Learn more about Search Results 384 - Page 4

- You may be interested
- AIがフィンテックを向上させる方法:追跡...
- 「Great Expectationsを始めよう Pythonに...
- DeepMindのAIマスターゲーマー:2時間で26...
- 「マルチプレーナーUNet:すべての3Dセグ...
- 『スタートアップでのフルスタックデータ...
- 「ミストラル・トリスメギストス7Bにお会...
- 「GPUのマスタリング:PythonでのGPUアク...
- アジアにおける生成型AIの機会
- AIのアナロジカルな推論能力:人間の知能...
- 「大規模な言語モデルを使用した顧客調査...
- カルテックとETHチューリッヒの研究者が画...
- 初期段階の企業や初めての創業者が経済的...
- Habana LabsとHugging Faceが提携し、Tran...
- 『AIの未来、心の索引化、より良いAIの構築』
- 「成功したプロンプトの構造の探索」

「Amazon SageMaker Feature Store Feature Processorを使用して、MLの洞察を解き放つ」
Amazon SageMaker Feature Storeは、機械学習(ML)のための特徴量エンジニアリングを自動化するためのエンドツーエンドのソリューションを提供します多くのMLユースケースでは、ログファイル、センサーの読み取り、トランザクションレコードなどの生データを、モデルトレーニングに最適化された意味のある特徴に変換する必要があります特徴量の品質は、高精度なMLモデルを確保するために重要です[...]
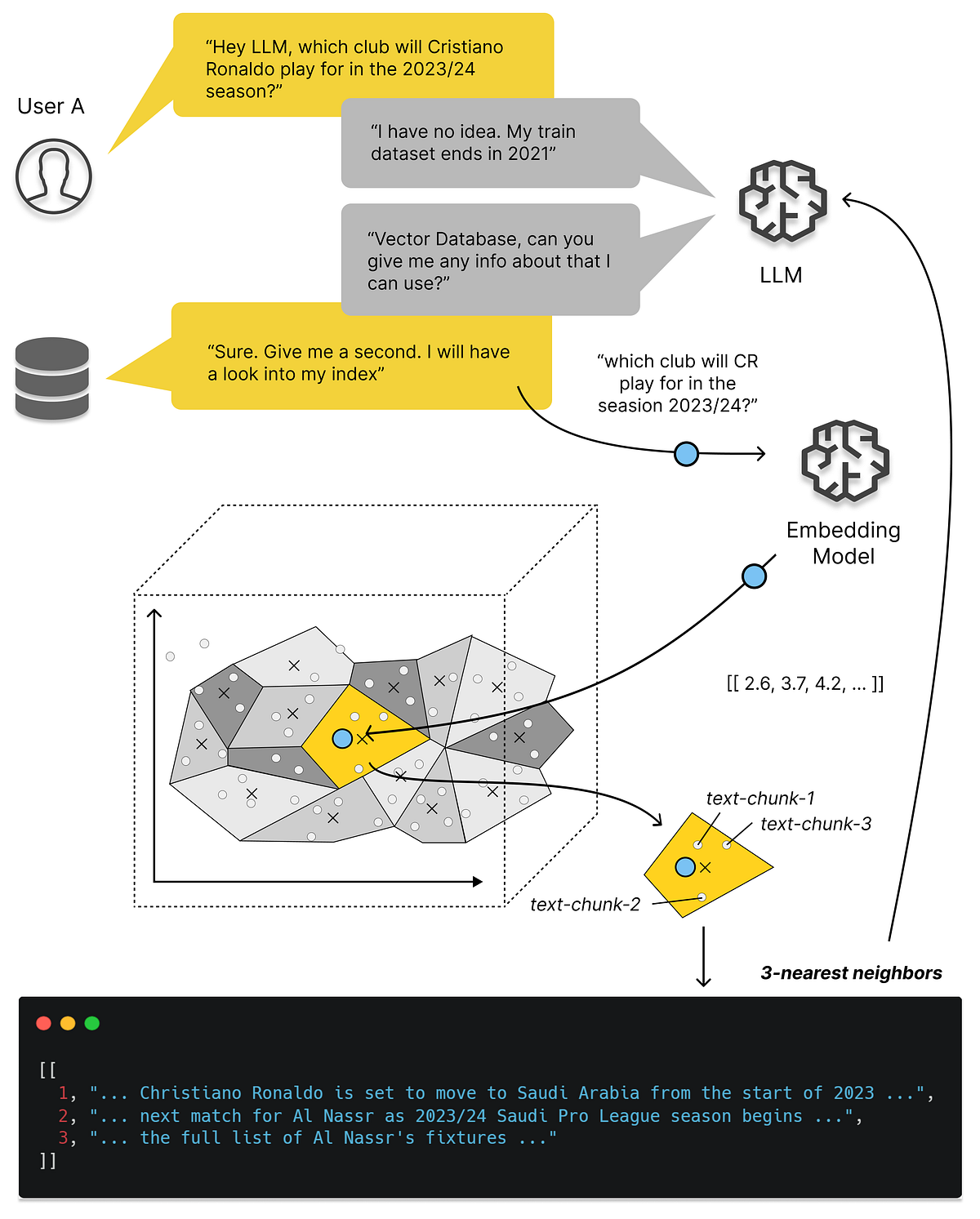
ベクトルデータベースについて知っておくべきすべてと、それらを使用してLLMアプリを拡張する方法
「ベクトルデータベースの特別な点は何ですか? 文の意味を数値表現にどのようにマッピングしますか? それが私たちのLLMアプリにどのように役立ちますか? なぜ私たちは単にLLMに持っているすべてのデータを与えることができないのですか…」

「ルービックとマルコフ」
ルービックキューブは、巨大な状態空間とただ1つの解を持つ計画問題のプロトタイプですそれはまさに干し草の中の針の定義そのものですガイダンスがない場合(たとえ回すことができるとしても...

「アメリカがGoogleの検索支配に挑戦する」
Googleの検索支配は、2019年に始まったビッグテックへの取り締まり以来、最大の米国反トラスト訴訟で審理されています

PyTorch FSDPを使用してLlama 2 70Bのファインチューニング
はじめに このブログ記事では、PyTorch FSDPと関連するベストプラクティスを使用して、Llama 2 70Bを微調整する方法について説明します。Hugging Face Transformers、Accelerate、およびTRLを活用します。また、AccelerateをSLURMと一緒に使用する方法も学びます。 Fully Sharded Data Parallelism(FSDP)は、オプティマイザの状態、勾配、およびパラメータをデバイス間でシャードするパラダイムです。フォワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、計算が行われた後に他のデバイスからのシャードを破棄します。フォワードパスの後、ロスが計算され、バックワードパスが行われます。バックワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、ローカルな勾配を取得するための計算が行われます。これらのローカルな勾配は平均化され、リダクション-スキャッタ操作を介してデバイス間でシャードされるため、各デバイスは自身のシャードのパラメータを更新することができます。PyTorch FSDPの詳細については、次のブログ記事を参照してください:PyTorch Fully Sharded Data Parallelを使用した大規模モデルトレーニングの加速。 (出典: リンク) 使用されたハードウェア ノード数:2。最小要件は1です。ノードあたりのGPU数:8。GPUタイプ:A100。GPUメモリ:80GB。ノード内接続:NVLink。ノードあたりのRAM:1TB。ノードあたりのCPUコア数:96。ノード間接続:Elastic Fabric Adapter。 LLaMa 70Bの微調整における課題…

「Pythonにおける記述統計と推測統計の適用」
データサイエンスの道を進むにつれて、知っておくべき基本的な統計情報を以下に示します

「NVIDIAのグレース・ホッパー・スーパーチップがMLPerfの推論ベンチマークを席巻する」
MLPerf業界ベンチマークに初登場したNVIDIA GH200 Grace Hopperスーパーチップは、すべてのデータセンターインファレンステストを実行し、NVIDIA H100 Tensor Core GPUのリーディングパフォーマンスを拡張しました。 全体的な結果は、NVIDIA AIプラットフォームの卓越したパフォーマンスと多機能性を示しており、クラウドからネットワークのエッジまでの幅広い領域で活躍しています。 別途、NVIDIAは性能、エネルギー効率、総所有コストの向上をユーザーにもたらすインファレンスソフトウェアを発表しました。 GH200スーパーチップがMLPerfで輝く GH200は、Hopper GPUとGrace CPUを1つのスーパーチップに結合しています。この組み合わせにより、より多くのメモリ、帯域幅、およびCPUとGPUの間で自動的に電力を切り替えてパフォーマンスを最適化する能力が提供されます。 また、8つのH100 GPUを搭載したNVIDIA HGX H100システムは、今回のMLPerfインファレンステストのすべての項目で最も高いスループットを実現しました。 Grace HopperスーパーチップとH100 GPUは、コンピュータビジョン、音声認識、医療画像などのMLPerfのデータセンターテスト全般でリードし、推薦システムや生成AIにおける大規模言語モデル(LLM)など、より要求の厳しいユースケースでも優れたパフォーマンスを発揮しました。 全体的に、これらの結果は、2018年のMLPerfベンチマークの開始以来、NVIDIAがAIトレーニングとインファレンスのパフォーマンスリーダーシップを証明し続ける記録を続けています。 最新のMLPerfラウンドでは、推薦システムのテストが更新され、AIモデルのサイズの大まかな指標である6兆パラメータを持つGPT-Jの最初のインファレンスベンチマークが実施されました。…
Fast.AIディープラーニングコースからの7つの教訓
「最近、Fast.AIのPractical Deep Learning Courseを修了しましたこれまでに多くの機械学習コースを受講してきましたので、比較することができますこのコースは間違いなく最も実践的でインスピレーションを受けるものの一つですですので…」

「T2Iアダプタを使用した効率的で制御可能なSDXL生成」
T2I-Adapterは、オリジナルの大規模なテキストから画像へのモデルを凍結しながら、事前学習されたテキストから画像へのモデルに追加のガイダンスを提供する効率的なプラグアンドプレイモデルです。T2I-Adapterは、T2Iモデル内部の知識を外部の制御信号と整合させます。さまざまな条件に応じてさまざまなアダプタをトレーニングし、豊富な制御と編集効果を実現することができます。 ControlNetは同様の機能を持ち、広く使用されている現代の作業です。しかし、実行するには計算コストが高い場合があります。これは、逆拡散プロセスの各ノイズ除去ステップで、ControlNetとUNetの両方を実行する必要があるためです。さらに、ControlNetは制御モデルとしてUNetエンコーダのコピーを重要視しており、パラメータ数が大きくなるため、生成はControlNetのサイズによって制約されます(サイズが大きければそれだけプロセスが遅くなります)。 T2I-Adapterは、この点でControlNetに比べて競争力のある利点を提供します。T2I-Adapterはサイズが小さく、ControlNetとは異なり、T2I-Adapterはノイズ除去プロセス全体の間ずっと一度だけ実行されます。 過去数週間、DiffusersチームとT2I-Adapterの著者は、diffusersでStable Diffusion XL(SDXL)のT2I-Adapterのサポートを提供するために協力してきました。このブログ記事では、SDXLにおけるT2I-Adapterのトレーニング結果、魅力的な結果、そしてもちろん、さまざまな条件(スケッチ、キャニー、ラインアート、深度、およびオープンポーズ)でのT2I-Adapterのチェックポイントを共有します。 以前のバージョンのT2I-Adapter(SD-1.4/1.5)と比較して、T2I-Adapter-SDXLはまだオリジナルのレシピを使用しており、79Mのアダプタで2.6BのSDXLを駆動しています!T2I-Adapter-SDXLは、強力な制御機能を維持しながら、SDXLの高品質な生成を受け継いでいます。 diffusersを使用してT2I-Adapter-SDXLをトレーニングする 私たちは、diffusersが提供する公式のサンプルを元に、トレーニングスクリプトを作成しました。 このブログ記事で言及するT2I-Adapterモデルのほとんどは、LAION-Aesthetics V2からの3Mの高解像度の画像テキストペアで、以下の設定でトレーニングされました: トレーニングステップ:20000-35000 バッチサイズ:データ並列、単一GPUバッチサイズ16、合計バッチサイズ128。 学習率:定数学習率1e-5。 混合精度:fp16 コミュニティには、スピード、メモリ、品質の間で競争力のあるトレードオフを打つために、私たちのスクリプトを使用してカスタムでパワフルなT2I-Adapterをトレーニングすることをお勧めします。 diffusersでT2I-Adapter-SDXLを使用する ここでは、ラインアートの状態を例にとって、T2I-Adapter-SDXLの使用方法を示します。まず、必要な依存関係をインストールします: pip install -U git+https://github.com/huggingface/diffusers.git pip install…

「NVIDIAのCEOがインドの首相ナレンドラ・モディと会談」
インドの首相ナレンドラ・モディは、グローバルテクノロジースーパーパワーであるNVIDIAとの関係の深化を強調し、月曜日の夜にNVIDIAの創設者兼CEOであるジェンソン・ファンと会談しました。 ニューデリーの公式な首相の居住地である7ロク・カリャン・マルグでの会談は、モディが今週後半には米国のジョー・バイデン大統領を含むG20の首脳会議を主催する準備をしているという状況で行われました。 モディはソーシャルメディアで「NVIDIAのCEOであるジェンソン・ファン氏との素晴らしい会議をしました。インドが人工知能の世界で持つ豊かな可能性について詳しく話し合いました」と述べました。 このイベントは、モディとファンの2回目の会合であり、NVIDIAがインドの急成長するテクノロジー産業に果たす役割を強調しています。 モディとの会議は、インドが月の南極点に成功して着陸した直後に行われました。これにより、世界最大の民主主義国家の拡大する技術能力が示されました。 モディとの会議の後、ファンはインド科学研究所やインド工科大学の各キャンパスなど、科学技術の世界的な大学から数十人の研究者と非公式のディナーを開催しました。 参加者は、大規模な言語モデル、天体物理学、医学、量子コンピューティング、自然言語処理など、多岐にわたる分野のトップマインドの素晴らしい集まりを代表していました。 その夜の議論は、言語の壁を解消し、農業の収量を改善し、医療サービスのギャップを埋め、デジタル経済を変革するための技術の活用から、現代の科学の大きな課題に取り組むことまで、さまざまなトピックにわたりました。 NVIDIAはインドとの深い関係を持っています。同社は約20年前にバンガロールで事業を開始しました。現在、グルガオン、ハイデラバード、プネ、ベンガルールの4つのエンジニアリング開発センターをインドに持ち、インドには3,800人以上のNVIDIANがいます。 さらに、NVIDIAの開発者プログラムにはインドを拠点とする32万人以上の開発者がいます。NVIDIAのCUDA並列プログラミングプラットフォームは、インドでは月に約40,000回ダウンロードされ、国内には60,000人以上の経験豊富なCUDA開発者がいると推定されています。 この成長は、インド政府が国の情報技術インフラを拡大し続けているという背景があります。 たとえば、計算グリッドが国内の20の都市を繋げ、研究者や科学者がより効率的にデータと計算リソースを共有し協力するのに役立つ予定です。 その取り組みは、今後のインドの野心的な開発目標を支援することを約束しています。 モディは、インドが2030年までに世界第3位の経済大国になることを目指しています。現在は第5位です。 そして、モディは2047年、インドの独立100周年に、南アジアの国が先進国の仲間入りを果たすことを目指しています。 モディとの会議後のレセプションでの写真(左から)インド政府の主席科学顧問であるアジャイ・クマール・スード、IIScバンガロールの計算データ科学部門のチェアであるサシクマール・ガネーシャン、ファン、NVIDIA南アジア地域のマネージングディレクターであるヴィシャル・ドゥパル。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.