エッジAIアプリケーションでのパフォーマンスを最大化する
美容とファッションのエキスパートによる、エッジAIアプリケーションでのパフォーマンス最大化のためのヒント
AIがクラウドからエッジへ移行するにつれて、その技術は異常検知からスマートショッピング、監視、ロボット、工場自動化など、ますます多様なユースケースで使用されるようになっています。したがって、一つのソリューションではすべてをカバーすることができません。ただし、カメラを備えたデバイスの急速な成長に伴い、AIはリアルタイムのビデオデータを分析してビデオモニタリングを自動化し、安全性を高め、業務効率を向上させ、より良い顧客体験を提供するために最も広く採用されています。結果として、業界内で競争力を獲得しています。ビデオ分析をよりよくサポートするためには、エッジAIの展開でシステムパフォーマンスを最適化するための戦略を理解する必要があります。
AIシステムのパフォーマンスを最適化する戦略には次のものがあります
- 必要なパフォーマンスレベルを満たすか超えるために、適切なサイズのコンピュートエンジンを選択すること。AIアプリケーションでは、これらのコンピュートエンジンはビジョンパイプライン全体の機能を実行する必要があります(つまり、ビデオのプリおよびポスト処理、ニューラルネットワークの推論)。
AIアクセラレータ(CPUやGPUではなく、独立しているかSoCに統合されている機能)が必要になる場合があります。
- スループットとレイテンシーの違いを理解すること。スループットはシステムでデータを処理できる速度を示し、レイテンシーはシステムを経由するデータ処理の遅延を測定し、リアルタイムのレスポンスに関連しています。たとえば、システムは1秒間に100フレームの画像データ(スループット)を生成できますが、画像がシステムを通過するのに100ms(レイテンシー)かかります。
- 将来の成長ニーズ、変化する要件、進化する技術に対応するためのAIパフォーマンスのスケーリング能力を考慮すること(たとえば、機能性と精度を向上させるためのより高度なAIモデル)います。AIアクセラレータをモジュール形式で使用するか、追加のAIアクセラレータチップを使用してパフォーマンスのスケーリングを実現できます。
可変AIパフォーマンス要件の理解
実際のパフォーマンス要件はアプリケーションによって異なります。通常、ビデオアナリティクスの場合、システムはカメラからのデータストリームを30-60フレーム/秒で処理し、解像度1080pまたは4kである必要があります。AI対応のカメラは単一のストリームを処理し、エッジアプライアンスは複数のストリームを並行して処理する必要があります。いずれの場合でも、エッジAIシステムはカメラのセンサーデータをAI推論セクションの入力要件に一致する形式に変換するための前処理機能をサポートする必要があります(図1)。
前処理機能は、生データを受け取り、リサイズ、正規化、カラースペース変換などのタスクを実行してから、AIアクセラレータで実行されるモデルの入力にフィードします。前処理には、OpenCVのような効率的なイメージ処理ライブラリを使用して前処理時間を短縮できます。ポストプロセッシングでは、推論の出力を解析します。非最大抑制(NMSはほとんどの物体検出モデルの出力を解釈します)や画像表示などのタスクを使用して、境界ボックス、クラスラベル、信頼スコアなどの実行可能な情報を生成します。

AIモデルの推論には、アプリケーションの能力に応じてフレームごとに複数のニューラルネットワークモデルを処理するという追加の課題があります。コンピュータビジョンアプリケーションでは、通常、複数のAIタスクが関連し、複数のモデルのパイプラインが必要になります。さらに、1つのモデルの出力が次のモデルの入力になることがよくあります。つまり、アプリケーション内のモデルはしばしば互いに依存し、順次実行する必要があります。実行するモデルの正確なセットは静的ではなく、フレームごとに動的に変化する場合もあります。
複数のモデルを動的に実行するという課題は、モデルを保存するために専用かつ十分に大きなメモリを持つ外部のAIアクセラレータを必要とします。SoC内部の統合型AIアクセラレータは、共有メモリサブシステムや他のリソースによって課せられる制約のため、複数のモデルのワークロードを管理することができない場合があります。
たとえば、動き予測ベースのオブジェクト追跡は、将来の位置で追跡対象を識別するために連続的な検出に依存します。この手法の有効性は、検出の漏れ、遮蔽、または対象物が視野から抜けることにより、点滅する場合に制限されます。一度見失うと、対象物の追跡を再関連付けする方法はありません。再識別を追加すれば、この制限を解消できますが、視覚的な外観埋め込み(つまり、画像の指紋)が必要です。外観埋め込みは、最初のネットワークによって検出されたバウンディングボックスの中に含まれる画像を処理して特徴量ベクトルを生成するために、2つ目のネットワークを使用します。この埋め込みは、時間や空間に関係なく、再度対象物を識別するために使用できます。視野内で検出された各オブジェクトに対して埋め込みが生成される必要があるため、処理要件はシーンが混雑するにつれて増加します。リアルタイムな検出および埋め込みのスケーラビリティのために、高精度/高解像度/高フレームレートの検出を実行するために十分な余地を確保することとの間で注意深く考慮する必要があります。処理要件を満たすための1つの方法は、専用のAIアクセラレータを使用することです。先述のように、SoCのAIエンジンは共有メモリリソースの不足により、複数のモデルのワークロードを処理できません。モデルの最適化も処理要件を低減するために使用できますが、パフォーマンスと/または精度に影響を与える可能性があります。
システムレベルのオーバーヘッドでAIパフォーマンスを制限しないでください
スマートカメラやエッジアプライアンスでは、統合SoC(ホストプロセッサ)がビデオフレームを取得し、前述の前処理ステップを実行します。これらの機能は、SoCのCPUコアまたはGPU(利用可能な場合)で実行することもできますが、SoC内の専用ハードウェアアクセラレータ(例:画像信号プロセッサ)でも実行できます。これらの前処理ステップが完了した後、SoCに統合されたAIアクセラレータは、システムメモリからこの量子化された入力に直接アクセスすることができます。また、独立したAIアクセラレータの場合は、通常、USBまたはPCIeインターフェースを介して推論のために入力が配信されます。
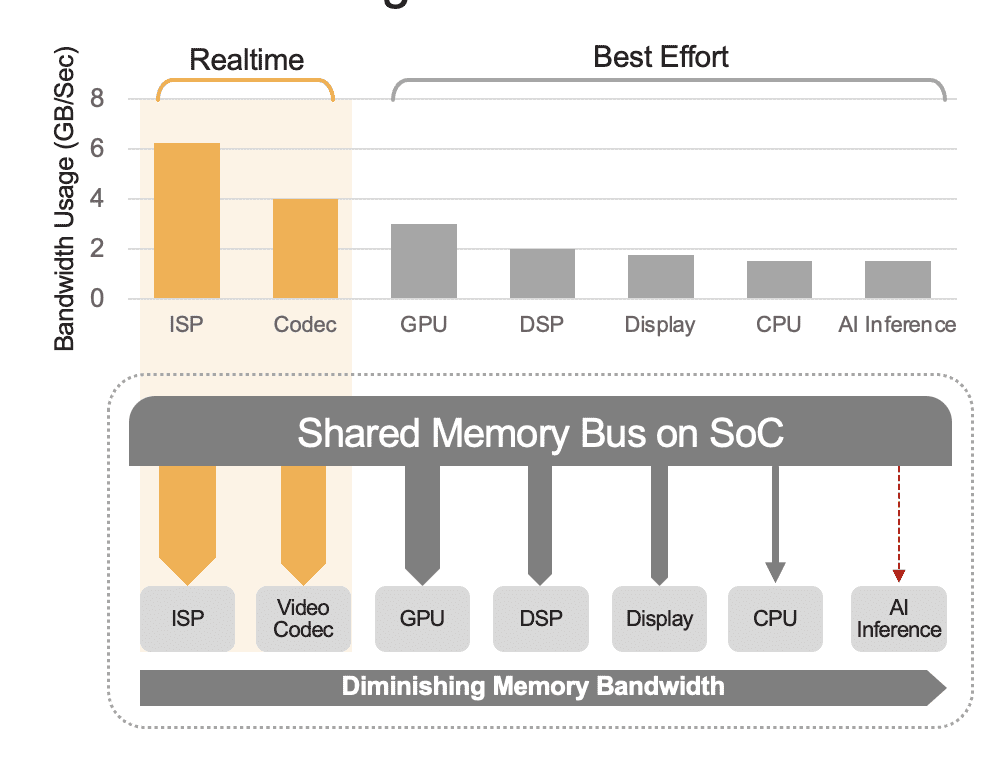
統合SoCには、CPU、GPU、AIアクセラレータ、ビジョンプロセッサ、ビデオエンコーダ/デコーダ、画像信号プロセッサ(ISP)など、さまざまな計算ユニットが含まれることがあります。これらの計算ユニットはすべて同じメモリバスを共有し、同じメモリにアクセスします。さらに、CPUとGPUは推論にも関与する場合があり、これらのユニットは展開されたシステムで他のタスクを実行することになります。これがシステムレベルのオーバーヘッドというものです(図2を参照)。
多くの開発者は、組み込みAIアクセラレータのパフォーマンスを評価する際に、総合パフォーマンスに対するシステムレベルのオーバーヘッドの影響を考慮せずに誤った判断をします。例えば、統合SoCに組み込まれた50 TOPSのAIアクセラレータでYOLOベンチマークを実行した場合、ベンチマークの結果は100推論/秒(IPS)になるかもしれません。しかし、他の計算ユニットすべてがアクティブな展開システムでは、その50 TOPSは12 TOPS程度に減少し、総合パフォーマンスは25 IPS(25%の利用率を仮定)にしかなりません。システムのオーバーヘッドは、プラットフォームが常にビデオストリームを処理し続けている場合には常に影響を与えます。また、独立したAIアクセラレータ(Kinara Ara-1、Hailo-8、Intel Myriad Xなど)の場合、システムレベルの利用率は90%以上になる可能性があります。なぜなら、ホストSoCが推論機能を開始し、AIモデルの入力データを転送した後、アクセラレータは専用のメモリを利用してモデルのウェイトとパラメータにアクセスし、自律的に実行されるからです。
エッジでの動画解析には低レイテンシが必要です
ここまでは、フレームレートとTOPSの観点からAIのパフォーマンスについて議論してきました。しかし、低レイテンシはシステムのリアルタイム応答性を提供するためにも重要な要件です。たとえば、ゲーミングでは、低レイテンシがシームレスで反応性の高いゲーム体験に不可欠です。特にモーションコントロールゲームや仮想現実(VR)システムではますます重要です。自動運転システムでは、低レイテンシはリアルタイムの物体検出、歩行者認識、車線検出、交通標識認識に欠かせません。自動運転システムでは、検出から実際のアクションまでのエンドツーエンドのレイテンシが150ms未満であることが一般的です。同様に、製造業では、リアルタイムの欠陥検出、異常検知、ロボットガイダンスには低レイテンシのビデオ解析が必要で、効率的な運用と生産停止の最小化を保証します。
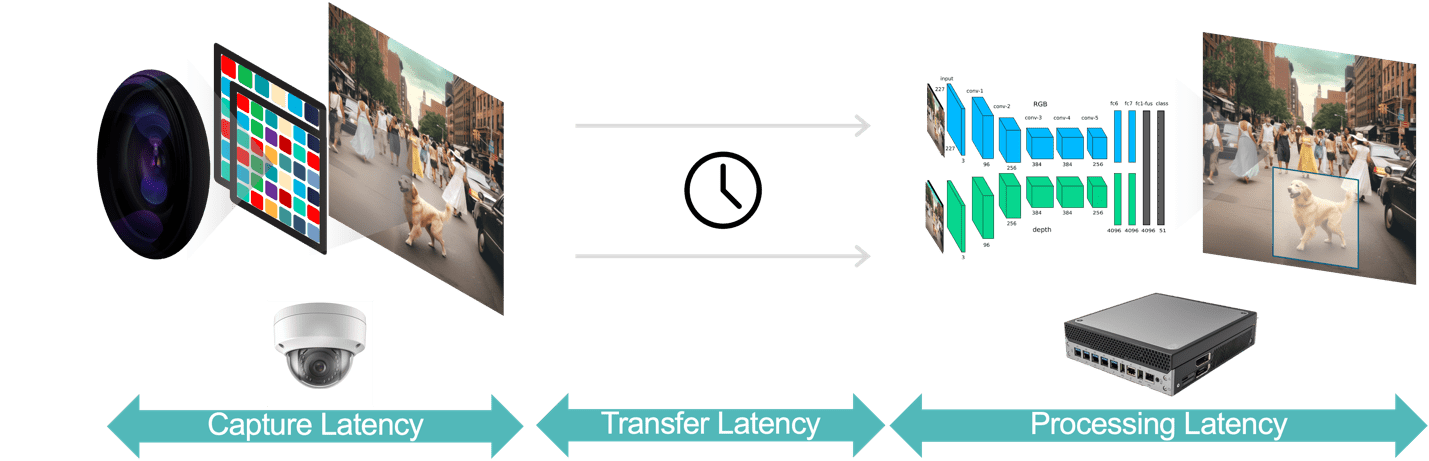
一般的に、ビデオ解析アプリケーションのレイテンシには3つの要素があります(図3):
- データキャプチャのレイテンシは、カメラセンサがビデオフレームをキャプチャする時間から解析システムでのフレームの利用可能時までの時間です。センサとレイテンシの低いプロセッサを備えたカメラの選択、最適なフレームレートの選択、効率的なビデオ圧縮形式の使用などでこのレイテンシを最適化できます。
- データ転送のレイテンシは、キャプチャされた圧縮ビデオデータがカメラからエッジデバイスやローカルサーバーに転送されるまでの時間を指します。これには各エンドポイントで発生するネットワークの処理遅延も含まれます。
- データ処理のレイテンシは、エッジデバイスがフレームの展開や解析アルゴリズム(例:モーション予測に基づくオブジェクトトラッキング、顔認識)などのビデオ処理タスクを実行する時間を指します。前述のように、複数のAIモデルを1つのビデオフレームごとに実行する必要があるアプリケーションでは、処理のレイテンシがさらに重要です。
データ処理のレイテンシは、チップ内およびコンピュートとさまざまなレベルのメモリ階層間でのデータ移動を最小限に抑えたアーキテクチャを持つAIアクセラレータを使用することで最適化できます。また、レイテンシとシステムレベルの効率性を向上させるためには、アーキテクチャがモデル間のスイッチング時間をゼロ(またはほぼゼロ)にサポートする必要があります。これにより、前述したマルチモデルのアプリケーションのサポートが向上します。性能とレイテンシを向上させるための別の要素は、アルゴリズムの柔軟性です。つまり、一部のアーキテクチャは特定のAIモデルにのみ最適化されていますが、急速に変化するAI環境では、より高い性能とより高い精度のための新しいモデルが毎日のように出現しています。したがって、モデルのトポロジ、オペレータ、サイズに実用的な制限のないエッジAIプロセッサを選択してください。
最大限のパフォーマンスを引き出すには、パフォーマンスとレイテンシ要件、システムオーバーヘッドなど、さまざまな要素を考慮する必要があります。成功する戦略は、SoCのAIエンジンのメモリとパフォーマンスの制約を克服するために外部のAIアクセラレータを使用することを検討すべきです。C.H. Cheeは、製品マーケティングとマネジメントのエグゼクティブとして実績のある人物であり、半導体産業における製品とソリューションの推進に豊富な経験を持っています。彼の専門分野は、エンタープライズや一般消費者向けのビジョンベースのAI、接続性、およびビデオインタフェースです。起業家としても活動しているCheeは、2つのビデオ半導体ベンチャーを共同設立し、公開された半導体企業に買収されました。Cheeは製品マーケティングチームをリードし、優れた結果を達成することに焦点を当てた小さなチームとの協業を楽しんでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






