Learn more about Search Results 7 参考文献: - Page 4

- You may be interested
- 「NVIDIA OmniverseでDLSS 3.5およびレイ...
- ヴェクタラは、AI言語モデルの「幻覚」を...
- 「GlotLIDをご紹介します:1665言語に対応...
- 私のDeepMindインターンからメンターへの...
- マイクロソフトの研究者が、言語AIを活用...
- 「Pythonにおけるフィボナッチ数列 | コー...
- 「グラフ機械学習 @ ICML 2023」
- 生産性向上のための10の最高のAIツール(...
- 「AIがITサービス管理を変革する方法」
- 「NVIDIA、ワシントンのAIの安全性確保の...
- 毎日時間を節約する14のGoogle Driveアドオン
- 大規模言語モデルの評価:包括的かつ客観...
- 「ChatGPTにおける自然言語入力のパワーを...
- FHEを用いた暗号化された大規模言語モデル...
- Allen Institute for AI の研究者が、自然...

「Azure OpenAIを使用した企業文書とのチャット」
大規模言語モデル(LLM)のようなChatGPTは、インターネット上の大量のテキストから訓練される際に、数十億のパラメータ内に膨大な知識のリポジトリを保持していますしかし、それらの…

クラスの不均衡:SMOTEからSMOTE-NCおよびSMOTE-Nへ
前の話では、私たちはどのように単純なランダムオーバーサンプリングとランダムオーバーサンプリングの例(ROSE)アルゴリズムが動作するかを説明しましたさらに重要なことに、クラスの不均衡問題を定義し、導出しました...
「クラスの不均衡:ランダムオーバーサンプリングからROSEへ」
最近、Juliaでクラスの不均衡を解決するためのパッケージ、Imbalance.jlを作成しています論文の読解や実装の調査に多くの努力を払いながら、作成に取り組んできました...

「GPTの内部- I:テキスト生成の理解」
「さまざまなドメインの同僚と定期的に関わりながら、データサイエンスの背景をほとんど持たない人々に機械学習の概念を伝えるという課題に取り組んでいますここでは、私は試みています...」
「生データから洗練されたデータへ:データの前処理の旅 — パート3:重複データ」
データ内の重複した値の存在は、多くのプログラマーによってしばしば無視されますしかし、データ内の重複したレコードに対処することは非常に重要です例えば、置き換えるとどうなるかなど、重複したレコードの扱いは重要です
データリテラシーの力
データは、現代のビジネス成功において重要な要素ですしかし、多くの企業は、その全ての潜在能力を引き出すことに苦労していますこれには複数の理由がありますが、詳しく掘り下げてみましょう…

「プロセスマイニングとデジタルトランスフォーメーションによる産業4.0における業務の効率化の実現」
「業界に関係なく、デジタル技術は組織の間でますます人気を集めており、業績向上、収益成長、持続可能性の実現に向けて活用されています」
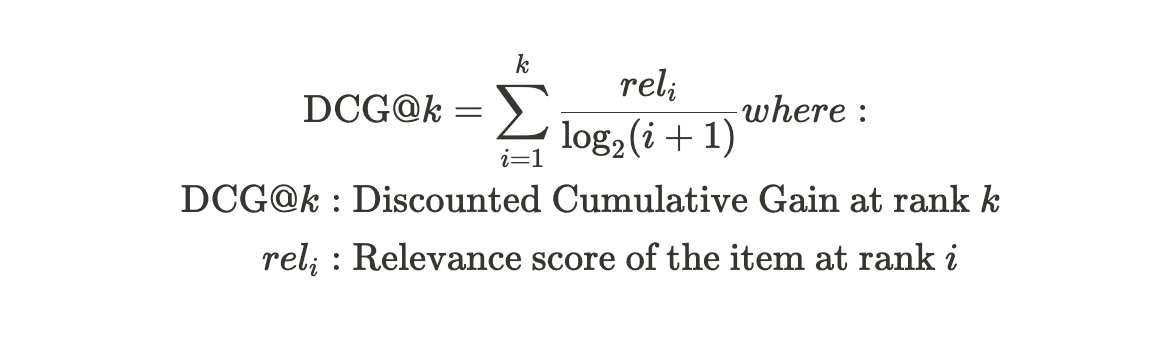
レコメンドシステムの評価指標 — 概要
最近、レコメンデーションシステムのプロジェクトを実験している最中、様々な評価指標を使用することがありましたそのため、役立つと感じた評価指標のリストと他のいくつかの事柄をまとめました

「SDXL 1.0の登場」
機械学習の急速に進化する世界では、新しいモデルやテクノロジーがほぼ毎日私たちのフィードに押し寄せるため、最新情報を把握し、情報を元にした選択をすることは困難な課題となります今日は、私たちは...
直感的にR2と調整済みR2のメトリックを探索する
R2は、回帰型の機械学習タスクの評価メトリックとして広く使用されていますそれは、目的の特徴量(従属特徴量)の分散のどれくらいが機械によって説明されるかを見つけ出します...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.