プロンプトエンジニアリングにおける並列処理:思考の骨格技術
美容とファッションの専門家が教える、鮮やかで活気溢れる世界への案内

キータケアウェイ
- 思考の骨組み(SoT)は、大型自然言語モデル(LLM)の生成レイテンシーを最小限に抑える革新的なプロンプトエンジニアリング技術であり、その効率を向上させます
- SoTは、回答の骨組みを作成し、それぞれのポイントを具体化することで、人間の思考を模倣し、より信頼性の高い、的確なAIの応答を促進します
- プロジェクトにSoTを導入することで、AIからの構造化された効率的な出力を要求するシナリオにおいて、問題解決と回答生成を大幅に迅速化することができます
SoTは、効率のためのデータ中心の最適化の初期試みであり、LLMが品質の高い回答を生成するために人間のように考える潜在能力を明らかにします。
イントロダクション
プロンプトエンジニアリングは、生成型AIの潜在能力を活用するための基盤です。効果的なプロンプトとプロンプトの書き方の方法を考案することで、AIにユーザーの意図を理解し、これらの意図に効果的に対応することができます。この領域で注目すべき技術の1つは、タスクに取り組む際やクエリに応答する際に、生成型AIモデルが論理をステップバイステップで解説することを指示する「思考の連鎖」(CoT)メソッドです。CoTを基にして、より信頼性の高く的確な応答を促進することを目指した有望な新しい手法である「思考の骨組み」(SoT)が登場しました。
思考の骨組みの理解
思考の骨組みの始まりは、大型言語モデル(LLM)に内在する生成レイテンシーを最小限に抑える試みから生まれました。順次デコーディングのアプローチとは異なる方法として、SoTはまず回答の骨組みを生成し、それから詳細を並列に補完することで、推論プロセスを大幅に高速化します。CoTと比較して、SoTは構造化された応答を促進するだけでなく、生成プロセスを効率的に組織化することで、生成型テキストシステムのパフォーマンスを向上させます。
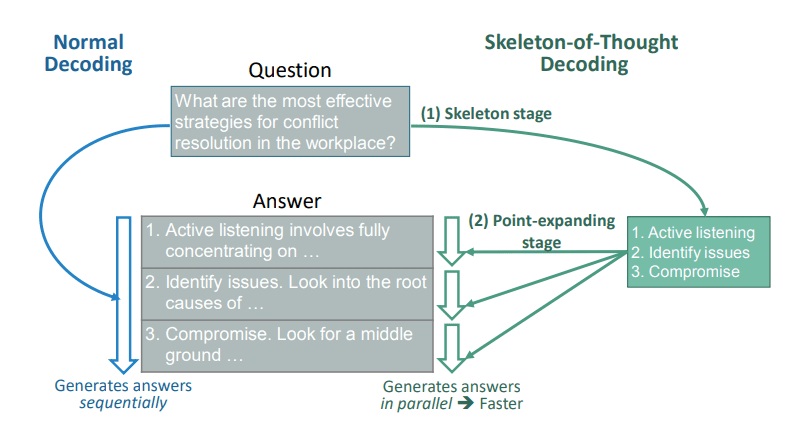
思考の骨組みの実装
上記のように、SoTを実装することは、LLMに問題解決や回答生成プロセスの骨組みを作成させ、その後、各ポイントについて並列に詳細を追加することを意味します。この方法は、AIからの効率的で構造化された出力が必要なシナリオに特に有用です。大規模なデータセットの処理や複雑なクエリに回答する場合、SoTはレスポンス時間を大幅に短縮し、効率的なワークフローを提供することができます。既存のプロンプトエンジニアリング戦略にSoTを統合することで、プロンプトエンジニアは生成型テキストのポテンシャルをより効果的かつ信頼性の高く迅速に活用することができます。
SoTを説明する最も良い方法は、例のプロンプトを示すことです。
例1
- 質問: 光合成のプロセスを説明してください。
- 骨組み: 光合成は植物で行われ、光エネルギーを化学エネルギーに変換し、ブドウ糖と酸素を作り出します。
- ポイントの詳細化: 光の吸収、葉緑素の役割、カルビン周期、酸素の放出について詳しく述べます。
例2
- 質問: 大恐慌の原因を説明してください。
- 骨組み: 大恐慌の原因は株式市場の暴落、銀行の倒産、消費支出の減少です。
- ポイントの詳細化: ブラックチューズデー、1933年の銀行危機、購買力の減少の影響について詳しく述べます。
これらの例は、SoTのプロンプトが複雑な質問に対する構造化されたステップバイステップのアプローチを容易にする方法を示しています。それはまた、ワークフローを示しています: 質問を提示するか目標を定義し、LLMに逆方向からの理論的な補助を含む広範な回答を与え、その理論的な補助を明示的に提示し、それをするようLLMに指示します。
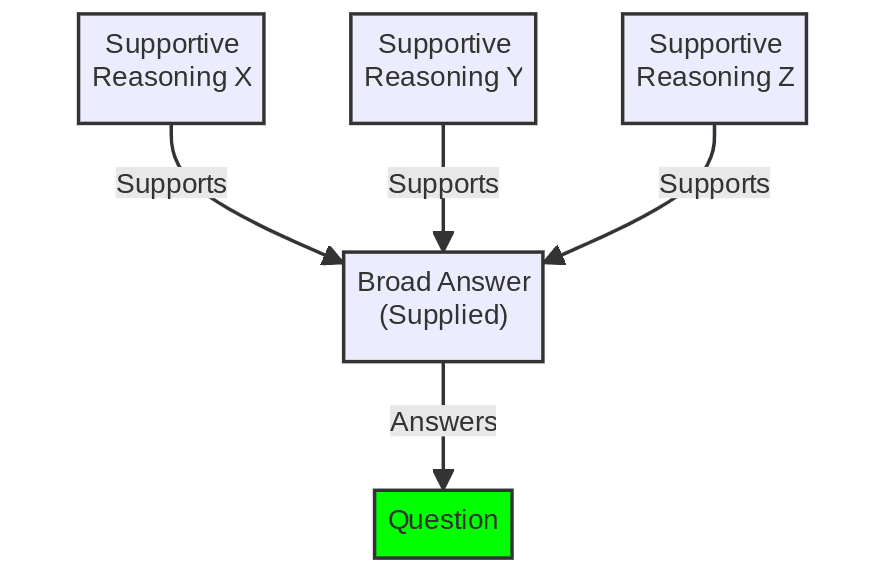
SoTは問題解決のための構造化されたアプローチを提供しますが、すべてのシナリオには適していない場合もあります。適切なユースケースの特定と実装の理解が重要です。さらに、順次処理から並行処理への移行にはシステム設計や追加リソースの変更が必要な場合もあります。ただし、これらの障害を乗り越えることで、SoTの潜在能力が生成テキストタスクの効率と信頼性の向上につながる可能性があります。
結論
CoTメソッドを基にしたSoTテクニックは、プロンプトエンジニアリングにおける新たなアプローチを提供します。生成プロセスを迅速化するだけでなく、構造化された信頼性のある出力を促進します。SoTをプロジェクトで探求し統合することで、実践者は生成テキストのパフォーマンスと使いやすさを大幅に向上させ、効率的かつ洞察に富んだソリューションに進むことができます。
Matthew Mayo (@mattmayo13)はコンピュータサイエンスの修士号とデータマイニングの大学院ディプロマを保持しています。VoAGIの編集長として、Matthewは複雑なデータサイエンスの概念をアクセス可能にすることを目指しています。彼の専門的な興味は、自然言語処理、機械学習アルゴリズム、新興AIの探求などです。彼はデータサイエンスコミュニティでの知識の民主化をミッションとしています。Matthewは6歳の時からコーディングをしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






