「Pandasによるデータクリーニング」
Pandasデータクリーニング

イントロダクション
もしデータサイエンスに興味があるなら、データクリーニングという言葉はおなじみかもしれません。もし知らない場合は、説明します。私たちのデータはしばしば複数のリソースから来ており、クリーンではありません。欠損値、重複、間違ったまたは望ましくない形式などが含まれているかもしれません。このような乱雑なデータで実験を実行すると、正確な結果が得られません。そのため、モデルにデータを供給する前にデータを準備する必要があります。これによって潜在的なエラー、不正確さ、不一致を特定し解決するデータの準備作業は、データクリーニングと呼ばれます。
このチュートリアルでは、Pandasを使用してデータのクリーニングプロセスを説明します。
データセット
有名なアヤメのデータセットを使用します。アヤメのデータセットには、アヤメの花の3つの種類(がくの長さ、がくの幅、花びらの長さ、花びらの幅)の4つの特徴量の測定値が含まれています。以下のライブラリを使用します:
- Pandas:データの操作と分析に強力なライブラリ
- Scikit-learn:データ前処理と機械学習のためのツールを提供
データクリーニングの手順
1. データセットの読み込み
Pandasのread_csv()関数を使用してアヤメのデータセットを読み込みます:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
出力:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
header=0パラメータは、CSVファイルの最初の行が列名(ヘッダー)を含んでいることを示しています。
2. データセットの探索
データセットについての洞察を得るために、pandasのビルトイン関数を使用していくつかの基本的な情報を表示します。
print(iris_data.info())
print(iris_data.describe())
出力:
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 150 non-null int64
1 sepal_length 150 non-null float64
2 sepal_width 150 non-null float64
3 petal_length 150 non-null float64
4 petal_width 150 non-null float64
5 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
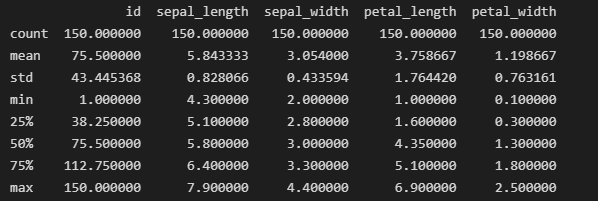
info()関数は、データフレームの全体的な構造、各列のノンヌル値の数、およびメモリ使用量を理解するために役立ちます。一方、サマリー統計量はデータセット内の数値的な特徴の概要を提供します。
3. クラスの分布を確認する
これは、分類の重要なタスクであるカテゴリカルな列におけるクラスの分布を理解するための重要なステップです。pandasのvalue_counts()関数を使用してこのステップを実行することができます。
print(iris_data['species'].value_counts())
出力:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
結果から、データセットが各種の表現に対して同数のバランスが取れていることがわかります。これにより、3つのクラス間で公平な評価と比較が可能になります。
4. 欠損値の削除
info()メソッドから明らかなように、欠損値のない列が5つあるため、このステップはスキップします。ただし、欠損値が見つかった場合は、以下のコマンドを使用してそれらを処理します。
iris_data.dropna(inplace=True)
5. 重複の削除
重複は分析を歪める可能性があるため、データセットから削除します。まず、以下のコマンドを使用してその存在を確認します。
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())
出力:
Number of duplicate rows: 0
このデータセットには重複がありません。ただし、重複はdrop_duplicates()関数を使用して削除できます。
iris_data.drop_duplicates(inplace=True)
6. ワンホットエンコーディング
カテゴリカルな分析のために、species列にワンホットエンコーディングを実行します。このステップは、機械学習アルゴリズムが数値データでより良く動作する傾向があるため実行されます。ワンホットエンコーディングプロセスは、カテゴリ変数をバイナリ(0または1)形式に変換します。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

7. 浮動小数点値の列の正規化
正規化は、数値特徴をスケーリングして平均が0、標準偏差が1になるようにするプロセスです。このプロセスは、特徴が分析に均等に寄与するようにするために行われます。一貫したスケーリングのために、浮動小数点値の列を正規化します。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
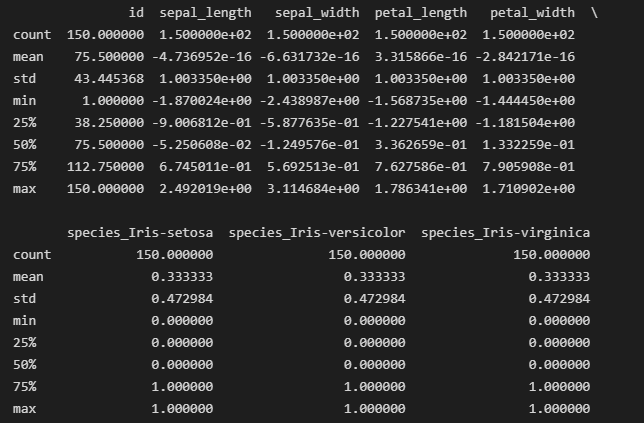
8. クリーンアップされたデータセットを保存する
クリーンアップされたデータセットを新しいCSVファイルに保存します。
iris_data.to_csv('cleaned_iris.csv', index=False)
まとめ
おめでとうございます!pandasを使用して最初のデータセットをクリーンアップすることに成功しました。複雑なデータセットを扱う際には、追加の課題に遭遇するかもしれません。しかし、ここで述べた基本的な技術は、分析のためのデータを準備するのに役立ちます。
Kanwal Mehreenは、データサイエンスと医療におけるAIの応用に強い関心を持つ、将来有望なソフトウェア開発者です。Kanwalは、2022年のGoogle Generation Scholar(APAC地域)に選ばれました。Kanwalは、トレンドのあるトピックについて記事を書くことで技術的な知識を共有することを楽しんでおり、テック業界における女性の代表性向上に情熱を持って取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
