AIの声 Voice Of AGI - Page 841
Word2Vec、GloVe、FastText、解説
コンピューターは我々と同じように単語を理解することができませんコンピューターは数字を扱うことが好きですですから、コンピューターが単語とその意味を理...

Boto3 vs AWS Wrangler PythonによるS3操作の簡素化
このチュートリアルでは、boto3とawswranglerの2つの強力なライブラリを探索し、比較することで、PythonによるAWS S3開発の世界に深く入り込んでいきます実際...
非教師あり学習シリーズ:階層クラスタリングの探索
前回の「教師なし学習シリーズ」の投稿では、最も有名なクラスタリング手法の1つであるK平均法クラスタリングについて探究しました今回の投稿では、別の手法...
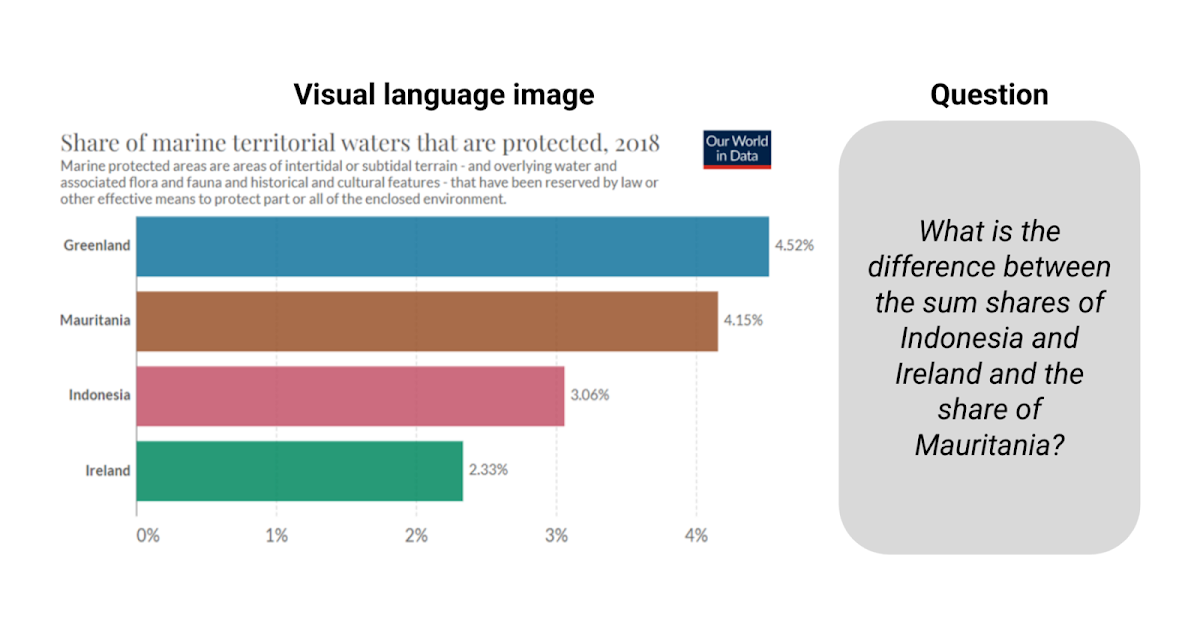
チャートの推論に基づくモデルの基盤
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を...
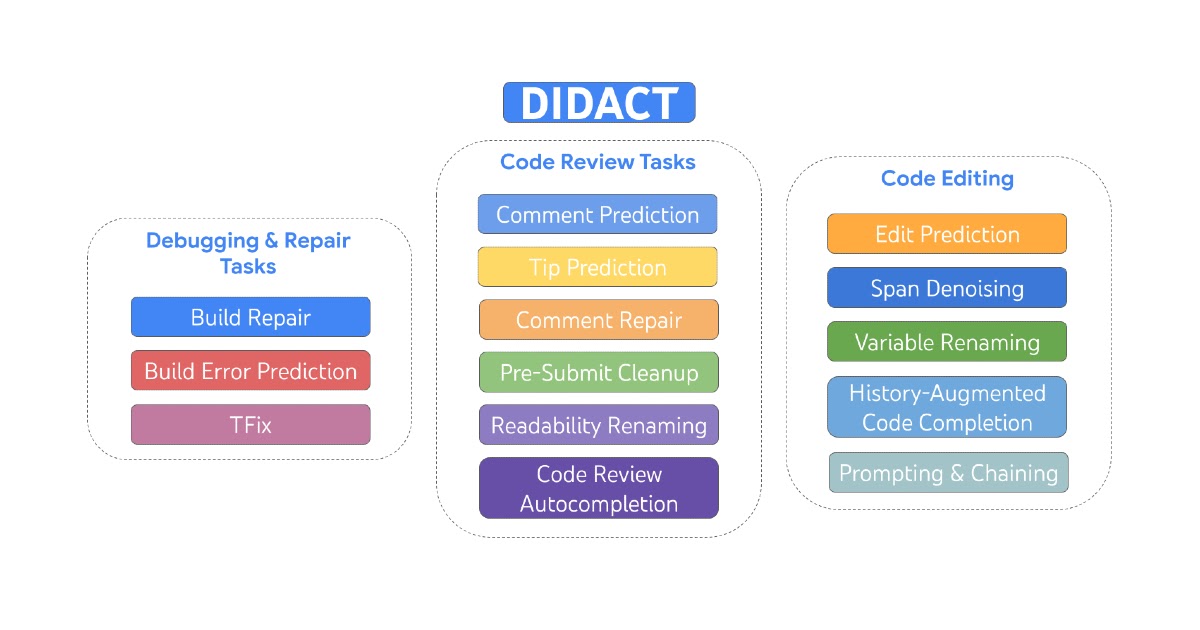
ソフトウェア開発活動のための大規模シーケンスモデル
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。 ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの...

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百...
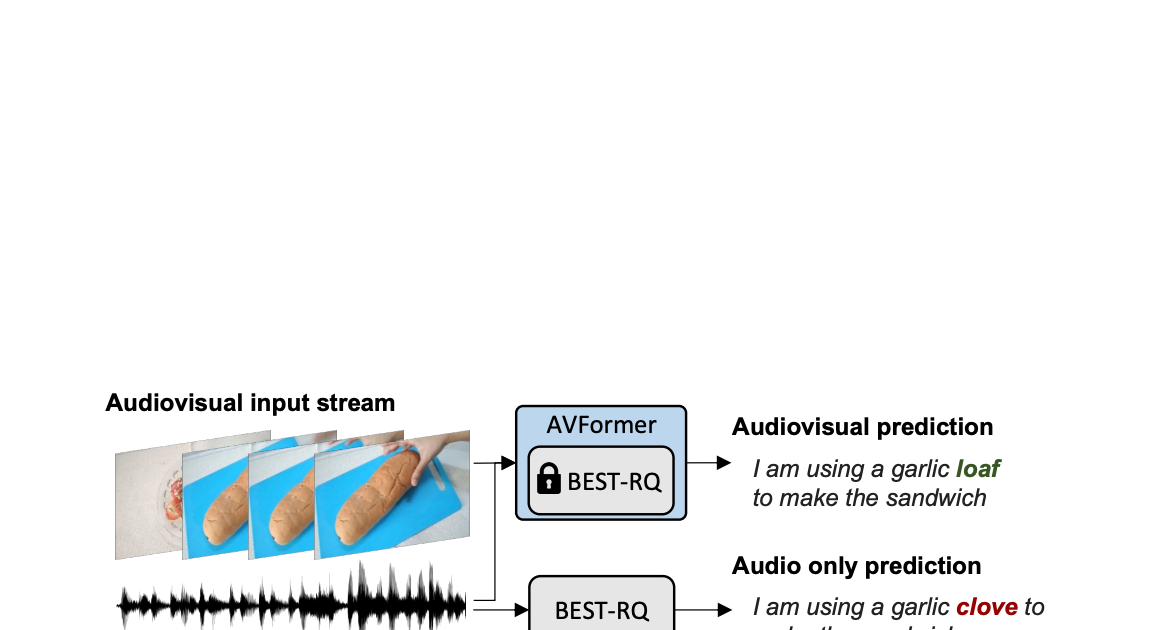
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、...

ビジュアルキャプション:大規模言語モデルを使用して、動的なビジュアルを備えたビデオ会議を補完する
Google Augmented Realityのリサーチサイエンティスト、Ruofei DuとシニアスタッフリサーチサイエンティストのAlex Olwalが投稿しました。 ライブキャプショ...

多言語での音声合成の評価には、SQuIdを使用する
Googleの研究科学者Thibault Sellamです。 以前、私たちは1000言語イニシアチブとUniversal Speech Modelを紹介しました。これらのプロジェクトは、世界中の...

Imagen EditorとEditBench:テキストによる画像補完の進展と評価
グーグルリサーチの研究エンジニアであるスー・ワンとセズリー・モンゴメリーによる投稿 過去数年間、テキストから画像を生成する研究は、画期的な進展(特に...

- You may be interested
- 初心者向けの生成AIの優しい紹介
- 自動車産業の未来は、話す車かもしれません
- 「Amazon SageMaker Canvas UIとAutoML AP...
- トップAIアドベンチャー:OpenAIレジデンシー
- 類似検索、パート6:LSHフォレストによる...
- 「INDIAaiとMetaが連携:AIイノベーション...
- 「ガードレールでLLMを保護する」
- 「ロボットがより良い判断をするにはどう...
- CleanLabを使用してデータセットのラベル...
- VoAGI ニュース、9月27日:ChatGPT プロジ...
- 「マルチスレッディングの探求:Pythonに...
- データサイエンスプロジェクトでのハード...
- 「データ資産のポートフォリオを構築およ...
- 新しい方法:AIによって地図がより没入感...
- 「ジャスティン・マクギル、Content at Sc...