Learn more about Search Results Tesla - Page 6

- You may be interested
- 「ChatGPTのコードインタプリターがついに...
- ChatGPTのコードインタプリター:知ってお...
- PythonからJuliaへ:基本的なデータ操作とEDA
- 「生成AIの余波におけるオープンソースAI...
- 「メールの生産性を革新する:SaneBoxのAI...
- 「未知を制する:GPT-4とフリップされたイ...
- 音声合成、音声認識、そしてSpeechT5を使...
- 「大学は、量子の未来のためにエンジニア...
- 非アーベル任意子の世界で初めてのブレー...
- バードの未来展望:よりグローバルで、よ...
- GoogleとJohns Hopkins Universityの研究...
- ウィンブルドンがAIによる実況を導入
- 「生成AIはその環境への足跡に値するのか?」
- 「Objaverse-XLと出会ってください:1000...
- 「ShutterstockがエシカルAIと顧客保護の...
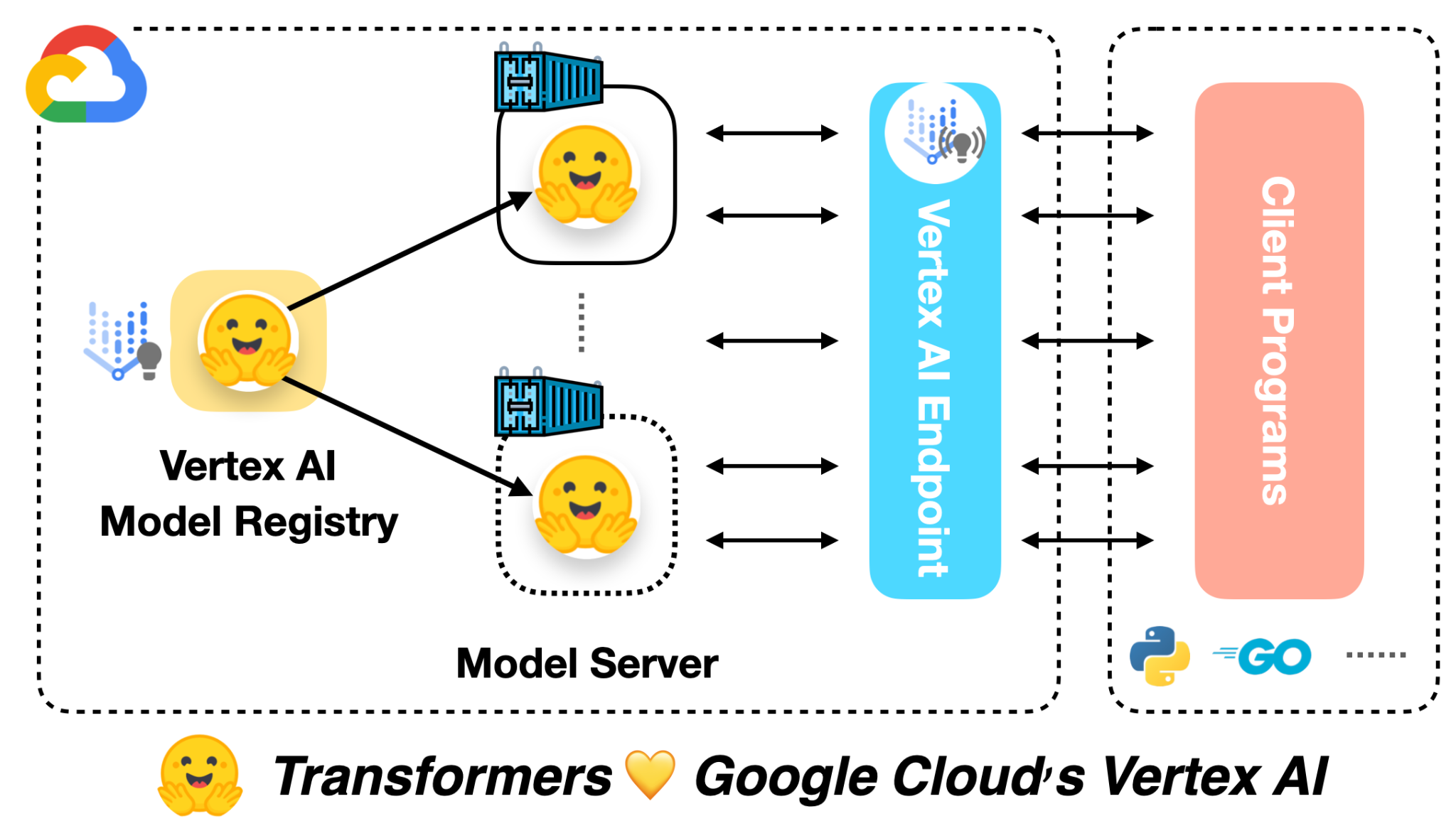
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

ゼロから大規模言語モデルを構築するための初心者ガイド
はじめに TwitterやLinkedInなどで、私は毎日多くの大規模言語モデル(LLMs)に関する投稿に出会います。これらの興味深いモデルに対してなぜこれほど多くの研究と開発が行われているのか、私は疑問に思ったこともあります。ChatGPTからBARD、Falconなど、無数のモデルの名前が飛び交い、その真の性質を解明したくなるのです。これらのモデルはどのように作成されるのでしょうか?大規模言語モデルを構築するにはどうすればよいのでしょうか?これらのモデルは、あなたが投げかけるほとんどの質問に答える能力を持つのはなぜでしょうか?これらの燃えるような疑問は私の心に長く残り、好奇心をかき立てています。この飽くなき好奇心は私の内に火をつけ、LLMsの領域に飛び込む原動力となっています。 私たちがLLMsの最先端について議論する刺激的な旅に参加しましょう。一緒に、彼らの開発の現状を解明し、彼らの非凡な能力を理解し、彼らが言語処理の世界を革新した方法に光を当てましょう。 学習目標 LLMsとその最新の状況について学ぶ。 利用可能なさまざまなLLMsとこれらのLLMsをゼロからトレーニングするアプローチを理解する。 LLMsのトレーニングと評価におけるベストプラクティスを探究する。 準備はいいですか?では、LLMsのマスタリングへの旅を始めましょう。 大規模言語モデルの簡潔な歴史 大規模言語モデルの歴史は1960年代にさかのぼります。1967年にMITの教授が、自然言語を理解するための最初のNLPプログラムであるElizaを作成しました。Elizaはパターンマッチングと置換技術を使用して人間と対話し理解することができます。その後、1970年にはMITチームによって、人間と対話し理解するための別のNLPプログラムであるSHRDLUが作成されました。 1988年には、テキストデータに存在するシーケンス情報を捉えるためにRNNアーキテクチャが導入されました。2000年代には、RNNを使用したNLPの研究が広範に行われました。RNNを使用した言語モデルは当時最先端のアーキテクチャでした。しかし、RNNは短い文にはうまく機能しましたが、長い文ではうまく機能しませんでした。そのため、2013年にはLSTMが導入されました。この時期には、LSTMベースのアプリケーションで大きな進歩がありました。同時に、アテンションメカニズムの研究も始まりました。 LSTMには2つの主要な懸念がありました。LSTMは長い文の問題をある程度解決しましたが、実際には非常に長い文とはうまく機能しませんでした。LSTMモデルのトレーニングは並列化することができませんでした。そのため、これらのモデルのトレーニングには長い時間がかかりました。 2017年には、NLPの研究において Attention Is All You Need という論文を通じてブレークスルーがありました。この論文はNLPの全体的な景色を変革しました。研究者たちはトランスフォーマーという新しいアーキテクチャを導入し、LSTMに関連する課題を克服しました。トランスフォーマーは、非常に多数のパラメータを含む最初のLLMであり、LLMsの最先端モデルとなりました。今日でも、LLMの開発はトランスフォーマーに影響を受けています。 次の5年間、トランスフォーマーよりも優れたLLMの構築に焦点を当てた重要な研究が行われました。LLMsのサイズは時間とともに指数関数的に増加しました。実験は、LLMsのサイズとデータセットの増加がLLMsの知識の向上につながることを証明しました。そのため、BERT、GPTなどのLLMsや、GPT-2、GPT-3、GPT 3.5、XLNetなどのバリアントが導入され、パラメータとトレーニングデータセットのサイズが増加しました。 2022年には、NLPにおいて別のブレークスルーがありました。 ChatGPT は、あなたが望むことを何でも答えることができる対話最適化されたLLMです。数か月後、GoogleはChatGPTの競合製品としてBARDを紹介しました。…

DeepMind RoboCat:自己学習ロボットAIモデル
世界的に有名なAI研究所であるDeepMindは、ロボットアームの様々なモデルを使用して幅広い複雑なタスクを実行できるAIモデルRoboCatを発表しました。以前のモデルとは異なり、RoboCatは複数のタスクを解決し、異なる現実世界のロボットにシームレスに適応する能力があります。この素晴らしい成果の詳細について掘り下げ、RoboCatがロボティクスの分野を革新する方法を探ってみましょう。 また読む:Amazonの秘密の家庭用AIロボットは何でもできます 多機能なRoboCat:ロボティックインテリジェンスの飛躍 DeepMindの画期的なAIモデルRoboCatは、ロボティクスの多様性に前例のないレベルを示しています。DeepMindの研究者であるAlex Leeによると、RoboCatは複数の現実的なロボットの具現化にわたって多様なタスクに取り組むことができる単一の大型モデルです。つまり、モデルは新しいタスクや異なるロボット構成に迅速に適応することができます。これはロボティクスの分野において重要なマイルストーンとなります。 また読む:スパイダーマンになるAIロボットアーム「自在アーム」 GATOからインスピレーションを得て:テキストからロボティックスへ RoboCatは、DeepMindが開発した別のAIモデルであるGATOからインスピレーションを得ています。GATOはテキスト、画像、イベントを分析して応答する驚異的な能力を持っています。DeepMindの研究者は、この概念を活用して、シミュレーション環境と現実のロボティクス環境から収集した画像とアクションデータからなる大規模データセットでRoboCatをトレーニングしました。 強力なRoboCatをトレーニングする RoboCatをトレーニングするため、DeepMindのチームは、人間が制御するロボットアームによって実行されるさまざまなタスクの100〜1,000のデモンストレーションを収集しました。これらのデモンストレーションは、特定のタスクに対してモデルを微調整し、専門の「スピンオフ」モデルを作成するための基盤となりました。各スピンオフモデルは、各タスクについて平均10,000回の練習を行いました。 また読む:世界初のAIパワードアーム:知っておくべきすべて 限界を突破する:RoboCatのポテンシャルを解き放つ RoboCatの最終バージョンは、合計253のタスクでトレーニングされ、これらのタスクの141のバリエーションでベンチマークが行われ、シミュレーションされた場合と現実世界のシナリオの両方を含んでいます。DeepMindは、モデルが数時間の人間が制御するデモンストレーションを1,000回観察した後、異なるロボットアームを操作する方法を成功裏に学んだと報告しています。しかし、成功率は異なり、タスクによって13%から99%まで幅広く、デモンストレーションの数が決定的な要因となります。 また読む:AlphabetがFlowstateを解き放つ:誰でも使えるロボットアプリ開発プラットフォーム 新しいフロンティアを開拓する:ロボティクスを再定義する 成功率が異なるにもかかわらず、DeepMindは、RoboCatが新しいタスクを解決するためのバリアを下げる可能性があると考えています。Alex Leeは、新しいタスクのデモンストレーションの数が限られていても、RoboCatを微調整し、パフォーマンスをさらに向上させることができると説明しています。究極の目標は、RoboCatに新しいタスクを教えるために必要なデモンストレーションの数を10以下に減らすことで、ロボティクスの分野を革新することです。 また読む:Sanctuary AIのPhoenix RobotとTeslaの最新発売、Optimusに会ってください! 私たちの意見 DeepMindのRoboCatは、ロボティクスの分野における重大な突破口を表しています。1つのAIモデルが、複数のタスクや異なるロボットの具現化にわたって適応し、優れた性能を発揮することができることを示しています。大規模なデータセットでのトレーニングと微調整のパワーを活用することで、RoboCatは将来の進歩の基盤を築きました。ロボットに新しいタスクを教えるプロセスを効率化する可能性があるRoboCatは、革新の新時代をもたらすかもしれません。RoboCatが最小限の人間の介入でシームレスに適応し、学習する未来を切り拓くには、エキサイティングな時代が待っています。

コールセンターにおけるAIソフトウェアが顧客サービスを革命化します
人工知能(AI)技術の急速な進歩により、チャットボットの導入を特に受けた顧客サービスとサポートに変革的なシフトがもたらされました。通信、保険、銀行、公共事業、政府機関など、さまざまな業界が、今後数年間でAIによるソリューションの導入を進める予定です。この次世代の自動化されたサポートシステムの提唱者たちは、比類のない利益を想像していますが、その他の人々は潜在的な落とし穴について懸念を表明しています。この記事では、コールセンターにおけるAIの影響について掘り下げます。それは、優れた顧客体験を提供するか、既存の課題を悪化させるかを検討します。 また読む:ChatGPTは、医師よりも質の高い医療アドバイスを提供する AIによるコールセンターの台頭 人工知能は、近年著しい進歩を遂げ、専門家たちは、顧客サービス業務での広範な採用を予想しています。従来のチャットボットに頼るのではなく、新しい世代のAI駆動システムは、驚異的な能力を示します。彼らは、個々の顧客のニーズに合わせたカスタマイズされた応答を提供するために、継続的に学習し、適応し、膨大な情報を活用することができます。 また読む:Sanctuary AIのPhoenixロボットとTeslaの最新ローンチ、Optimus!に会いましょう! 自動化サポートの二重性 高度なAIに基づく顧客サービスの見通しは有望ですが、その実装と潜在的な欠点については、正当な懸念があります。十分な準備なしに採用に急いだ場合、顧客の体験が失望する可能性があります。自動ループは、人道的支援にアクセスできず、困り果てた顧客が自分自身を取り囲んでいるという現実的な懸念があります。また、意図しない冒涜的または不正確なAIの応答も検討する必要があります。 また読む:ChatGPTがラジオホストに対して偽の告発を生成するため、OpenAIが名誉毀損訴訟に直面しています コールセンターの労働者への影響 コールセンターにおけるAIの導入は、今後10年間で何百万ものコールセンター労働者の大量失業を引き起こすことが予想されています。短期間では、状況は同じくらい厳しいようです。労働者は、クエリの処理に関する提案を提供し、パフォーマンスについて報告する機械による常時監視の見通しに直面しています。この増加した監視は、彼らの仕事の既に厳しい性質を強化し、より高いストレスレベルを引き起こす可能性があります。 また読む:人工知能の急速な上昇は、仕事の喪失を意味します:テックセクターで何千人もの人々が影響を受けています コスト削減と生産性向上のバランス 潜在的な欠点にもかかわらず、ビジネスにとって生成的AIの魅力は否定できません。最近のマッキンゼーの報告によると、顧客サービス機能の改善だけでも、世界中で4,040億ドルの驚異的な利益が得られる可能性があります。これらの潜在的な節約と生産性の向上は、組織がAI駆動のソリューションをさらに探求することを推進するでしょう。したがって、彼らはコスト効率と顧客満足度のバランスを慎重に維持する必要があります。 また読む:生成的AIは年間4.4兆ドルの貢献ができる:マッキンゼー 消費者のAIへの信頼 OpenAIのChatGPT、GoogleのBard、そしてMicrosoftのAI駆動のBing検索エンジンなどのAIチャットボットの出現は、一般大衆を魅了し、その応用についての多くの議論を引き起こしました。しかし、消費者の感情は分かれています。最近の調査によると、74%の回答者が、AIに基づく顧客サービスはライブ代表者とのやり取りよりも悪い体験を提供すると考えています。同様に、63%の人々が人間のエージェントをAIよりも信頼し、わずか6%がチャットボットに傾いています。さらに、カナダ人の大多数(63%)は、パンデミック中にチャットボットを雇用した企業が、ポストパンデミック時にライブ代表者に戻ることを期待しており、そうしない企業には否定的な影響があります。 私たちの意見 人工知能をコールセンターの運用に統合することは、機会と課題の両方を示します。潜在的な利益は、改善された顧客体験や巨大なコスト削減を含みますが、サービスの質やコールセンターの従業員への影響については正当な懸念があります。人間のタッチとAI駆動のサポートの適切なバランスを打つことは、AI時代において顧客サービスを最適化しようとする組織にとって重要です。コールセンターの景色がこの変革的なシフトを経験するにつれ、効率的で共感的な顧客体験の提供を優先し、AI駆動のテクノロジーの利点を受け入れることが不可欠です。
Rによるディープラーニング
このチュートリアルでは、Rで深層学習タスクを実行する方法を学びます
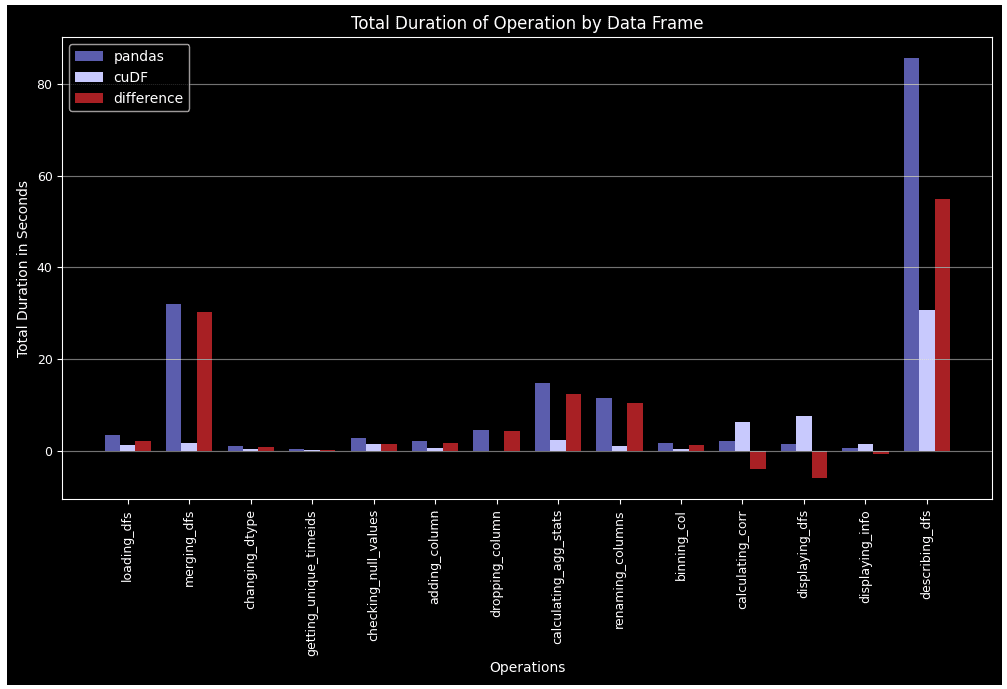
GPUを活用した特徴量エンジニアリングにおいてRAPIDS cuDFを使用する
Google Colabと統合し、データフレームの作成と特徴量エンジニアリングにおいて、cuDFにPandasを置き換えることでパフォーマンスを向上させる

2023年の最高の6つの人工知能(AI)ETF
ETFはAIに投資する便利で多様化された方法を提供します2023年最高の6つの人工知能(AI)ETFを探ってみましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.