vLLM:24倍速のLLM推論のためのPagedAttention
PagedAttention for vLLM LLM inference at 24x speed.
推論時にTransformerの注意力をより効率的に計算する方法
ほとんどの大型言語モデル(LLM)は、Transformerニューラルアーキテクチャに依存しています。このアーキテクチャは効率性が高く評価されていますが、いくつかの計算上のボトルネックがあります。
デコード中、これらのボトルネックの1つは、入力の各トークンのキー-バリューテンソルのペアでの注意力の計算にあります。これらのテンソルはすべてメモリに保存する必要があります。
注:本記事ではこれらのキー-バリューペアの役割については説明しません。これはTransformerアーキテクチャの最も複雑で興味深い側面の1つです。それについて知らない場合は、「The Illustrated Transformer by Jay Alammar」を読むことを強くお勧めします。
LLMが受け入れる入力が長くなるにつれて(例:LLM Claudeは100kトークンの長さの入力を受け入れます)、これらのテンソルによって消費されるメモリ量が非常に大きくなる可能性があります。
- 次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
- 2023年に知っておくべきトップ10のパワフルなデータモデリングツール
- 特徴量が多すぎる?主成分分析を見てみましょう
これらのテンソルを単純にすべてメモリに保存すると、メモリの過剰予約と断片化が発生します。この断片化により、特にトークンの長いシーケンスに対してメモリアクセスが非常に効率的でなくなることがあります。また、予約が過剰になると、システムはテンソルのために十分なメモリを割り当てたことを確認しますが、それがすべて消費されなくてもです。
これらの問題を軽減するために、UC BerkeleyはPagedAttentionを提案しています。
PagedAttentionは、UC Berkeleyの学生と教員によって設立されたオープンリサーチの組織であるLMSYSによって展開されているvLLM(Apache 2.0ライセンス)で実装されています。
本記事では、PagedAttentionが何であるか、およびなぜデコードを大幅に高速化するのかを説明し、vLLMでPagedAttentionを利用して自分のコンピュータでLLMの推論とサービングを開始する方法を紹介します。
TransformerのためのPagedAttention
Kwon et al. (2023)は、PagedAttentionを提案しています。
その目的は、GPU VRAMの非連続空間にキー-バリューテンソルをより効率的に保存することです。
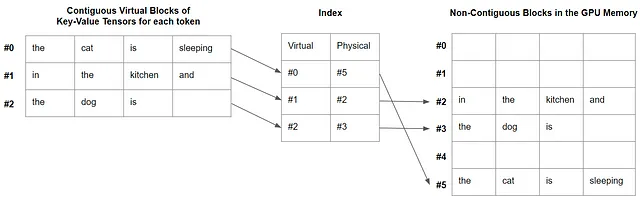
要するに、PagedAttentionのアイデアは、仮想的に連続したブロックを作成し、GPUメモリ内の物理的なブロックにマッピングすることです。
各ブロックは、あらかじめ定義されたトークン数のキー-バリューペアのテンソルを保存するように設計されています。すべてのブロックは仮想的に連続しており、断片化されたGPUメモリ内でオンデマンドで割り当てられる物理的に非連続なブロックにマップされます。単純なインデックステーブルもメモリに作成され、仮想ブロックと物理ブロックを関連付けます。
PagedAttentionのカーネルは、必要に応じてこれらのブロックをフェッチします。これは、ブロックのサイズが制限されているため、システムがキー-バリューテンソルの数をより少なくフェッチするため効率的です。
次のプロンプトを例に説明しましょう。
the cat is sleeping in the kitchen and the dog is
各トークンにはキー-バリューテンソルがあります。 PageAttentionを使用すると、ブロックサイズを任意に4に設定できます。各ブロックには4つのキー-バリューテンソルが含まれますが、最後のブロックには3つのキー-バリューテンソルしか含まれません。これらのブロックは仮想的に連続していますが、本記事のイントロダクションに示されている図のように、GPUメモリ内で必ずしも連続しているわけではありません。
注意の計算において、各クエリトークンについて、システムは以下のようにブロックを1つずつフェッチします。
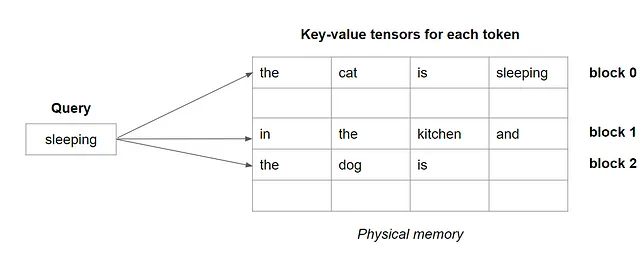
キー-バリューテンソルをブロックごとにフェッチすることで、テンソルのシーケンス全体をフェッチするよりも、注意力の計算がはるかに高速になります。
推論のための並列サンプリング
PagedAttentionの別の利点は、仮想ブロックを推論中にサンプリングする際に共有できることです。サンプリングまたはビームサーチによって並列に生成されたすべてのシーケンスは、重複を避けるために同じ仮想ブロックを使用できます。
LMSYSの実験では、ビームサーチデコーディングにおいてメモリ使用量が55%減少したことが観察されました。
LMSYSによるPagedAttentionのパフォーマンス
自分で試す前に、UC Berkely/LMSYSの著者がvLLMに実装されたPagedAttentionを使用した場合とHugging Faceによって開発されたテキスト生成推論ライブラリを使用した場合とを比較したときのパフォーマンスについて見てみましょう。
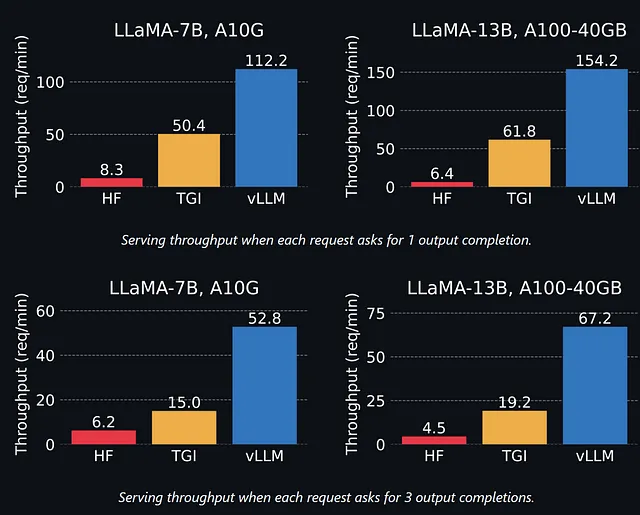
これらの結果によると、vLLMは特に複数の出力補完の場合、はるかに速いようです。TGIとvLLMの差は、モデルが大きくなるにつれて大きくなります。これは、大きなモデルほどメモリが必要であるため、メモリの断片化の影響をより受けるためです。
全体として、vLLMはHugging Face Transformersライブラリよりも最大24倍速いです。
注:実際に、私もHFからTGIへの改善に感銘を受けました。まだ私のブログではTGIについては取り上げていませんが、ガイドを書く予定です。TGIはHugging Faceで本番で使用されています。vLLMよりもはるかに遅いようですが、TGIにはより多くのモデルや機能のサポートなどの他の利点があります。
コンピューターでvLLMをセットアップする方法
注:vLLMはまだCUDA 12をサポートしていません。11.8などのより低いバージョンを使用してください。
このセクションでは、コンピューターでvLLMをセットアップして実行する方法の基本のみを説明します。より高度な使用については、vLLMのドキュメントを参照してください。
この記事を書いている時点では、vLLMは次のタイプのモデルのみをサポートしています:
- GPT-2
- GPT-NeoXおよびPythiaベース
- LLaMaベース
- OPTベース
これらの手順に従って他のモデルのサポートを追加できます。
以下のコードでは、Dolly V2(MITライセンス)を使用しています。これはPythiaに基づくチャットモデルで、DataBricksによってトレーニングされたものです。
私は、3兆のパラメータを持つ最も小さいバージョンを選びました。消費者向けGPUである24 GBのVRAMを搭載したnVidia RTX 3080/3090で実行できます。
vLLMをインストールする最も簡単な方法は、pipを使用することです:
pip install vllm注:これには最大10分かかる場合があります。
ただし、私の場合、コンピューターとGoogle Colabの両方で、pipがvllmライブラリをインストールできませんでした。vLLMの著者は、いくつかのnvccバージョンと環境に問題があることを確認しています。ただし、ほとんどの構成では、pipは問題なくvLLMをインストールするはずです。
私と同じ状況にある場合は、単純にDockerイメージを使用するという回避策があります。次のものが私の場合には動作しました:
docker run --gpus all -it --rm --shm-size=8g nvcr.io/nvidia/pytorch:22.12-py3注:Dockerに入った後、著者はvLLMをインストールする前にPytorchを削除することをお勧めします:pip uninstall torch。その後、「pip install vllm」が機能するはずです。
それでは、Pythonを書き始めましょう。
まず、vllmをインポートし、vllmでモデルをロードします。推論はllm.generate()によってトリガーされます。
from vllm import LLM
prompts = ["重力について教えてください"] #このリストにいくつかのプロンプトを入れることができます
llm = LLM(model="databricks/dolly-v2-3b") #モデルをロードする
outputs = llm.generate(prompts) #推論をトリガーする
vLLMを使用してLLMを提供することもできます。これはTGIと同様に機能します。以前の記事で説明したNVIDIA Triton推論サーバーを実行するよりもはるかにシンプルです。
まず、サーバーを起動する必要があります。
python -m vllm.entrypoints.openai.api_server --model databricks/dolly-v2-3b注意:サーバーはポート8000でリッスンします。利用可能であることを確認するか、vLLM構成ファイルで変更してください。
次に、次のようにしてプロンプトでサーバーに問い合わせることができます。
curl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "databricks/dolly-v2-3b", "prompt": "Tell me about gravity", "max_tokens": 200 }'以上です!非常に効率的なLLMサーバーがコンピュータ上で実行されています。
結論
PagedAttentionは推論を大幅に高速化します。これは、LLMによるより手頃なAIへのさらなる一歩です。
さらに実験で、vLLMはプロンプトのバッチに特に効率的であることが確認されました。vLLMを最大限に活用するには、推論のバッチング戦略を最適化することを検討してください。
大きなビームでのビームサーチは、標準的なアテンション計算では制限があったかもしれませんが、PagedAttentionを使用したビームサーチはより速く、メモリ効率が高くなります。
私の次の実験の1つは、QLoRaとPagedAttentionを組み合わせてメモリ使用量を減らすことです。これは簡単にできるはずです。これにより、消費者ハードウェアでのLLM実行がさらに効率的になります。
この記事が気に入った場合、次の記事を読みたい場合は、このリンクを使用してVoAGIメンバーになることが最もサポートされます:
VoAGIに私の紹介リンクで参加してください- Benjamin Marie
VoAGIメンバーとして、メンバーシップ料金の一部があなたが読んでいるライターに送られ、すべてのストーリーに完全にアクセスできます…
VoAGI.com
すでにメンバーで、この作業をサポートしたい場合は、VoAGIで私に従ってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
