「Amazon EC2 Inf1&Inf2インスタンス上のFastAPIとPyTorchモデルを使用して、AWS Inferentiaの利用を最適化する」
Optimizing AWS Inferentia usage with FastAPI and PyTorch models on Amazon EC2 Inf1 & Inf2 instances
Deep Learningモデルをスケールで展開する際には、パフォーマンスとコストのメリットを最大限に活用するために、基盤となるハードウェアを効果的に活用することが重要です。高スループットと低レイテンシが必要なプロダクションワークロードの場合、Amazon Elastic Compute Cloud(EC2)インスタンス、モデルサービングスタック、展開アーキテクチャの選択は非常に重要です。非効率なアーキテクチャはアクセラレータの最適な利用と不必要に高い生産コストを引き起こすことがあります。
この記事では、AWS Inferentiaデバイス(Amazon EC2 Inf1およびAmazon EC Inf2インスタンスに存在する)にFastAPIモデルサーバーを展開するプロセスを説明します。また、最大限のハードウェア利用率を実現するために、サンプルモデルをすべてのNeuronCoresに並列に展開するホスティングもデモンストレーションします。
ソリューションの概要
FastAPIは、FlaskやDjangoなどの従来のフレームワークよりもはるかに高速なPythonアプリケーションの提供に特化したオープンソースのウェブフレームワークです。FastAPIは、広く使用されているWeb Server Gateway Interface(WSGI)ではなく、非同期サーバーゲートウェイインターフェース(ASGI)を利用してリクエストを非同期で処理します。これにより、FastAPIはレイテンシに敏感なリクエストを扱うための理想的な選択肢となります。FastAPIを使用して、指定されたポートを介してクライアントリクエストを受け付けるInferentia(Inf1/Inf2)インスタンス上のエンドポイントをホストするサーバーを展開することができます。
私たちの目標は、ハードウェアの最大限の利用を通じて最高のパフォーマンスを最低のコストで実現することです。これにより、より少ないアクセラレータでより多くの推論リクエストを処理することができます。各AWS Inferentia1デバイスには4つのNeuronCores-v1が含まれており、各AWS Inferentia2デバイスには2つのNeuronCores-v2が含まれています。AWS Neuron SDKを使用することで、各NeuronCoresを並列に利用することができます。これにより、スループットを損なうことなく4つ以上のモデルを並列にロードおよび推論するためのより多くの制御が可能となります。
- 「GoogleやOpenAIなどの主要なテック企業がAIの安全性に関する取り組みを約束」
- 「Llama 2の機能を実世界のアプリケーションに活用する:FastAPI、Celery、Redis、およびDockerを使用したスケーラブルなチャットボットの構築」
- 「汗をかくロボットが、人々が高温による影響を理解するのを助けるかもしれない」という記事がありました
FastAPIでは、Pythonウェブサーバー(Gunicorn、Uvicorn、Hypercorn、Daphne)の選択肢があります。これらのウェブサーバーは、基礎となる機械学習(ML)モデルの上に抽象化レイヤーを提供します。リクエストを送信するクライアントは、ホストされたモデルを知る必要がありません。クライアントは、サーバーにデプロイされたモデルの名前やバージョンを知る必要はありません。エンドポイント名は、モデルをロードして実行する関数へのプロキシとなります。これに対して、TensorFlow Servingなどのフレームワーク固有のサービングツールでは、モデルの名前とバージョンはエンドポイント名の一部となります。サーバーサイドでモデルが変更された場合、クライアントは新しいエンドポイントに対してAPI呼び出しを知り、変更する必要があります。そのため、A/Bテストなどのバージョンモデルを継続的に進化させる場合は、FastAPIを使用した汎用のPythonウェブサーバーを使用することが便利です。エンドポイント名は静的です。
ASGIサーバーの役割は、指定された数のワーカーを生成し、クライアントリクエストを待機し、推論コードを実行することです。サーバーの重要な機能の1つは、要求されたワーカーの数が利用可能でアクティブであることを確認することです。ワーカーがキルされた場合、サーバーは新しいワーカーを起動する必要があります。このコンテキストでは、サーバーとワーカーはそれぞれUnixプロセスID(PID)で識別される場合があります。この記事では、Pythonウェブサーバーとして人気のあるHypercornサーバーを使用します。
この記事では、FastAPIを使用してAWS Inferentia NeuronCores上にディープラーニングモデルを展開するためのベストプラクティスを共有します。複数のモデルを別々のNeuronCoresに展開し、同時に呼び出すことができます。このセットアップにより、複数のモデルを同時に推論することができ、NeuronCoreの利用率が最大限になります。コードはGitHubリポジトリで入手できます。以下の図は、EC2 Inf2インスタンス上でソリューションを構築する方法のアーキテクチャを示しています。
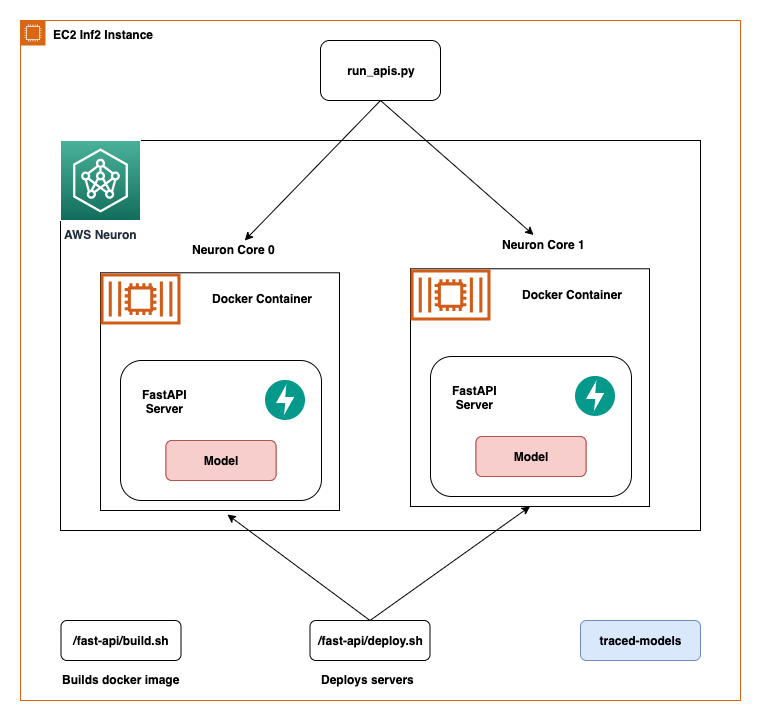
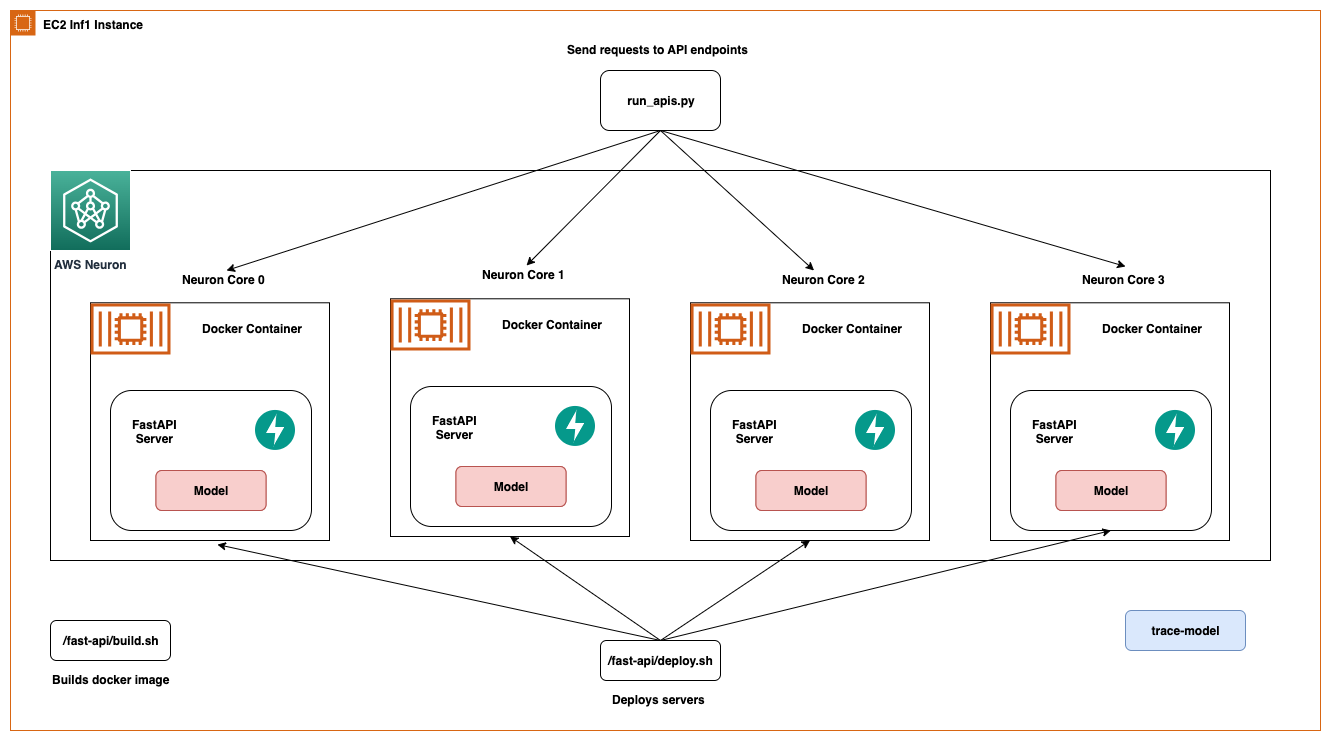
同じアーキテクチャはEC2 Inf1インスタンスタイプにも適用されますが、4つのコアがあります。したがって、アーキテクチャ図は少し変更されます。
AWS Inferentia NeuronCores
AWS Neuronが提供するツールとNeuronCoresとの連携について詳しく見てみましょう。以下の表は、Inf1およびInf2インスタンスタイプごとのNeuronCoresの数を示しています。ホストvCPUsとシステムメモリは、利用可能なすべてのNeuronCoresで共有されます。
| インスタンスサイズ | # Inferentiaアクセラレータ | # NeuronCores-v1 | vCPUs | メモリ(GiB) |
| Inf1.xlarge | 1 | 4 | 4 | 8 |
| Inf1.2xlarge | 1 | 4 | 8 | 16 |
| Inf1.6xlarge | 4 | 16 | 24 | 48 |
| Inf1.24xlarge | 16 | 64 | 96 | 192 |
| インスタンスサイズ | # Inferentiaアクセラレータ | # NeuronCores-v2 | vCPUs | メモリ(GiB) |
| Inf2.xlarge | 1 | 2 | 4 | 32 |
| Inf2.8xlarge | 1 | 2 | 32 | 32 |
| Inf2.24xlarge | 6 | 12 | 96 | 192 |
| Inf2.48xlarge | 12 | 24 | 192 | 384 |
Inf2インスタンスは、Inf1インスタンスのNeuronCore-v1に対して新しいNeuronCores-v2を備えています。コア数は少ないですが、Inf1インスタンスと比べて4倍のスループットと10倍の低レイテンシを提供することができます。Inf2インスタンスは、Generative AIやOPT/GPTファミリーのLarge Language Models(LLM)、Stable Diffusionなどのビジョン変換器などのDeep Learningワークロードに最適です。
Neuron Runtimeは、Neuronデバイス上でモデルを実行する責任を持ちます。Neuron Runtimeは、どのNeuronCoreがどのモデルを実行し、どのように実行するかを決定します。Neuron Runtimeの設定は、プロセスレベルで環境変数を使用して制御されます。デフォルトでは、Neuronフレームワークの拡張機能がユーザーのためにNeuron Runtimeの設定を行いますが、より最適化された動作を実現するために明示的な設定も可能です。
2つのよく使用される環境変数はNEURON_RT_NUM_CORESとNEURON_RT_VISIBLE_CORESです。これらの環境変数を使用すると、PythonプロセスをNeuronCoreに関連付けることができます。NEURON_RT_NUM_CORESでは、指定した数のコアをプロセスに予約することができます。また、NEURON_RT_VISIBLE_CORESでは、NeuronCoreの範囲を予約することができます。たとえば、NEURON_RT_NUM_CORES=2 myapp.pyは2つのコアを予約し、NEURON_RT_VISIBLE_CORES='0-2' myapp.pyはmyapp.pyに対して0番、1番、2番のコアを予約します。AWS Inferentiaチップ上のNeuronCoresもデバイス間で予約することができます。したがって、Ec2 Inf1インスタンスタイプでは、NEURON_RT_VISIBLE_CORES='0-5' myapp.pyはdevice1の最初の4つのコアとdevice2の1つのコアを予約します。同様に、EC2 Inf2インスタンスタイプでは、この設定はdevice1とdevice2の2つのコア、およびdevice3の1つのコアを予約します。次の表は、これらの変数の設定をまとめたものです。
| 名前 | 説明 | タイプ | 期待される値 | デフォルト値 | RTバージョン |
NEURON_RT_VISIBLE_CORES |
プロセスが必要とする特定のNeuronCoresの範囲 | 整数範囲(例:1-3) | 0からシステム内の最大NeuronCoreまでの任意の値または範囲 | なし | 2.0以上 |
NEURON_RT_NUM_CORES |
プロセスが必要とするNeuronCoresの数 | 整数 | 1からシステム内の最大NeuronCoreまでの値 | 0(すべてを意味する) | 2.0以上 |
すべての環境変数のリストについては、「Neuronランタイムの設定」を参照してください。
デフォルトでは、モデルをロードする際には、モデルは明示的に前の環境変数で指定されていない限り、NeuronCore 0にロードされ、その後NeuronCore 1にロードされます。前述のように、NeuronCoresは利用可能なホストvCPUとシステムメモリを共有します。したがって、各NeuronCoreに展開されたモデルは利用可能なリソースを競合します。モデルがNeuronCoresを大幅に利用している場合、これは問題になりません。しかし、モデルがNeuronCoresの一部のみを実行し、残りの部分をホストvCPUで実行している場合、NeuronCoreごとのCPUの利用可能性を考慮する必要があります。これは、インスタンスの選択にも影響します。
次の表は、各NeuronCoreに1つのモデルが展開された場合のホストvCPUとシステムメモリの利用可能数を示しています。アプリケーションのNeuronCoreの使用状況、vCPU、およびメモリの使用状況に応じて、どの構成が最もパフォーマンスが高いかを確認するためにテストを実行することをおすすめします。Neuron Topツールは、コアの利用状況やデバイスおよびホストのメモリの利用状況を可視化するのに役立ちます。これらのメトリックに基づいて情報を得ることで、的確な意思決定が可能です。このブログの最後でNeuron Topの使用方法を説明します。
| インスタンスサイズ | # Inferentiaアクセラレータ | # モデル | vCPU/モデル | メモリ/モデル(GiB) |
| Inf1.xlarge | 1 | 4 | 1 | 2 |
| Inf1.2xlarge | 1 | 4 | 2 | 4 |
| Inf1.6xlarge | 4 | 16 | 1.5 | 3 |
| Inf1.24xlarge | 16 | 64 | 1.5 | 3 |
| インスタンスサイズ | # Inferentiaアクセラレータ | # モデル | vCPUs/モデル | メモリ/モデル(GiB) |
| Inf2.xlarge | 1 | 2 | 2 | 8 |
| Inf2.8xlarge | 1 | 2 | 16 | 64 |
| Inf2.24xlarge | 6 | 12 | 8 | 32 |
| Inf2.48xlarge | 12 | 24 | 8 | 32 |
Neuron SDKの機能を自分自身でテストするには、最新のPyTorch向けNeuronの機能をチェックしてください。
システムのセットアップ
この解決策で使用されるシステムのセットアップは次のとおりです:
- インスタンスサイズ – 6xlarge(Inf1を使用する場合)、Inf2.xlarge(Inf2を使用する場合)
- インスタンスのイメージ – Deep Learning AMI Neuron PyTorch 1.11.0(Ubuntu 20.04)20230125
- モデル – https://huggingface.co/twmkn9/bert-base-uncased-squad2
- フレームワーク – PyTorch
解決策のセットアップ
解決策のセットアップにはいくつかの手順が必要です。まず、EC2インスタンスがAmazon Elastic Container Registryとのやり取りを許可するためにアサインするIAMロールを作成します。
ステップ1:IAMロールのセットアップ
- コンソールにログインし、IAM > ロール > ロールの作成にアクセスします
- 信頼できるエンティティタイプとして
AWSサービスを選択します - 使用ケースとしてEC2を選択します
- 次へをクリックすると、利用可能なすべてのポリシーが表示されます
- この解決策では、EC2インスタンスにAmazon ECRへのフルアクセスを与えます。AmazonEC2ContainerRegistryFullAccessをフィルタリングして選択します。
- 次へを押してロール名を
inf-ecr-accessとします
注意:アタッチしたポリシーにより、EC2インスタンスがAmazon ECRに対してフルアクセスを持つことができます。本番ワークロードでは最小特権の原則に従うことを強くお勧めします。
ステップ2:AWS CLIのセットアップ
上記で指定されたDeep Learning AMIを使用している場合、AWS CLIがインストールされています。異なるAMI(Amazon Linux 2023、Base Ubuntuなど)を使用している場合は、このガイドに従ってCLIツールをインストールしてください。
CLIツールがインストールされたら、aws configureコマンドを使用してCLIを設定します。アクセスキーがある場合はここに追加できますが、AWSサービスとのやり取りには必要ありません。IAMロールを使用しています。
注意:デフォルトプロファイルを作成するために少なくとも1つの値(デフォルトリージョンまたはデフォルトの出力形式)を入力する必要があります。この例では、リージョンとしてus-east-2、出力形式としてjsonを使用します。
GitHubリポジトリをクローンする
GitHubのリポジトリは、AWS Inferentiaインスタンス上のFastAPIを使用してモデルを展開するために必要なすべてのスクリプトを提供しています。この例では、再利用可能なソリューションを作成できるように、Dockerコンテナを使用しています。この例には、ユーザーが入力を提供するためのconfig.propertiesファイルが含まれています。
# Dockerイメージとコンテナの名前
docker_image_name_prefix=<Dockerイメージ名>
docker_container_name_prefix=<Dockerコンテナ名>
# 展開のセットアップ
path_to_traced_models=<トレースされたモデルのパス>
compiled_model=<コンパイルされたモデルのファイル名>
num_cores=<モデルサーバを展開するためのNeuronCoreの数>
num_models_per_server=<サーバごとにロードされるモデルの数>構成ファイルには、DockerイメージとDockerコンテナのためにユーザー定義の名前プレフィックスが必要です。 fastapiおよびtrace-modelフォルダのbuild.shスクリプトは、これを使用してDockerイメージを作成します。
AWS Inferentiaでモデルをコンパイルする
まず、モデルをトレースし、PyTorch Torchscript形式の.ptファイルを生成します。 trace-modelディレクトリにアクセスして、.envファイルを修正します。選択したインスタンスのタイプに応じて、.envファイル内のCHIP_TYPEを変更します。例として、ガイドとしてInf2を選択します。同じ手順はInf1の展開プロセスにも適用されます。
次に、同じファイル内でデフォルトのリージョンを設定します。このリージョンは、ECRリポジトリを作成し、Dockerイメージをこのリポジトリにプッシュするために使用されます。また、このフォルダには、AWS Inferentia上でbert-base-uncasedモデルをトレースするために必要なすべてのスクリプトが用意されています。このスクリプトは、Hugging Faceで利用可能なほとんどのモデルに使用できます。Dockerfileには、Neuronでモデルを実行するためのすべての依存関係が含まれており、trace-model.pyコードがエントリーポイントとして実行されます。
Neuronのコンパイルについて
Neuron SDKのAPIは、PyTorchのPython APIに非常に似ています。 PyTorchのtorch.jit.trace()は、モデルとサンプル入力テンソルを引数に取ります。サンプル入力はモデルに供給され、その入力がモデルのレイヤーを通過する際に呼び出される操作はTorchScriptとして記録されます。PyTorchのJITトレースについて詳しくは、次のドキュメントを参照してください。
torch.jit.trace()と同様に、以下のコードを使用してモデルがAWS Inferentiaでコンパイルできるか確認できます(inf1インスタンス向け)。
import torch_neuron
model_traced = torch.neuron.trace(model,
example_inputs,
compiler_args =
[‘--fast-math’, ‘fp32-cast-matmul’,
‘--neuron-core-pipeline-cores’,’1’],
optimizations=[torch_neuron.Optimization.FLOAT32_TO_FLOAT16])inf2の場合、ライブラリの名前はtorch_neuronxです。以下は、inf2インスタンスに対してモデルのコンパイルをテストする方法です。
import torch
import torch_neuronx
model_traced = torch.neuronx.trace(model,
example_inputs,
compiler_args =
[‘--fast-math’, ‘fp32-cast-matmul’,
‘--neuron-core-pipeline-cores’,’1’],
optimizations=[torch_neuronx.Optimization.FLOAT32_TO_FLOAT16])トレースインスタンスを作成した後、以下のように例のテンソル入力を渡すことができます:
answer_logits = model_traced(*example_inputs)最後に、結果のTorchScript出力をローカルディスクに保存します
model_traced.save('./compiled-model-bs-{batch_size}.pt')前のコードに示されているように、compiler_argsおよびoptimizationsを使用して展開を最適化できます。 torch.neuron.trace APIの引数の詳細なリストについては、PyTorch-Neuron trace python APIを参照してください。
次の重要なポイントに注意してください:
- Neuron SDKは、現時点では動的テンソル形状をサポートしていません。したがって、モデルは異なる入力形状に対して別々にコンパイルする必要があります。可変入力形状での推論を実行する詳細については、「Running inference on variable input shapes with bucketing」を参照してください。
- モデルをコンパイルする際にメモリ不足の問題が発生した場合は、AWS InferentiaインスタンスでvCPUまたはメモリがより多いインスタンス、またはc6iやr6iなどの大型インスタンスでモデルをコンパイルしてみてください。コンパイルはCPUのみを使用するため、コンパイル後にはより小さいAWS Inferentiaインスタンスサイズでトレースされたモデルを実行できる可能性があります。
ビルドプロセスの説明
まず、build.shを実行してこのコンテナをビルドします。ビルドスクリプトファイルは、単にベースのDeep LearningコンテナイメージをプルしてHuggingFaceのtransformersパッケージをインストールすることでDockerイメージを作成します。 .env ファイルで指定された CHIP_TYPE に基づいて、docker.properties ファイルが適切な BASE_IMAGE を決定します。この BASE_IMAGE は、AWSが提供するNeuron Runtime用のDeep Learningコンテナイメージを指します。
これは、プライベートのECRリポジトリを介して利用できます。イメージをプルする前に、ログインして一時的なAWSクレデンシャルを取得する必要があります。
aws ecr get-login-password --region <region> | docker login --username AWS --password-stdin 763104351884.dkr.ecr.<region>.amazonaws.com注意: コマンド内のリージョンフラグとリポジトリURI内のリージョンは、.env ファイルに設定したリージョンで置き換える必要があります。
このプロセスを簡単にするために、fetch-credentials.sh ファイルを使用することができます。リージョンは自動的に .env ファイルから取得されます。
次に、push.shスクリプトを使用してイメージをプッシュします。プッシュスクリプトは、Amazon ECRにリポジトリを作成し、コンテナイメージをプッシュします。
最後に、イメージがビルドされてプッシュされたら、run.shを実行してコンテナとして実行し、logs.shで実行中のログを表示できます。コンパイラログ(以下のスクリーンショットを参照)では、Neuron上でコンパイルされた算術演算子の割合とNeuron上で正常にコンパイルされたモデルサブグラフの割合が表示されます。スクリーンショットは bert-base-uncased-squad2 モデルのコンパイラログを示しています。ログには、算術演算子の95.64%がコンパイルされたことが表示され、Neuron上でコンパイルされた演算子とサポートされていない演算子のリストも示されます。
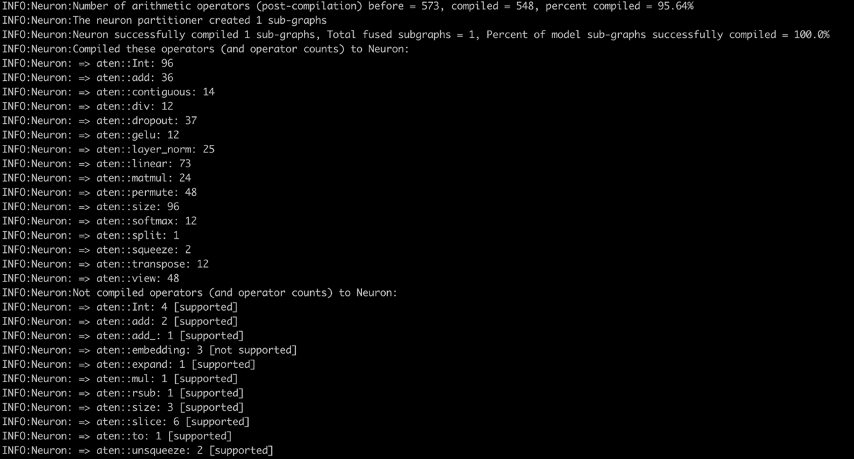
以下は、最新のPyTorch Neuronパッケージでサポートされているすべての演算子のリストです。同様に、最新のPyTorch Neuronxパッケージでサポートされているすべての演算子のリストもあります。
FastAPIを使用してモデルを展開する
モデルがコンパイルされた後、トレースされたモデルは trace-model フォルダに保存されます。この例では、バッチサイズ1用のトレースされたモデルを配置しています。バッチサイズが大きすぎる場合や必要ない場合に備えて、torch.neuron.DataParallel(Inf1用)またはtorch.neuronx.DataParallel(Inf2用)APIを使用することもできます。
fast-apiフォルダには、FastAPIでモデルを展開するためのすべての必要なスクリプトが含まれています。変更せずにモデルを展開するには、deploy.shスクリプトを実行するだけで、FastAPIコンテナイメージをビルドし、指定されたコア数でコンテナを実行し、各FastAPIモデルサーバーに指定されたモデル数を展開します。このフォルダには、.env ファイルも含まれており、CHIP_TYPE と AWS_DEFAULT_REGION を正確に反映するように変更してください。
注意: FastAPIスクリプトは、イメージをビルドし、プッシュし、コンテナとして実行するために使用される環境変数と同じ環境変数に依存しています。FastAPI展開スクリプトは、これらの変数からの最後に知られている値を使用します。したがって、最後にInf1インスタンスタイプ用にモデルをトレースした場合、そのモデルはこれらのスクリプトを介して展開されます。
fastapi-server.pyファイルは、サーバーのホストとモデルへのリクエストの送信を担当して以下の処理を行います:
- プロパティファイルからサーバーごとのモデル数とコンパイル済みモデルの場所を読み取ります
- 可視なNeuronCoresを環境変数としてDockerコンテナに設定し、使用するNeuronCoresを指定するために環境変数を読み取ります
bert-base-uncased-squad2モデルの推論APIを提供しますjit.load()を使用して、configで指定されたサーバーごとのモデル数を読み込み、モデルと必要なトークナイザをグローバルな辞書に保存します
このセットアップでは、各NeuronCoreに格納されているモデルのリストとモデルの数をリストアップするAPIを比較的簡単に設定することができます。同様に、特定のNeuronCoreからモデルを削除するためのAPIも作成できます。
FastAPIコンテナをビルドするためのDockerfileは、モデルのトレースのためにビルドしたDockerイメージを基に構築されています。これが、docker.propertiesファイルがモデルのトレースのためのDockerイメージのECRパスを指定している理由です。私たちのセットアップでは、すべてのNeuronCoreのDockerコンテナは類似しているため、1つのイメージをビルドし、1つのイメージから複数のコンテナを実行することができます。エントリーポイントのエラーを回避するために、DockerfileでENTRYPOINT ["/usr/bin/env"]を指定し、startup.shスクリプトを実行します。この起動スクリプトはすべてのコンテナで同じです。モデルのトレースと同じベースイメージを使用している場合は、build.shスクリプトを実行するだけでこのコンテナをビルドすることができます。トレースモデルと同じく、push.shスクリプトは前と同じです。変更されたDockerイメージとコンテナ名は、docker.propertiesファイルで指定されます。
run.shファイルは以下の操作を行います:
- プロパティファイルからDockerイメージとコンテナ名を読み取ります。プロパティファイルは
config.propertiesファイルを読み取ります。このファイルにはnum_coresのユーザ設定があります。 - 0から
num_coresまでのループを開始し、各コアごとに以下の操作を行います:- ポート番号とデバイス番号を設定します。
NEURON_RT_VISIBLE_CORES環境変数を設定します。- ボリュームマウントを指定します。
- Dockerコンテナを実行します。
わかりやすさのため、Inf1のNeuronCore 0に展開するためのDockerの実行コマンドは次のようになります:
docker run -t -d \
--name $ bert-inf-fastapi-nc-0 \
--env NEURON_RT_VISIBLE_CORES="0-0" \
--env CHIP_TYPE="inf1" \
-p ${port_num}:8080 --device=/dev/neuron0 ${registry}/ bert-inf-fastapiNeuronCore 5に展開するための実行コマンドは次のようになります:
docker run -t -d \
--name $ bert-inf-fastapi-nc-5 \
--env NEURON_RT_VISIBLE_CORES="5-5" \
--env CHIP_TYPE="inf1" \
-p ${port_num}:8080 --device=/dev/neuron0 ${registry}/ bert-inf-fastapiコンテナが展開された後、並列スレッドでAPIを呼び出すためにrun_apis.pyスクリプトを使用します。このコードは、各NeuronCoreに1つずつ展開された6つのモデルを呼び出すように設定されていますが、簡単に異なる設定に変更することもできます。クライアント側からは以下のようにしてAPIを呼び出します:
import requests
url_template = http://localhost:%i/predictions_neuron_core_%i/model_%i
# NeuronCore 0
response = requests.get(url_template % (8081,0,0))
# NeuronCore 5
response = requests.get(url_template % (8086,5,0))NeuronCoreのモニタリング
モデルサーバーが展開された後、NeuronCoreの利用状況を監視するために、neuron-topを使用して各NeuronCoreの利用率をリアルタイムで観察することができます。neuron-topはNeuron SDKのCLIツールであり、NeuronCore、vCPU、メモリの利用状況などの情報を提供します。別のターミナルで、次のコマンドを入力します:
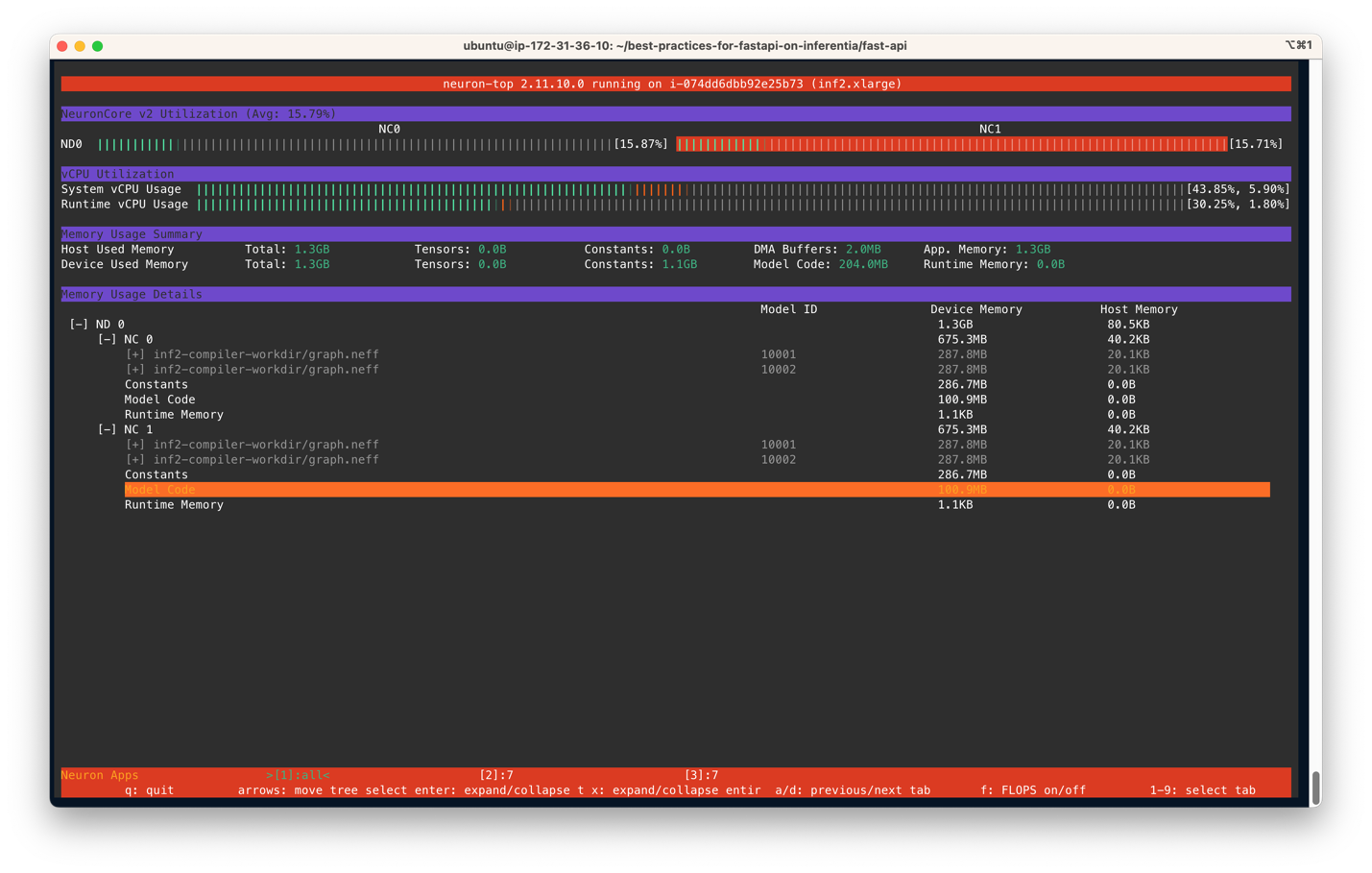
neuron-top出力は次の図と似ているはずです。このシナリオでは、Inf2.xlargeインスタンス上のサーバーごとに2つのNeuronCoreおよび2つのモデルを使用するように指定しています。以下のスクリーンショットでは、サイズが287.8MBのモデルが2つのNeuronCoreにロードされていることが分かります。4つのロードされたモデルの合計デバイスメモリ使用量は1.3 GBです。矢印キーを使用して異なるデバイス上のNeuronCore間を移動できます。
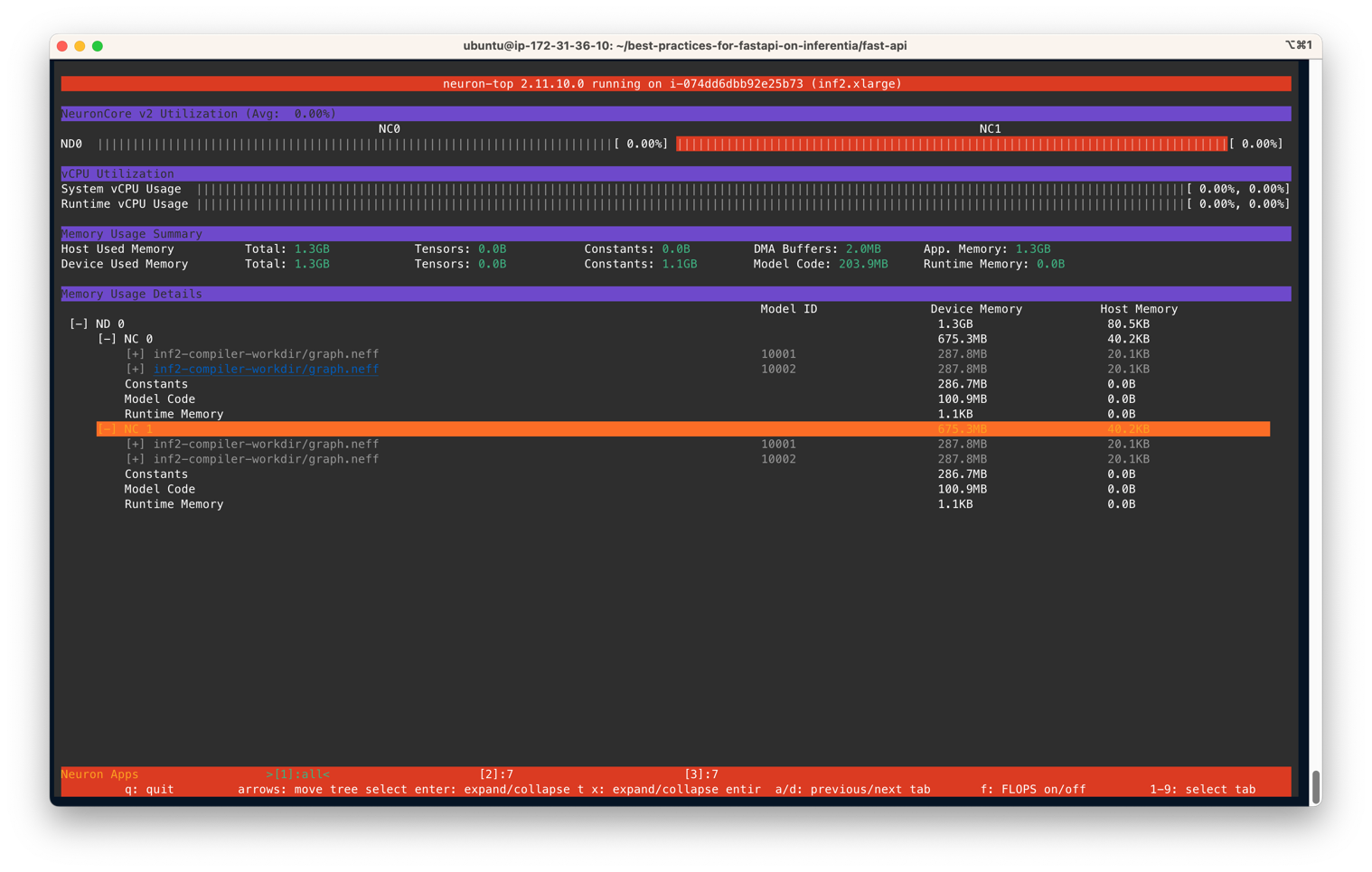
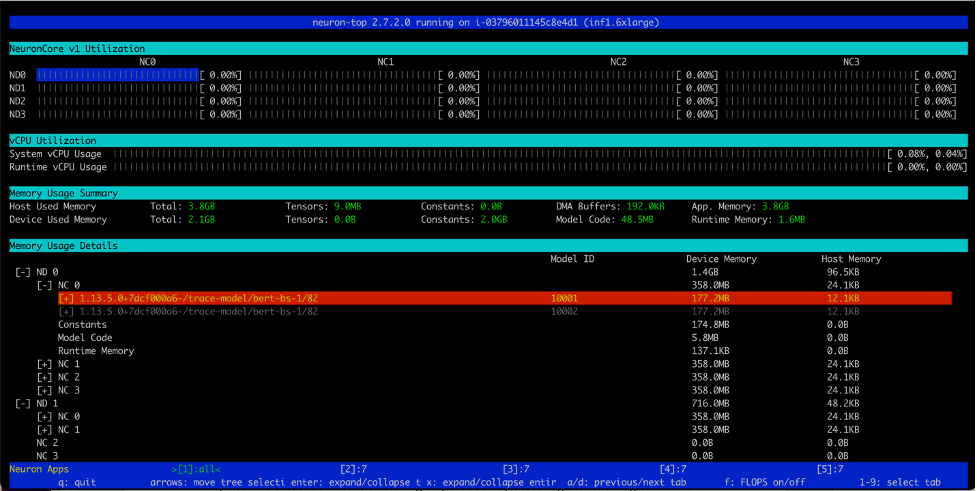
同様に、Inf1.16xlargeインスタンスタイプでは、合計12モデル(6つのコアごとに2つのモデル)がロードされます。合計で2.1GBのメモリを消費し、各モデルのサイズは177.2MBです。
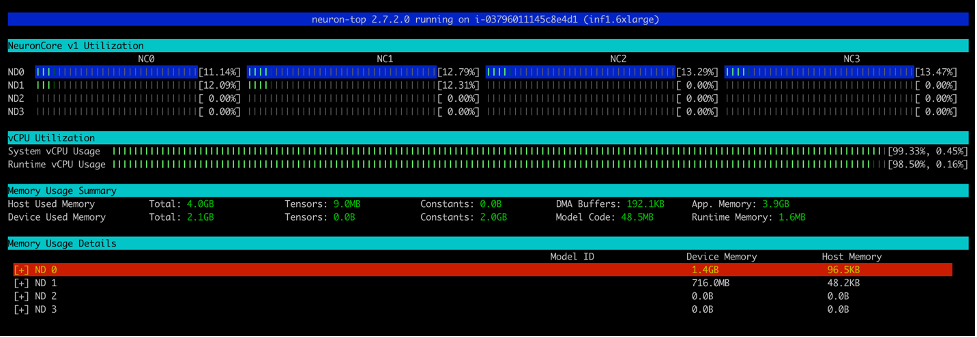
run_apis.pyスクリプトを実行すると、各NeuronCoreの利用率の割合(以下のスクリーンショット参照)が表示されます。また、システムvCPUの使用率とランタイムvCPUの使用率も表示されます。
以下のスクリーンショットは、Inf2インスタンスのコア利用率を示しています。
同様に、このスクリーンショットはinf1.6xlargeインスタンスタイプのコア利用率を示しています。
クリーンアップ
作成したすべてのDockerコンテナをクリーンアップするには、cleanup.shスクリプトを提供しています。このスクリプトはすべての実行中および停止中のコンテナを削除します。ただし、一部のコンテナを実行したままにしておきたい場合は、このスクリプトを使用しないでください。
結論
本番ワークロードでは、高スループット、低レイテンシ、およびコストの要件がしばしばあります。アクセラレータを効率的に活用しない非効率なアーキテクチャは、不必要に高い生産コストを引き起こす可能性があります。この記事では、FastAPIを使用してNeuronCoresを最適に活用し、最小のレイテンシでスループットを最大化する方法を示しました。GitHubリポジトリに手順を公開しています。このソリューションアーキテクチャを使用すると、各NeuronCoreに複数のモデルをデプロイし、異なるNeuronCore上で複数のモデルを並行して操作することができ、パフォーマンスを損なうことなく展開できます。Amazon Elastic Kubernetes Service(Amazon EKS)などのサービスを使用してモデルをスケール展開する方法の詳細については、「1時間あたり50ドル未満でAWS Inferentiaを使用してAmazon EKS上で3,000個のディープラーニングモデルを提供する」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「他のAIを教えるAI」
- 「Googleによる無料の生成AIコース」
- 「AIの責任ある適用を促進するための社会的なコンテキスト知識の活用」
- フェイブルスタジオは、TV番組の完全に新しいエピソードを書き、制作し、監督し、アニメーション化し、さらには声を担当できるAIプラットフォームであるSHOW-1をリリースしました
- 「Appleの次の動き:『Apple GPT』の開発と最先端の生成型AIツールの開発によるOpenAIへの挑戦」
- 生産性のパラノイアを打破する:Microsoft 365コパイロットには賛成ですか?
- 「OpenAI Pythonライブラリ&Pythonで実践例を交えてChatGPTができる5つの注目すべきこと!」






