者は、潜在変数がモダリティ間で共有され、明示的に割り当てられていないため、各モダリティの再構成の品質は、損失項の重みと他のトレーニングハイパーパラメータに対して敏感であることに注意しています。分類精度に重点を置くことで、ビデオのトップ1精度が45%でありながら、20.7 PSNR(ピーク信号対雑音比)を維持できます。
Perceiverの他の応用
Perceiverの応用は制限されていません!オリジナルのPerceiverの論文では、著者らがアーキテクチャを使用して、Lidarセンサを搭載した自動運転車の共通の懸念である3Dポイントクラウドの処理に使用できることを示しています。彼らはModelNet40というデータセットを使用してモデルをトレーニングしました。これは、40のオブジェクトカテゴリをカバーする3D三角メッシュから派生したポイントクラウドのデータセットです。このモデルは、テストセットで85.7%のトップ1精度を達成し、PointNet++と競合する結果となりました。PointNet++は、追加の幾何学的特徴を使用し、より高度な拡張を行う高度に特化したモデルです。
著者らはまた、PerceiverをAlphaStarというStarCraft IIという複雑なゲームの最先端の強化学習システムでオリジナルのTransformerの代わりに使用しました。追加のパラメータを調整せずに、著者らは、生成されたエージェントがオリジナルのAlphaStarエージェントと同じレベルのパフォーマンスに到達し、人間のデータに対する行動複製後にEliteボットに対して87%の勝率を達成したことを観察しました。
重要なことは、現在実装されているモデル(例:PerceiverForImageClassificationLearned、PerceiverForOpticalFlow)は、Perceiverでできることの例に過ぎないということです。これらは、PerceiverModelの異なるインスタンスであり、異なるプリプロセッサと/またはデコーダ(およびオプションで、マルチモーダル自己符号化の場合はポストプロセッサ)を持っています。人々は新しいプリプロセッサ、デコーダ、ポストプロセッサを考案して、モデルが異なる問題を解決することができます。例えば、Perceiverを拡張してBERTに似た名前エンティティ認識(NER)や質問応答、Wav2Vec2に似た音声分類、DETRに似た物体検出などを行うことができます。
結論
このブログ投稿では、Google DeepmindのPerceiverの拡張であるPerceiver IOのアーキテクチャについて説明し、それがあらゆるモダリティを扱う汎用性を示しました。Perceiverの大きな利点は、自己注意メカニズムの計算およびメモリ要件が入出力のサイズに依存せず、計算の大部分が潜在空間(あまり大きくないベクトルのセット)で行われることです。タスクに依存しないアーキテクチャにもかかわらず、このモデルは言語、ビジョン、マルチモーダルデータ、およびポイントクラウドなどのモダリティで素晴らしい結果を達成する能力があります。将来的には、複数のモダリティに対して単一(共有)のPerceiverエンコーダをトレーニングし、モダリティ固有のプリプロセッサとポストプロセッサを使用することも興味深いかもしれません。Karpathyの言葉で言えば、このアーキテクチャはすべてのモダリティを共有空間に統一し、エンコーダ/デコーダのライブラリを持つことができるかもしれません。
ライブラリについて言えば、このモデルは本日からHuggingFace Transformersで利用可能です。このモデルを使用して何を構築するかが楽しみです。その応用は無限大のようです!
付録
HuggingFace Transformersでの実装は、こちらで見つけることができるオリジナルのJAX/Haiku実装に基づいています。
HuggingFace TransformersでのPerceiver IOモデルのドキュメントは、こちらで利用可能です。
複数のモダリティに関するPerceiverのチュートリアルノートブックは、こちらで見つけることができます。
脚注
1 公式論文では、出力ロジットを生成するために2層のMLPを使用していますが、簡潔さのためにここでは省略しました。 ↩︎
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ZeROを使用して、DeepSpeedとFairScaleを介してより多くのフィットと高速なトレーニングを実現
- Hugging Face Transformersでより高速なTensorFlowモデル
- PyTorch / XLA TPUsでのHugging Face
- Huggingface TransformersとRayを使用した検索増強生成
- シンプルな人々が派手なニューラルネットワークを構築するための簡単な考慮事項
- ハギングフェイスの読書会、2021年2月 – Long-range Transformers
- Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する





