「多言語音声技術の障壁の克服:トップ5の課題と革新的な解決策」
Overcoming Barriers in Multilingual Speech Technology Top 5 Challenges and Innovative Solutions
イントロダクション
スペイン語で何かを尋ねた後、お好みの言語であるスペイン語でリクエストをしたにもかかわらず、音声アシスタントがスペイン語でのリクエストを理解せず、おそらく英語で再度リクエストをする必要があったことはありませんか?また、お気に入りのアーティストA.R.ラフマンの名前を正しく発音して音声アシスタントに彼らの楽曲を再生するように頼むと、音声アシスタントが理解しないことを知っているので、敢えて彼らの名前を「A.R.ラーメン」と発音する必要がありますか?さらに、お気に入りのミュージカル「レ・ミゼラブル」の名前を音声アシスタントが「レ・ミザラブルズ」と発音し、お気に入りのミュージカルの名前を切り刻まれたときに不快な思いをしたことはありませんか?
音声アシスタントは約10年前に主流になりましたが、マルチリンガルなコンテキストでのユーザーのリクエストの理解においては依然として単純なままです。マルチリンガルな世帯が増え、既存および潜在のユーザーベースがますますグローバルかつ多様化する現代において、音声アシスタントは言語、方言、アクセント、トーン、モジュレーション、その他の音声特性に関係なく、ユーザーのリクエストをスムーズに理解する能力を持つことが重要です。しかし、音声アシスタントは、人間同士が行うような滑らかな会話ができるようになるという点で、依然として大きく遅れています。本記事では、音声アシスタントがマルチリンガルに運用する際の最大の課題と、これらの課題を緩和するためのいくつかの戦略について探っていきます。この記事では、イラストの目的で架空の音声アシスタント「Nova」を使用します。
- 「Nvidiaが革命的なAIチップを発表し、生成型AIアプリケーションを急速に強化する」
- 「組み込まれた責任あるAIプラクティスを持つ大規模言語モデル(LLM)におけるプロンプトエンジニアリングの進化トレンド」
- 大規模言語モデルとは何ですか?
音声アシスタントの動作原理
マルチリンガルな音声アシスタントのユーザーエクスペリエンスに関して課題と可能性に入る前に、音声アシスタントの動作概要を把握しましょう。架空の音声アシスタントであるNovaを使用して、音楽トラックのリクエストのエンドツーエンドのフローを見てみましょう(参照)。
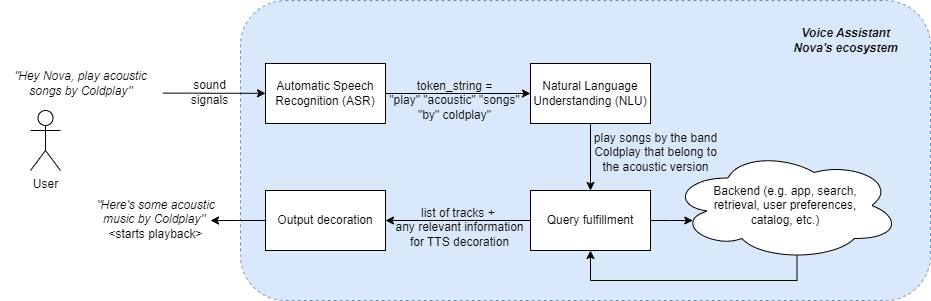
図1を見るとわかるように、ユーザーがNovaに対して人気バンドColdplayのアコースティックな音楽を再生するように頼むと、ユーザーの音声信号はまずテキストトークンの文字列に変換されます。これは人間と音声アシスタントのインタラクションの最初のステップであり、自動音声認識(ASR)または音声からテキスト(STT)と呼ばれます。トークンの文字列が利用可能になると、次に、音声アシスタントはユーザーの意図の意味論と構文の理解を試みる自然言語理解のステップに進みます。この場合、音声アシスタントのNLUは、ユーザーがColdplayのバンドの曲(つまり、Coldplayがバンドであると解釈)をアコースティックな性質で探していることを解釈します(つまり、このバンドのディスコグラフィの曲のメタデータを調べ、バージョン=アコースティックの曲のみを選択します)。このユーザーの意図理解は、ユーザーが探しているコンテンツを検索するために使用されます。最後に、ユーザーが探している実際のコンテンツと、この出力をユーザーに提示するために必要なその他の情報が次のステップに引き継がれます。このステップでは、レスポンスと利用可能なその他の情報が使用され、ユーザーのクエリに満足するようにエクスペリエンスが装飾されます。この場合、テキストから音声(TTS)の出力(「こちらはColdplayのアコースティックな音楽です」)の後、このユーザーのクエリに選択された実際の曲の再生が行われます。
マルチリンガル音声アシスタントの課題
マルチリンガル音声アシスタント(VA)とは、同じ人または複数の人によって話される複数の言語を理解し、応答することができる音声アシスタントのことを指します。また、同じ人が別の言語と混在した文で話す場合も含まれます(例:「Nova、arrêt!他の曲を再生してください」)。以下は、マルチモーダルな環境でのシームレスな運用が可能な音声アシスタントに関して、最も重要な課題です。
- 言語リソースの不十分な量と品質
クエリを適切に解析し理解するために、音声アシスタントはその言語での大量のトレーニングデータに基づいて訓練される必要があります。このデータには人間の音声データ、正解の注釈、膨大な量のテキストコーパス、TTSの発音の改善に関するリソース(発音辞書など)や言語モデルが含まれます。これらのリソースは英語、スペイン語、ドイツ語などの人気言語では簡単に利用できますが、スワヒリ語、パシュト語、チェコ語などの言語では利用できるリソースが制限されたり存在しなかったりします。これらの言語は十分な人々によって話されているにもかかわらず、これらの言語に対して構造化されたリソースは利用できません。複数の言語に対してこれらのリソースを作成することは、進歩に向けた障害となるため、費用がかかり、複雑で手作業が必要です。
- 言語の変化
言語には方言、アクセント、バリエーション、地域的な適応があります。これらの変化に対処することは、音声アシスタントにとって大きな挑戦です。これらの言語の微妙なニュアンスに適応しない限り、ユーザーの要求を正しく理解したり、同じ言語のトーンで応答したりして、自然で人間らしい体験を提供することは困難です。例えば、英国だけでも40以上の英語のアクセントがあります。もう一つの例として、メキシコで話されるスペイン語とスペインで話されるスペイン語は異なります。
- 言語の識別と適応
多言語を話すユーザーが他の人間との対話中に言語を切り替えることは一般的であり、彼らは音声アシスタントとの自然な対話も期待するかもしれません。例えば、「ヒングリッシュ」という言葉は、ヒンディー語と英語の両方の単語を使って話す人の言語を説明するためによく使われます。ユーザーが音声アシスタントとの対話で使用している言語を識別し、応答を適応することは、現在の主流の音声アシスタントには困難な課題です。
- 言語の翻訳
音声アシスタントを複数の言語に拡張する方法の一つは、ルクセンブルク語のようなあまり一般的でない言語を、より正確に処理できる言語(例えば英語)にASRの出力を翻訳することです。一般に使用される翻訳技術には、ニューラル機械翻訳(NMT)、統計的機械翻訳(SMT)、ルールベースの機械翻訳(RBMT)などの技術を使用する方法があります。ただし、これらのアルゴリズムは多様な言語セットに対してスケーリングしづらく、大量のトレーニングデータも必要とする場合があります。さらに、言語固有のニュアンスが失われることがよくあり、翻訳されたバージョンは不自然で不自然に感じる場合があります。翻訳の品質は、多言語の音声アシスタントをスケーリングする能力において持続的な課題となっています。翻訳ステップでのもう一つの課題は、導入される遅延による人間と音声アシスタントの対話の体験の低下です。
- 真の言語理解
言語には独自の文法構造があります。例えば、英語には単数と複数の概念がありますが、サンスクリットには3つの概念(単数、双数、複数)があります。他の言語にうまく翻訳されない異なるイディオムも存在するかもしれません。最後に、文化的なニュアンスや文化的な言及も、翻訳技術が高い意味理解の品質を持っていない限り、うまく翻訳されない場合があります。言語固有のNLUモデルの開発は費用がかかります。
多言語音声アシスタントの課題を克服する方法
上記で述べた課題は解決が難しい問題です。しかし、これらの課題を部分的に軽減する方法はいくつかあります。以下に、上記で述べた課題のいくつかを解決することができるいくつかの技術を紹介します。
- 深層学習を利用して言語を検出する
文の意味を解釈する最初のステップは、文が属する言語を知ることです。ここで深層学習が登場します。深層学習は人工ニューラルネットワークと大量のデータを使用して、人間らしい出力を生成する手法です。Transformerベースのアーキテクチャ(例えばBERT)は、低リソース言語の場合でも言語検出に成功しています。Transformerベースの言語検出モデルの代替としては、再帰ニューラルネットワーク(RNN)があります。これらのモデルの適用例としては、通常英語で話すユーザーがある日突然スペイン語で音声アシスタントに話しかける場合、音声アシスタントはスペイン語を正しく検出できることです。
- 文脈に基づいた機械翻訳を使用してリクエストを「理解」する
言語が検出されたら、次のステップはASRの出力であるトークンの文字列を取り、単に文字通りではなく意味的にも処理できる言語に翻訳することです。文脈に無頓着な翻訳APIを使用する代わりに、音声インターフェイスの文脈や特異性を常に把握できない場合や、高い遅延により応答に不都合が生じる場合があります。しかし、文脈に基づいた機械翻訳モデルを音声アシスタントに統合すると、翻訳の品質と正確性が向上し、セッションのドメインや文脈に特化しているため、より高い品質の翻訳が可能になります。例えば、音楽のジャンルやサブジャンル、楽器や音符の質問、特定のトラックの文化的な関連性などについて正しく理解し、応答するために、音声アシスタントが主にエンターテイメントに使用される場合、文脈に基づいた機械翻訳を活用することができます。
- 多言語の事前学習モデルを活用する
すべての言語には独自の構造や文法、文化的な参照、フレーズ、イディオム、表現、その他のニュアンスがありますので、さまざまな言語を処理するのは困難です。言語固有のモデルは高価ですが、事前学習された多言語モデルを使用することで、言語固有のニュアンスを捉えることができます。BERTやXLM-Rなどのモデルは、言語固有のニュアンスを捉えるための優れた事前学習モデルの例です。さらに、これらのモデルはドメインに適応させることで、精度をさらに向上させることができます。たとえば、音楽のドメインで訓練されたモデルは、単にクエリを理解するだけでなく、音声アシスタントを通じて豊かな応答を返すことができるかもしれません。もし音声アシスタントに対して、ある曲の歌詞の意味を尋ねた場合、音声アシスタントは単語の単純な解釈ではなく、より豊かな方法でその質問に答えることができるでしょう。
- コードスイッチングモデルを使用する
複数の異なる言語が混在する言語入力を処理できるようにするために、コードスイッチングモデルを実装することは有効です。たとえば、カナダの特定の地域向けに設計された音声アシスタントでは、ユーザーがしばしばフランス語と英語を混ぜて使用するため、コードスイッチングモデルを使用して、両言語の混在した文を理解し、音声アシスタントが処理できるようにすることができます。
- 低リソース言語に対して転移学習とゼロショット学習を活用する
転移学習とは、一つのタスクでモデルを訓練し、それを第二のタスクのモデルの出発点として使用する機械学習の技術です。第一のタスクからの学習を利用して、第二のタスクの性能を向上させることで、冷たいスタート問題をある程度克服することができます。ゼロショット学習とは、事前学習されたモデルを使用して、それが見たことのないデータを処理することです。転移学習とゼロショット学習の両方を活用することで、高リソース言語から低リソース言語への知識の転送が可能です。たとえば、音声アシスタントがすでに世界で最も一般的に話されているトップ10の言語に対して訓練されている場合、それを利用してスワヒリ語などの低リソース言語のクエリを理解することができるでしょう。
まとめ
要約すると、音声アシスタントでの多言語対応の構築と実装は困難ですが、これらの課題を解決する方法もあります。上記で指摘された課題に取り組むことで、音声アシスタントはユーザーの言語に関係なく、シームレスな体験を提供することができるでしょう。Amazon Musicのグローバルプロダクトチームを率いるAshlesha Kadamは、AlexaやAmazon Musicアプリ(Web、iOS、Android)での音楽体験を数百万人以上のお客様に提供しています。彼女はまた、テック業界の女性を支援する情熱的な提唱者でもあり、Grace Hopper Celebration(女性向け最大のテックカンファレンスで、115カ国で3万人以上の参加者がいます)のHuman Computer Interaction(HCI)トラックの共同議長を務めています。空いた時間には、Ashleshaはフィクションを読んだり、ビジネス・テックのポッドキャストを聴いたり(最新のお気に入りは「Acquired」です)、美しい太平洋北西部でハイキングを楽しんだり、夫や息子、5歳のゴールデン・レトリバーと過ごすことが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「生成AIの布地を調整する:FABRICは反復的なフィードバックで拡散モデルを個別化するAIアプローチです」
- スタビリティAIは、コーディングのための最初のLLMジェネレーティブAI製品であるStableCodeのリリースを発表します
- メタファーAPI:LLM向けに構築された革命的な検索エンジン
- 「GoogleがプロジェクトIDXを発表:AIパワードのブラウザベースのイノベーションでマルチプラットフォームアプリ開発を革新」
- ハリウッドにおけるディズニーの論争:AIが登場し、脚本家と俳優が退場!
- 「Google LLMは、ドキュメントを読むだけでツールをマスターできる」
- 「ドメイン特化LLMの潜在能力の解放」