PatchTST 時系列予測における画期的な技術革新
PatchTST Innovative technological revolution in time series prediction.
理論から実践まで、PatchTSTアルゴリズムを理解し、N-BEATSとN-HiTSと共にPythonで適用する
トランスフォーマーを使ったモデルは、自然言語処理(BERTやGPTモデルなど)やコンピュータビジョンなど、多くの分野で成功を収めています。
しかし、時系列に関しては、N-BEATSやN-HiTSなどのMLPモデル(多層パーセプトロン)が主に最先端の成果を出しています。実際、最近の論文では、単純な線形モデルが多くのベンチマークデータセットで複雑なトランスフォーマーベースの予測モデルを上回ることが示されています(Zheng et al., 2022)。
それでも、長期予測タスクで最先端の成果を出している新しいトランスフォーマーベースのモデルが提案されています:PatchTST。
PatchTSTは、パッチ時系列トランスフォーマーを表しており、Nie、Nguyenらによって2023年3月に提案された論文「A Time Series is Worth 64 Words: Long-Term Forecasting with Transformers」で初めて紹介されました。彼らの提案手法は、他のトランスフォーマーベースのモデルと比較して最先端の成果を出しました。
- レトロなデータサイエンス:YOLOの最初のバージョンのテスト
- SeabornとMatplotlibを使用して美しい年齢分布グラフを作成する方法(アニメーションを含む)
- MIT-Pillar AI Collectiveが初めてのシードグラント受賞者を発表
この記事では、PatchTSTの内部動作を最初に直感的に、方程式なしで説明します。次に、モデルを予測プロジェクトに適用し、N-BEATSやN-HiTSなどのMLPモデルと比較して性能を評価します。
もちろん、PatchTSTの詳細については、元の論文を参照してください。
私の無料のPythonの時系列チートシートで最新の時系列解析技術を学びましょう!統計的および深層学習技術の実装をすべてPythonとTensorFlowで手に入れましょう!
それでは、始めましょう!
PatchTSTの探索
先に述べたように、PatchTSTはパッチ時系列トランスフォーマーを表しています。
その名前が示すように、パッチングとトランスフォーマーアーキテクチャを使用しています。また、多変量時系列を処理するためのチャネル独立性も含まれています。一般的なアーキテクチャは以下の通りです。
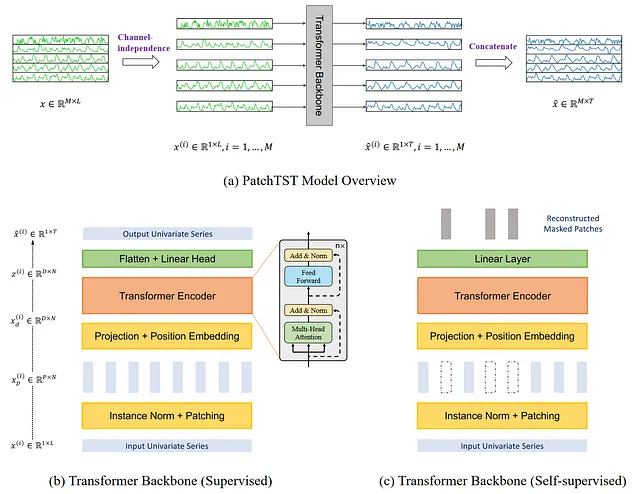
上記の図から多くの情報を収集することができます。ここで、キー要素は、PatchTSTがチャネル独立性を使用して多変量時系列を予測することです。そして、トランスフォーマーバックボーンでは、小さな垂直の長方形で示されるパッチングが使用されます。また、モデルには監視付きと自己監視の2つのバージョンがあります。
次に、PatchTSTのアーキテクチャと内部動作を詳しく探索してみましょう。
チャネル独立性
ここでは、多変量時系列を多チャネル信号として考えます。各時系列は、信号を含むチャネルとして表されます。
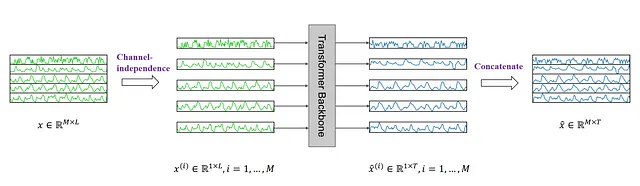
上の図では、多変量時系列が個々の系列に分割され、各系列がトークン入力としてTransformerバックボーンに送信されることが示されています。そして、各系列に対して予測が行われ、結果が連結されて最終的な予測が行われます。
パッチング
Transformerベースの予測モデルに関するほとんどの研究は、元のAttentionメカニズムを簡素化する新しいメカニズムの構築に焦点を当てています。しかし、時系列の場合、それらはまだポイントワイズアテンションに依存しており、時系列には理想的ではありません。
時系列の予測では、過去の時間ステップと未来の時間ステップの間の関係を抽出して予測することを目的としています。ポイントワイズアテンションでは、周囲のポイントを見ないで単一の時間ステップから情報を取得しようとしています。言い換えると、時間ステップを孤立させて前後のポイントを見ないで情報を取得しようとしています。
これは、文中の周囲の単語を見ないで単語の意味を理解しようとするのと同じです。
そのため、PatchTSTは、時系列のローカルな意味情報を抽出するためにパッチングを使用します。
パッチングの仕組み
各入力系列は、単に元の系列から来た短い系列であるパッチに分割されます。

ここでは、パッチは重複している場合と重複していない場合の両方があります。パッチの数は、パッチの長さPとストライドSの長さに依存します。ここでは、ストライドは畳み込みと同じであり、連続するパッチの開始をいくつの時間ステップが分離しているかを示します。
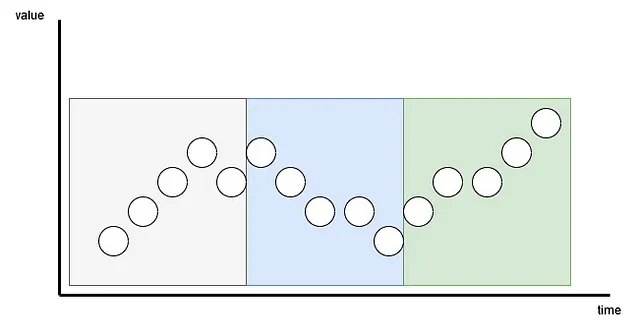
上の図では、パッチングの結果を視覚化することができます。ここでは、シーケンスの長さ( L )が15のタイムステップで、パッチの長さ( P )が5、ストライド( S )が5です。結果は、系列が3つのパッチに分割されていることです。
パッチングの利点
パッチングを使用することで、モデルは、単一の時間ステップではなく、時間ステップのグループを見てローカルな意味を抽出することができます。
また、トークンの数を大幅に減らすことができます。ここでは、各パッチがTransformerに入力されるトークンになります。そのため、トークンの数を L から約 L/S に減らすことができます。
これにより、モデルのスペースと時間の複雑さを大幅に削減することができます。これにより、意味のある時間的な関係を抽出するためにモデルに長い入力シーケンスを与えることができます。
したがって、パッチングにより、モデルは速く、軽くなり、より長い入力シーケンスを扱うことができるため、系列についてより多くのことを学び、より良い予測を行うことができます。
Transformerエンコーダ
系列がパッチに分割された後、Transformerエンコーダに送信されます。これはクラシックなTransformerアーキテクチャです。何も変更されていません。
その後、出力は線形層に送信され、予測が行われます。
表現学習を用いたPatchTSTの改善
論文の著者たちは、表現学習を使用することでモデルを改善する別の提案をしました。
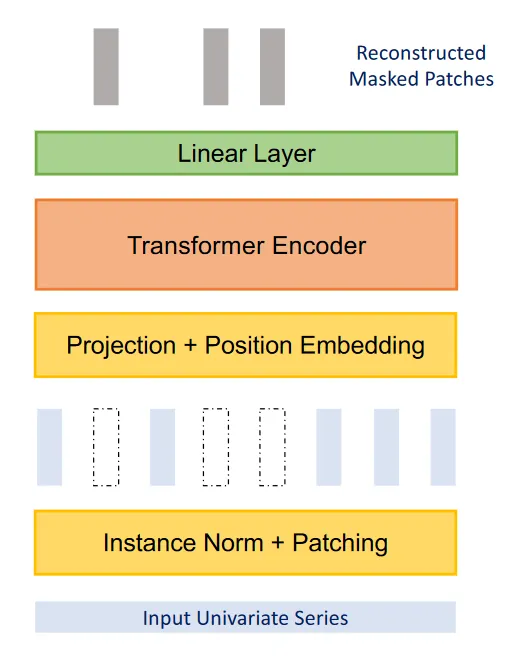
上記の図から、PatchTSTは自己教師あり表現学習を使用して、データの抽象的な表現を捉えることができることがわかります。これは、予測性能の潜在的な改善につながる可能性があります。
ここでは、プロセスはかなりシンプルで、ランダムにパッチがマスクされます。つまり、それらは0に設定されます。これは、図の垂直の空白の長方形で示されています。その後、モデルは元のパッチを再作成するようにトレーニングされます。これが図の上部に出力されるもので、灰色の垂直の長方形です。
これで、PatchTSTがどのように機能するかをよく理解したので、他のモデルと比較して、どのように機能するかをテストしてみましょう。
PatchTSTを用いた予測
論文では、PatchTSTは他のTransformerベースのモデルと比較されています。しかし、最近ではN-BEATSやN-HiTSなどのMLPベースのモデルも公開されており、長期予測タスクで最先端の性能を発揮しています。
このセクションの完全なソースコードはGitHubで利用可能です。
ここでは、PatchTST、N-BEATS、N-HiTSを適用し、これら2つのMLPベースのモデルと比較してその性能を評価します。
この演習では、調査における長期予測の共通ベンチマークデータセットであるExchangeデータセットを使用します。データセットには、1990年から2016年までの米ドルに対する8つの国の日次為替レートが含まれています。データセットはMITライセンスによって提供されています。
初期設定
必要なライブラリをインポートすることから始めましょう。ここでは、neuralforecastを使用します。これは、PatchTSTのすぐに使用できる実装を提供しています。データセットには、予測アルゴリズムを評価するためのすべての一般的なデータセットが含まれるdatasetsforecastライブラリを使用します。
import torchimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom neuralforecast.core import NeuralForecastfrom neuralforecast.models import NHITS, NBEATS, PatchTSTfrom neuralforecast.losses.pytorch import MAEfrom neuralforecast.losses.numpy import mae, msefrom datasetsforecast.long_horizon import LongHorizonCUDAがインストールされている場合は、neuralforecastは自動的にGPUを利用してモデルをトレーニングします。私の場合、それがインストールされていないので、私は大規模なデータセットでの広範なハイパーパラメータチューニングやトレーニングを行っていません。
それが完了したら、Exchangeデータセットをダウンロードしましょう。
Y_df、X_df、S_df = LongHorizon.load(directory="./data", group="Exchange")ここでは、3つのデータフレームが得られることがわかります。最初のものには、各国の日次為替レートが含まれています。2番目のものには外因性時系列が含まれています。3番目のものには、静的外因性変数が含まれています(日、月、年、時など、将来の情報を含みます)。
この演習では、Y_dfのみを使用します。
次に、日付が正しいタイプであることを確認しましょう。
Y_df['ds'] = pd.to_datetime(Y_df['ds'])Y_df.head()
上記の図では、3つの列があることがわかります。最初の列はユニークな識別子であり、neuralforecastを使う場合にはid列が必要です。次に、ds列には日付、y列には為替レートがあります。
Y_df['unique_id'].value_counts()
上の図から、各ユニークなIDが国に対応していること、そして国ごとに7588の観測があることがわかります。
次に、検証セットとテストセットのサイズを定義します。ここでは、datasetsライブラリによって指定されたように、検証に760の時間ステップ、テストに1517の時間ステップを選びました。
val_size = 760test_size = 1517print(n_time, val_size, test_size)次に、シリーズの1つをプロットして、何を扱っているかを確認しましょう。ここでは、最初の国(unique_id=0)のシリーズをプロットすることにしましたが、別のシリーズをプロットしても構いません。
u_id = '0'x_plot = pd.to_datetime(Y_df[Y_df.unique_id==u_id].ds)y_plot = Y_df[Y_df.unique_id==u_id].y.valuesx_plotx_val = x_plot[n_time - val_size - test_size]x_test = x_plot[n_time - test_size]fig, ax = plt.subplots(figsize=(12,8))ax.plot(x_plot, y_plot)ax.set_xlabel('Date')ax.set_ylabel('Exhange rate')ax.axvline(x_val, color='black', linestyle='--')ax.axvline(x_test, color='black', linestyle='--')plt.text(x_val, -2, 'Validation', fontsize=12)plt.text(x_test,-2, 'Test', fontsize=12)plt.tight_layout()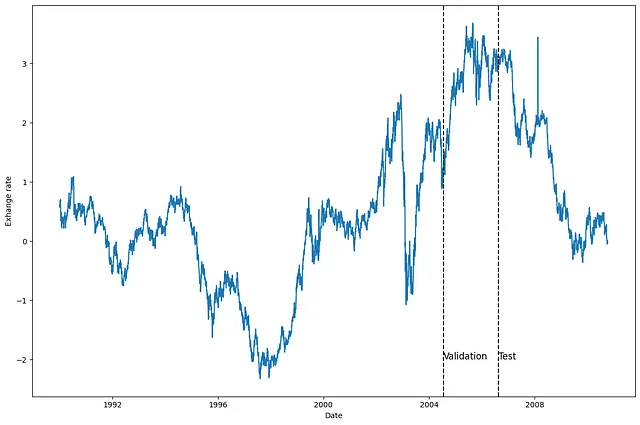
上の図から、明確な季節性のない、かなりノイズの多いデータがあることがわかります。
モデリング
データを探索した後、neuralforecastを使ってモデリングを始めましょう。
まず、予測期間を設定する必要があります。この場合、私は96の時間ステップを使用しました。これは、PatchTST論文でも使用されている期間です。
次に、各モデルの公正な評価を行うために、入力サイズを予測期間の2倍(つまり192の時間ステップ)に設定し、最大エポック数を50に設定しました。その他のハイパーパラメータはデフォルト値のままです。
horizon = 96models = [NHITS(h=horizon, input_size=2*horizon, max_steps=50), NBEATS(h=horizon, input_size=2*horizon, max_steps=50), PatchTST(h=horizon, input_size=2*horizon, max_steps=50)]そして、予測頻度を指定することで、NeuralForecastオブジェクトを初期化します。この場合は、日次の予測頻度です。
nf = NeuralForecast(models=models, freq='D')これで予測ができるようになりました。
予測
予測を生成するには、検証セットとテストセットを利用するためにcross_validationメソッドを使用します。すべてのモデルから予測と関連する真の値が含まれるDataFrameが返されます。
preds_df = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)
それぞれのidについて、各モデルからの予測値とyカラムの実際の値が表示されています。
では、モデルを評価するために、実際の値と予測値の配列を(number of series, number of windows, forecast horizon)の形状に変形する必要があります。
y_true = preds_df['y'].valuesy_pred_nhits = preds_df['NHITS'].valuesy_pred_nbeats = preds_df['NBEATS'].valuesy_pred_patchtst = preds_df['PatchTST'].valuesn_series = len(Y_df['unique_id'].unique())y_true = y_true.reshape(n_series, -1, horizon)y_pred_nhits = y_pred_nhits.reshape(n_series, -1, horizon)y_pred_nbeats = y_pred_nbeats.reshape(n_series, -1, horizon)y_pred_patchtst = y_pred_patchtst.reshape(n_series, -1, horizon)これで、モデルの予測をプロットすることもできます。ここでは、最初のシリーズの最初のウィンドウの予測をプロットしています。
fig, ax = plt.subplots(figsize=(12,8))ax.plot(y_true[0, 0, :], label='True')ax.plot(y_pred_nhits[0, 0, :], label='N-HiTS', ls='--')ax.plot(y_pred_nbeats[0, 0, :], label='N-BEATS', ls=':')ax.plot(y_pred_patchtst[0, 0, :], label='PatchTST', ls='-.')ax.set_ylabel('Exchange rate')ax.set_xlabel('Forecast horizon')ax.legend(loc='best')plt.tight_layout()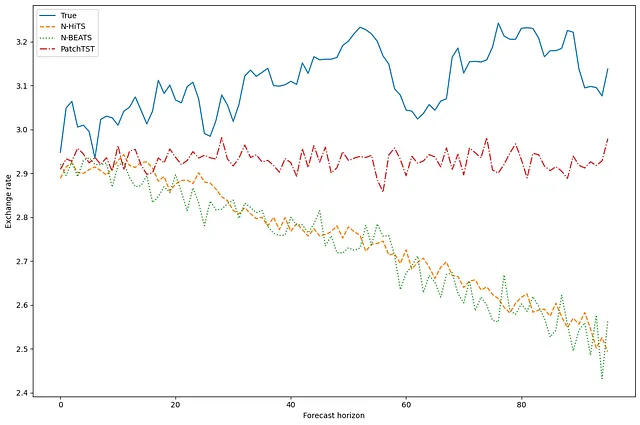
この図はあまり目立ちません。N-BEATSとN-HiTSの予測値は実際の値からかなり外れているようです。しかし、PatchTSTは外れているものの、実際の値に最も近いようです。
もちろん、これは1つのシリーズ、1つの予測ウィンドウの予測値を可視化しているだけなので、注意が必要です。
評価
では、各モデルのパフォーマンスを評価しましょう。論文から方法論を再現するために、MAEとMSEの両方をパフォーマンスメトリックとして使用します。
data = {'N-HiTS': [mae(y_pred_nhits, y_true), mse(y_pred_nhits, y_true)], 'N-BEATS': [mae(y_pred_nbeats, y_true), mse(y_pred_nbeats, y_true)], 'PatchTST': [mae(y_pred_patchtst, y_true), mse(y_pred_patchtst, y_true)]}metrics_df = pd.DataFrame(data=data)metrics_df.index = ['mae', 'mse']metrics_df.style.highlight_min(color='lightgreen', axis=1)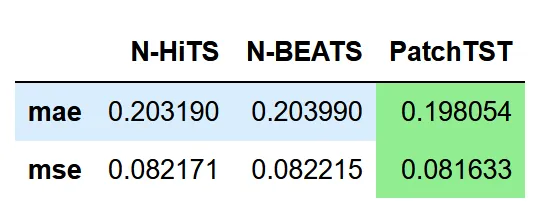
上の表では、PatchTSTが最も低いMAEとMSEを達成したため、チャンピオンモデルであることがわかります。
もちろん、これは非常に綿密な実験ではないため、1つのデータセットと1つの予測ウィンドウしか使用していません。それでも、Transformerベースのモデルが最新のMLPモデルと競合できることは興味深いことです。
結論
PatchTSTは、パッチングを使用して時系列データからローカルな意味を抽出するTransformerベースのモデルです。これにより、モデルのトレーニングがより高速になり、より長い入力ウィンドウを持つことができます。
他のTransformerベースのモデルと比較して、最先端の性能を発揮しています。私たちの小さな実験では、N-BEATSやN-HiTSよりも優れた性能を発揮したことも確認しました。
これは、N-HiTSやN-BEATSよりも優れているわけではありませんが、長期予測を行う際には興味深いオプションとなります。
読んでいただきありがとうございます!楽しんでいただけたか、新しいことを学べたかを願っています!
乾杯🍻
参考文献
“A Time Series is Worth 64 Words: Long-Term Forecasting with Transformers” by Nie Y., Nguyen N. et al.
“Neuralforecast” by Olivares K., Challu C., Garza F., Canseco M., Dubrawski A.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
