「Apache Sparkにおける出力ファイルサイズの最適化」
Optimizing Output File Size in Apache Spark
パーティション、リパーティション、およびコアレス操作の包括的なガイド
大規模なSparkデータ処理操作の舵に自分自身を想像してみてください。 Sparkの最適化に関する議論では、I/Oパフォーマンスと拡張された並列処理を実現するために、各データファイルのサイズはデフォルトのパーティションサイズである128MB程度にするという経験則がよく言われます[1]。
ファイルをデータ処理の海を航行する船と考えてみてください。船が小さすぎると、ドッキングや再出航に多くの時間を無駄に費やします。これは、実行エンジンがファイルを開くための余分な時間、ディレクトリのリスト化、オブジェクトのメタデータの取得、データ転送の設定、およびファイルの読み取りにかかる時間を表すメタファーです。逆に、船が大きすぎてポートの多くのドックを使用しない場合、単一の長時間の積み荷の読み込みと降ろし作業を待たなければならず、これはクエリ処理が単一のリーダーがファイル全体の読み取りを完了するまで待機することを表し、並列処理が減少します[図1]。
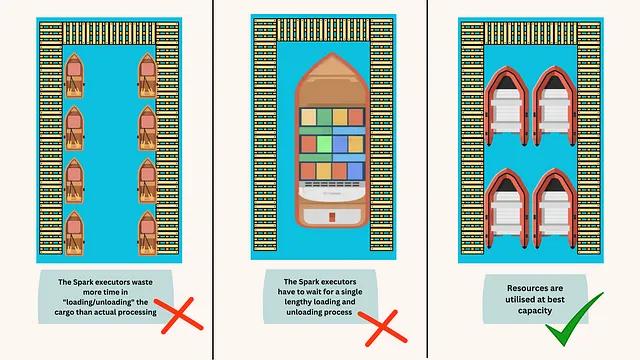
ファイルサイズの最適化の重要性を生き生きと示すために、次の図を参照してください。この具体的な例では、各テーブルが8 GBのデータを保持しています。
- 「ChatGPTを活用したデータクリーニングと前処理の自動化」
- 「Microsoft AI Researchは、Pythonで直接ONNXモデルを作成するためのONNXスクリプトライブラリをオープンソース化しました」
- Google AIがAdaTapeを導入:トランスフォーマーベースのアーキテクチャを持ち、適応的なテープトークンを通じてニューラルネットワークでの動的な計算を可能にする新しいAIアプローチ
ただし、この繊細なバランスを取ることは容易な作業ではありません、特に大規模なバッチジョブを扱う場合です。出力ファイルの数を制御するのが難しい場合があります。このガイドは、それを取り戻すのに役立ちます。
理解の鍵:パーティション
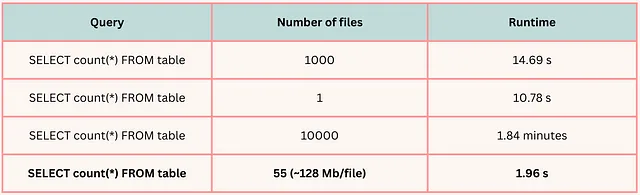
書き込み操作を実行すると、ディスクに保存される出力ファイルの数は、Sparkエグゼキュータのパーティション数に等しいです。ただし、書き込み操作を実行する前にパーティション数を判断することは難しい場合があります。
テーブルを読み込む際、Sparkは最大サイズが128MBのブロックを読み込むようにデフォルトに設定されています(ただし、これはsql.files.maxPartitionBytesを使用して変更できます)。したがって、パーティション数は入力のサイズに依存します。しかし、実際には、パーティション数はおそらくsql.shuffle.partitionsパラメータと同じになります。この数値はデフォルトで200に設定されていますが、より大きなワークロードの場合、十分ではありません。適切なシャッフルパーティション数を設定する方法については、このビデオをご覧ください。
ETLでワイドな変換が少なくとも1つ適用される場合、Sparkエグゼキュータのパーティション数はsql.shuffle.partitionsと等しくなります。狭い変換のみが適用される場合、パーティション数はファイルを読み込む際に作成される数に一致します。
シャッフルパーティションの数を設定することは、パーティションされていないテーブルを扱う場合にのみ、総パーティションの高レベルの制御を提供します。パーティションされたテーブルの領域に入ると、sql.shuffle.partitionsパラメータを変更しても各データファイルのサイズを簡単に制御できなくなります。
ステアリングホイール:リパーティションとコアレス
ランタイムでパーティションの数を管理する主な方法は2つあります:repartition()とcoalesce()です。以下に簡単な説明を示します:
リパーティション:repartition(partitionCols, n_partitions)は2つのパラメータ(パーティション数とパーティション化列)を持つ遅延変換です。実行されると、Sparkはパーティションをパーティション化列に従ってクラスタ全体でシャッフルします。ただし、テーブルが保存された後は、リパーティションに関する情報は失われます。したがって、この有用な情報はファイルを読み込む際には使用されません。
df = df.repartition("column_name", n_partitions)Coalesce:coalesce(num_partitions)は遅延変換ですが、引数は1つだけです- パーティションの数です。重要なことに、coalesce操作はデータをクラスター全体にシャッフルしないため、repartitionよりも速くなります。また、coalesceはパーティションの数を減らすことしかできず、パーティションの数を増やす場合には機能しません。
df = df.coalesce(num_partitions)ここで理解しておくべき主要なポイントは、coalesceメソッドを使用することが一般的にはより有益であるということです。これは、repartitioningが役に立たないという意味ではありません。特に、実行時にデータフレームのパーティションの数を調整する必要がある場合には役立ちます。
ETLプロセスで複数のサイズの異なるテーブルを扱い、複雑な変換や結合を行う経験から、sql.shuffle.partitionsが必要な制御を提供してくれないことがわかりました。たとえば、同じ数のシャッフルパーティションを使用して、同じETLで2つの小さなテーブルと2つの大きなテーブルを結合する場合、効率的ではありません- 小さなテーブルには過剰なパーティションがあり、大きなテーブルには十分なパーティションがないことになります。また、repartitioningは歪んだ結合や歪んだデータの問題を回避するのにも役立ちます [2]。
それにもかかわらず、repartitioningはテーブルをディスクに書き込む前には適しておらず、ほとんどの場合、coalesceで置き換えることができます。coalesceはディスクに書き込む前にいくつかの理由でrepartitionよりも優れています:
- クラスター全体でデータを不必要に再シャッフルしないようにします。
- 論理的なヒューリスティックに従ってデータの順序を設定することができます。書き込む前にrepartitionメソッドを使用すると、データがクラスター全体で再シャッフルされ、順序が失われます。一方、coalesceを使用すると、データは再分配されるのではなく、まとめられるため、順序が保持されます。
データの順序が重要である理由を見てみましょう。
地平線上の順序:データの順序の重要性
上記で説明したように、repartitionメソッドを適用すると、Sparkはテーブルのパーティション情報をメタデータに保存しません。しかし、ビッグデータを扱う場合、これは2つの理由で重要な情報です:
- クエリ時のテーブルのスキャンがはるかに高速化されます。
- 圧縮が改善されます- 圧縮可能な形式(Parquet、CSV、Jsonなど)の場合。これは、なぜ重要なのかを理解するための素晴らしい記事です。
重要なポイントは、データを保存する前にデータを順序付けることです。情報はメタデータに保持され、クエリ時に使用されるため、クエリがはるかに高速化されます。
さて、非パーティションテーブルとパーティションテーブルへの保存の違いと、パーティションテーブルへの保存がいくつかの追加の調整を必要とする理由を探ってみましょう。
パーティションテーブルでのファイルサイズの管理
非パーティションテーブルの場合、保存操作中のファイル数の管理は直接的なプロセスです。保存前にcoalesceメソッドを使用することで、データがソートされているかどうかに関係なく、タスクを達成することができます。
# 非パーティションテーブルを保存する前にcoalesceメソッドを使用する例df.coalesce(10).write.format("parquet").save("/path/to/output")ただし、データがパーティションテーブルを扱う場合、データをまとめる前にデータを整理する必要があるため、この方法は効果的ではありません。これが起こる理由を理解するためには、データが順序付けられている場合とそうでない場合にSparkエグゼキュータで行われるアクションについて調べる必要があります [fig.2]。
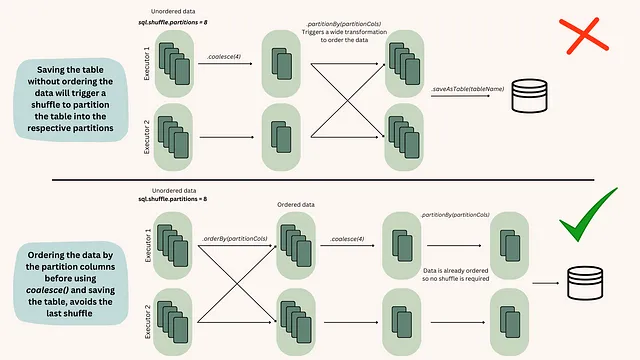
したがって、パーティションテーブルにデータを保存する標準的なプロセスは次のようになります:
# データを順序付けた後にcoalesceメソッドを使用してパーティションテーブルに保存する例df.orderBy("columnName").coalesce(10).write.format("parquet").save("/path/to/output_partitioned")その他のナビゲーション支援
repartition と coalesce を超えて、maxnumberofrecords も便利です。これは、ファイルがあまり大きくなりすぎないようにするための便利なメソッドであり、上記のメソッドと併用することができます。
df.write.option("maxRecordsPerFile", 50000).save("file_path")最終的な考え
Spark ジョブでファイルサイズをマスターするには、試行錯誤が必要です。ストレージスペースが安価で、処理能力がすぐに利用できる時代では、最適化を見落とすことが簡単です。しかし、テラバイトやペタバイトのデータ処理が当たり前になる中で、これらのシンプルな最適化技術を忘れると、経済的、時間的、環境的なコストがかかる可能性があります。
この記事が、ETLプロセスを効率的に調整するための力を与えてくれることを願っています。経験豊富な船長のように、自信と明確さを持って Spark の水域を航海してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
