より速いデータ検索のためのSQLクエリの最適化方法
Optimization methods for SQL queries for faster data search.

SQL(Structured Query Language)は、おそらくご存じのように、データベースからデータを収集するのに役立ちます。
それはそのために特別に設計されています。つまり、行と列で動作し、SQLクエリを使用してデータベースからデータを操作できます。
SQLクエリとは?
SQLクエリは、データベースから情報を収集するためにデータベースに与える一連の命令です。
これらのクエリを使用することで、データベースからデータを収集して操作できます。
これらのクエリを使用することで、レポートの作成、データ分析などができます。
これらのクエリの形式や長さにより、特に大規模なデータテーブルを扱う場合、実行時間がかかることがあります。
SQLクエリの最適化がなぜ必要なのか?
SQLクエリの最適化の目的は、リソースを効率的に使用することです。つまり、実行時間を短縮し、コストを削減し、パフォーマンスを向上させることです。これは、開発者やデータアナリストにとって重要なスキルです。データベースから正しいデータを取得することだけが重要ではありません。それをどのように効率的に行うかも重要です。
常に自分自身に「クエリを書くためにより良い方法はあるか?」と問いかける必要があります。
この理由について詳しく説明しましょう。
リソースの効率化:最適化されていないSQLクエリは、CPUやメモリなどのシステムリソースを過剰に消費する可能性があります。これは、全体的なシステムパフォーマンスの低下につながる可能性があります。SQLクエリの最適化により、これらのリソースが効率的に使用されることが保証されます。これにより、パフォーマンスとスケーラビリティが向上します。
実行時間の短縮:クエリが遅い場合、ユーザーエクスペリエンスに悪影響を与えます。また、アプリケーションが実行されている場合は、アプリケーションのパフォーマンスにも悪影響を与えます。クエリの最適化により、実行時間を短縮し、より速いレスポンスタイムとより良いユーザーエクスペリエンスを提供できます。
コスト削減:最適化されたクエリにより、データベースシステムをサポートするために必要なハードウェアやインフラストラクチャを削減できます。これにより、ハードウェア、エネルギー、およびメンテナンスコストを削減できます。
正しい場合でも、コード構造が改善できる「SQLクエリを書くためのベストプラクティス」をチェックしてください。
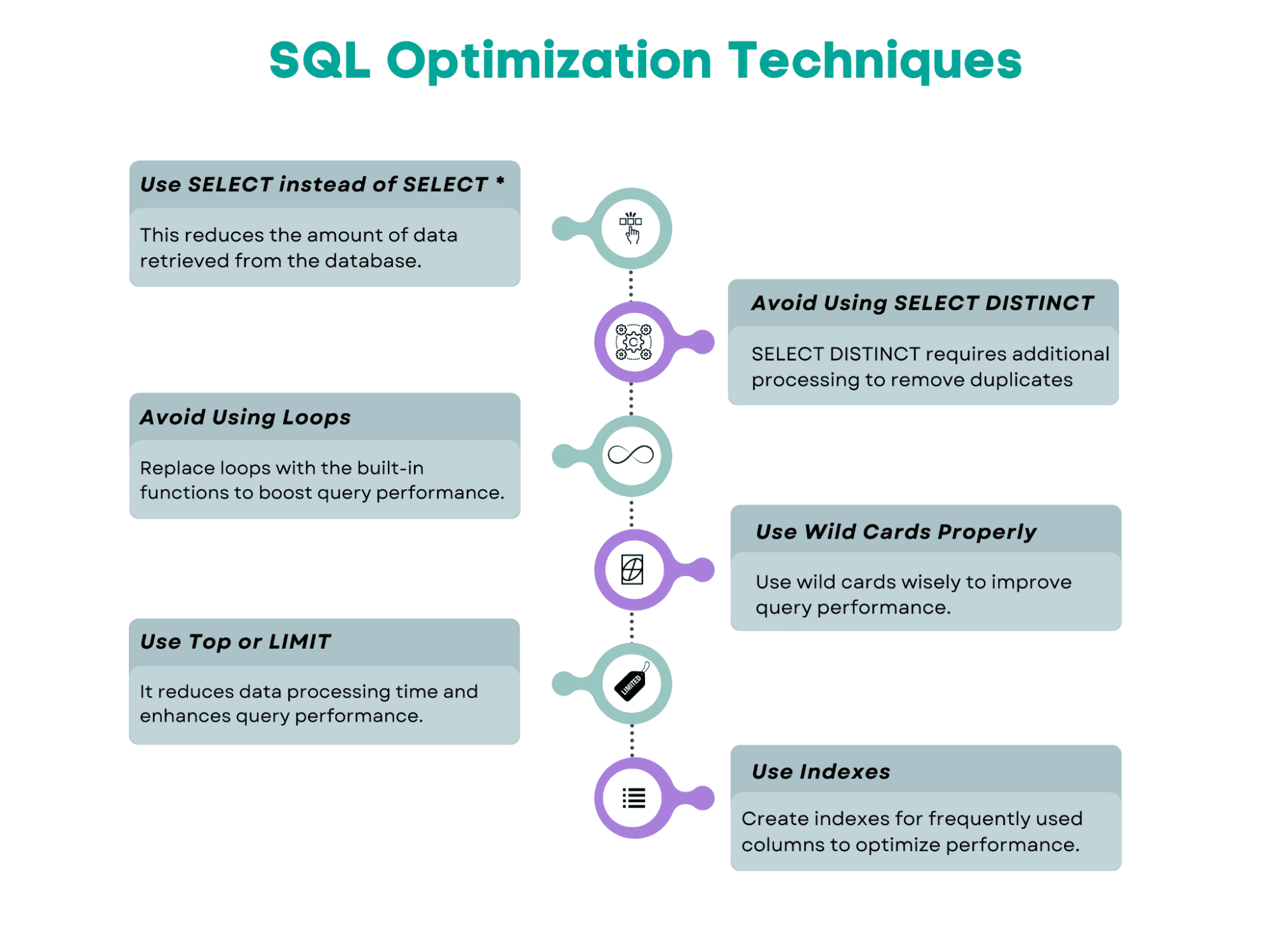
SQLクエリの最適化技術
ここで、この記事でカバーするSQLクエリの最適化技術の概要を示します。
ここに、SQLクエリを最適化する場合に推奨される手順を示すフローチャートがあります。私たちは、この例でも同じアプローチを取ります。最適化ツールもクエリのパフォーマンスを向上させるのに役立つことに注意してください。では、SELECTというよく知られたSQLコマンドからこれらの技術を探ってみましょう。 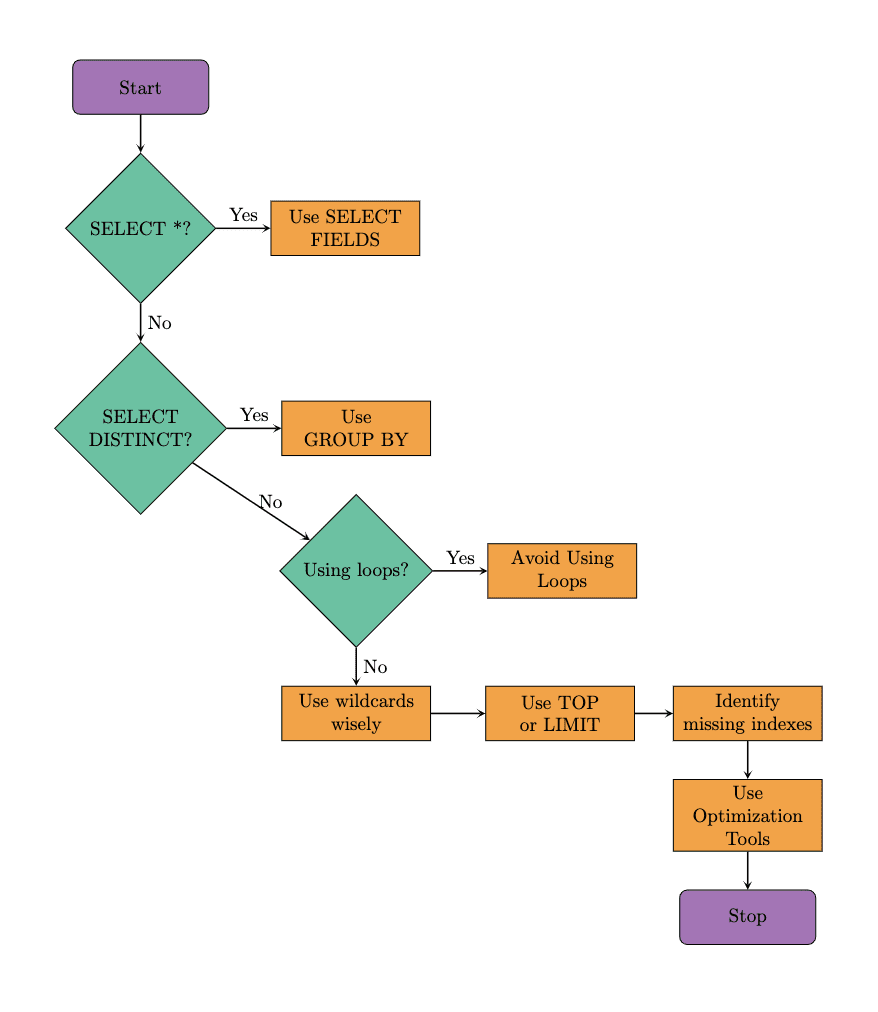
SELECT * ではなく、指定されたフィールドでSELECTを使用する
SELECT * を使用すると、テーブルのすべての行とすべての列が返されます。本当に必要なのか自問してください。
SELECTの後に特定のフィールドを使用するようにして、データベース全体をスキャンする代わりに、必要なフィールドを使用します。
この例では、SELECT * を特定の列名に置き換えます。これにより、取得されるデータの量が減少します。
その結果、データベースは要求された列を取得して提供する必要があるため、すべてのテーブルの列ではなく、要求された列だけを提供する必要があります。これにより、データベースに対するI/O負荷が軽減され、特に多数の列または多数のデータ行を持つテーブルの場合に役立ちます。
最適化前のコードは以下の通りです。
SELECT * FROM customer;ここに出力結果があります。
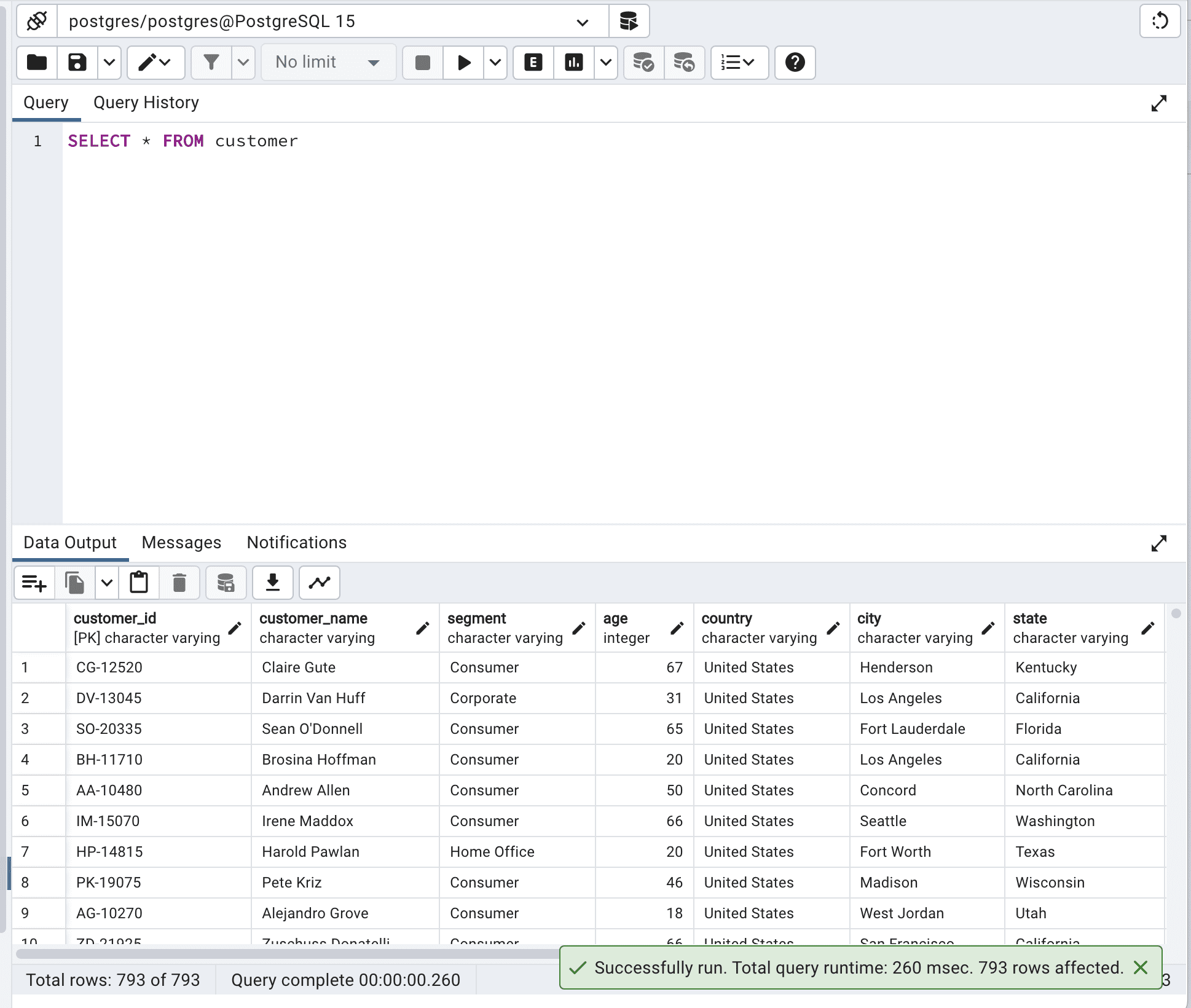
クエリの合計実行時間は260ミリ秒です。これを改善できます。
そのために、すべて選択するのではなく、必要な列だけを3つ選択します。
プロジェクトのニーズに応じて必要な列を選択できます。
ここにコードがあります。
SELECT customer_id,
age,
country
FROM customer;そしてこれが出力結果です。
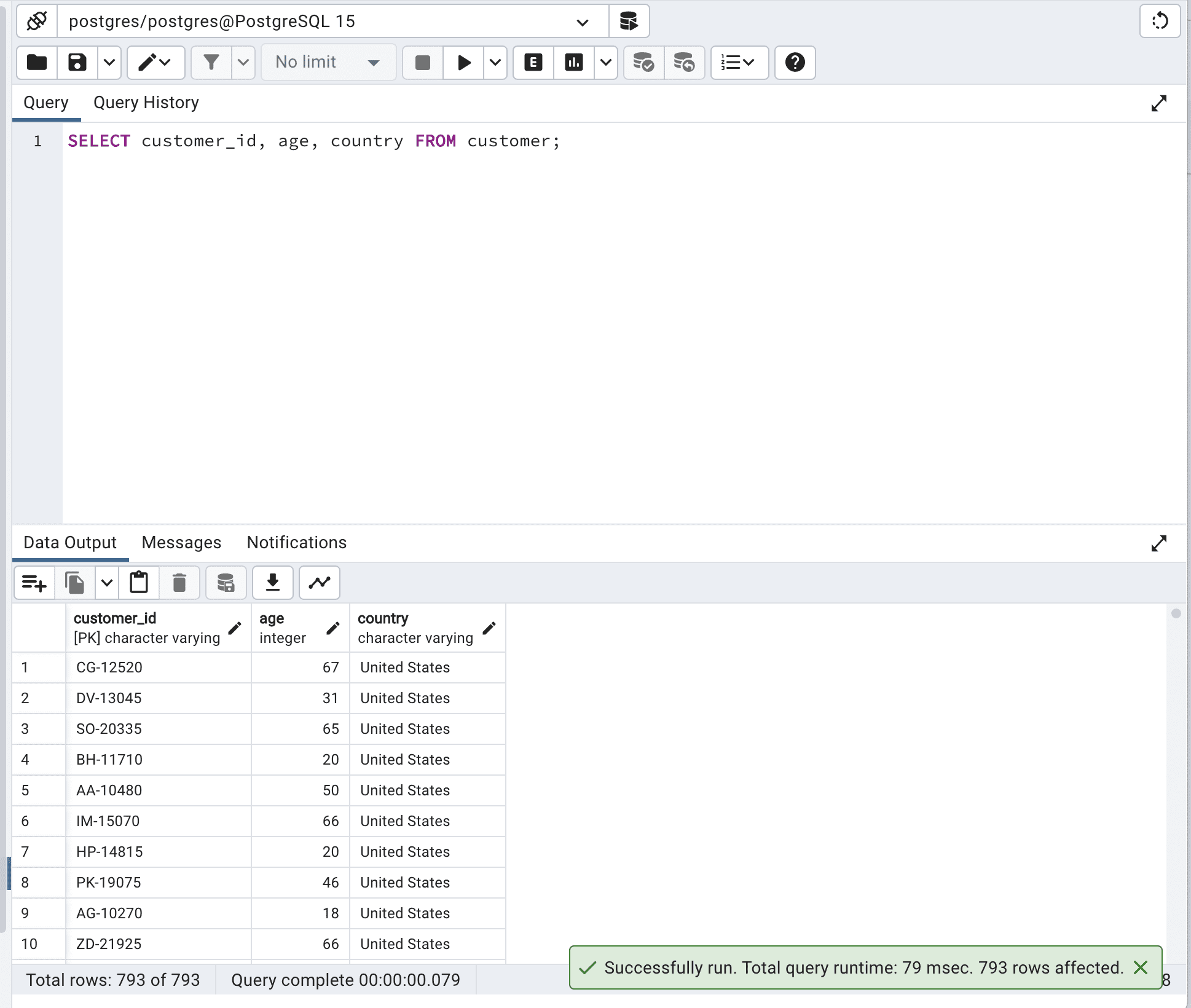
フィールドを定義することで、データベースが持つすべてのデータをスキャンすることなく実行時間を260ミリ秒から79ミリ秒に短縮できることがわかります。
何百万行、何十億行の場合、何百列の場合でも、その違いがどれだけ大きくなるか想像してください。
SELECT DISTINCT の使用を避ける
SELECT DISTINCT は、指定された列の一意の値を返すために使用されます。これを行うために、データベースエンジンはテーブル全体をスキャンし、重複する値を削除する必要があります。そのため、GROUP BY のような代替手段を使用することで、処理するデータの数を減らすことができ、パフォーマンスが向上する場合があります。
以下がコードです。
SELECT DISTINCT segment
FROM customer;以下が出力結果です。
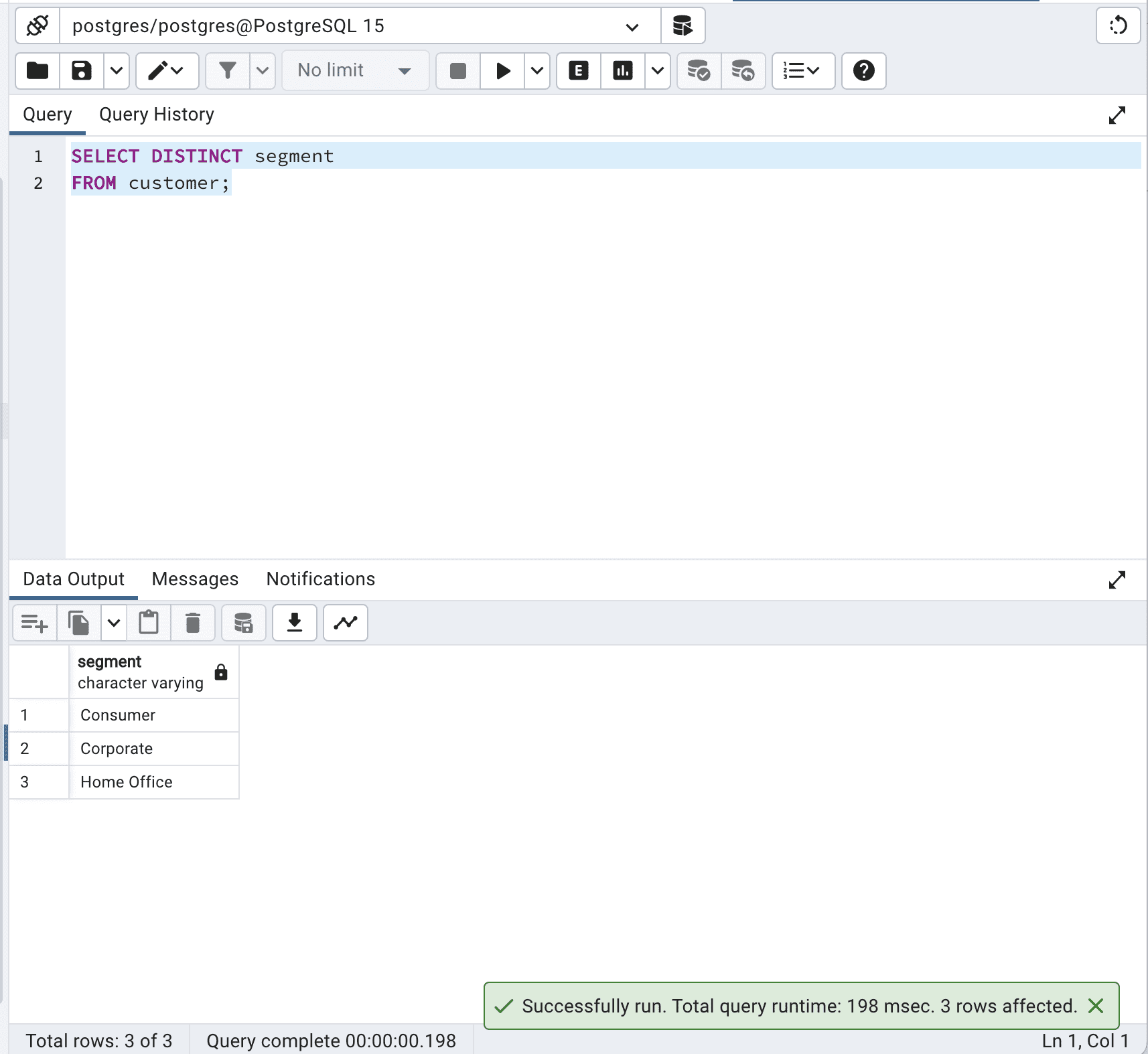
私たちのコードは、customerテーブルからsegment列の一意の値を取得します。データベースエンジンは、テーブルのすべてのレコードを処理し、重複する値を特定して一意の値を返す必要があります。大きなテーブルの場合、これは時間とリソースの面でコストがかかることがあります。
代替バージョンでは、以下のクエリがGROUP BY句を使用してsegment列の一意の値を取得します。GROUP BY句は、指定された列に基づいてレコードをグループ化し、各グループにつき1つのレコードを返します。
以下がコードです。
SELECT segment
FROM customer
GROUP BY segment;以下が出力結果です。
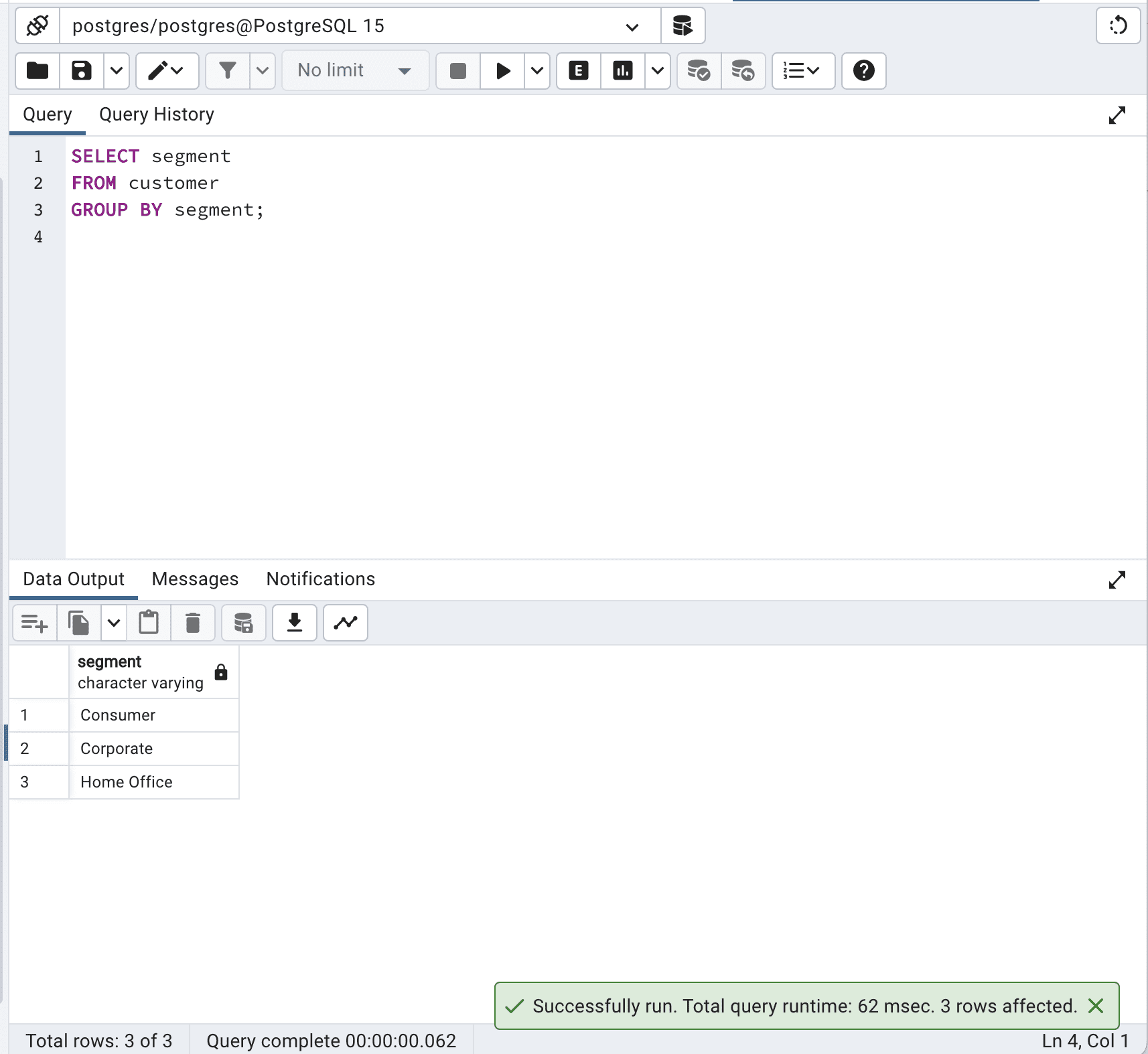
この場合、GROUP BY句がレコードをsegment列で効果的にグループ化し、SELECT DISTINCTクエリと同じ出力結果になります。
SELECT DISTINCT を避け、代わりにGROUP BYを使用することで、SQLクエリを最適化し、合計クエリ時間を198ミリ秒から62ミリ秒に短縮することができます。これは3倍以上高速です。
ループを使用しない
ループを使用すると、データベースがレコードを1つずつ処理するため、クエリの実行が遅くなる場合があります。
可能な限り、データベースエンジンの最適化機能を活用し、組み込みの操作やSQL関数を使用することで、データの処理を効率的に行うことができます。
ループを使用するカスタム関数を定義しましょう。
CREATE OR REPLACE FUNCTION sum_ages_with_loop() RETURNS TABLE (country_name TEXT, sum_age INTEGER) AS $$
DECLARE
country_record RECORD;
age_sum INTEGER;
BEGIN
FOR country_record IN SELECT DISTINCT country FROM customer WHERE segment = 'Corporate'
LOOP
SELECT SUM(age) INTO age_sum FROM customer WHERE country = country_record.country AND segment = 'Corporate';
country_name := country_record.country;
sum_age := age_sum;
RETURN NEXT;
END LOOP;
END;
$$ LANGUAGE plpgsql;上記のコードは、顧客セグメントが「Corporate」である国ごとの年齢の合計を計算するために、ループベースのアプローチを使用しています。
最初に、一意の国のリストを取得し、その後、ループを使用して各国を反復処理し、その国の顧客の年齢の合計を計算します。この方法は、データを行単位で処理するため、遅くて効率的ではありません。
ここで、この関数を実行しましょう。
SELECT *
FROM sum_ages_with_loop()以下が出力結果です。
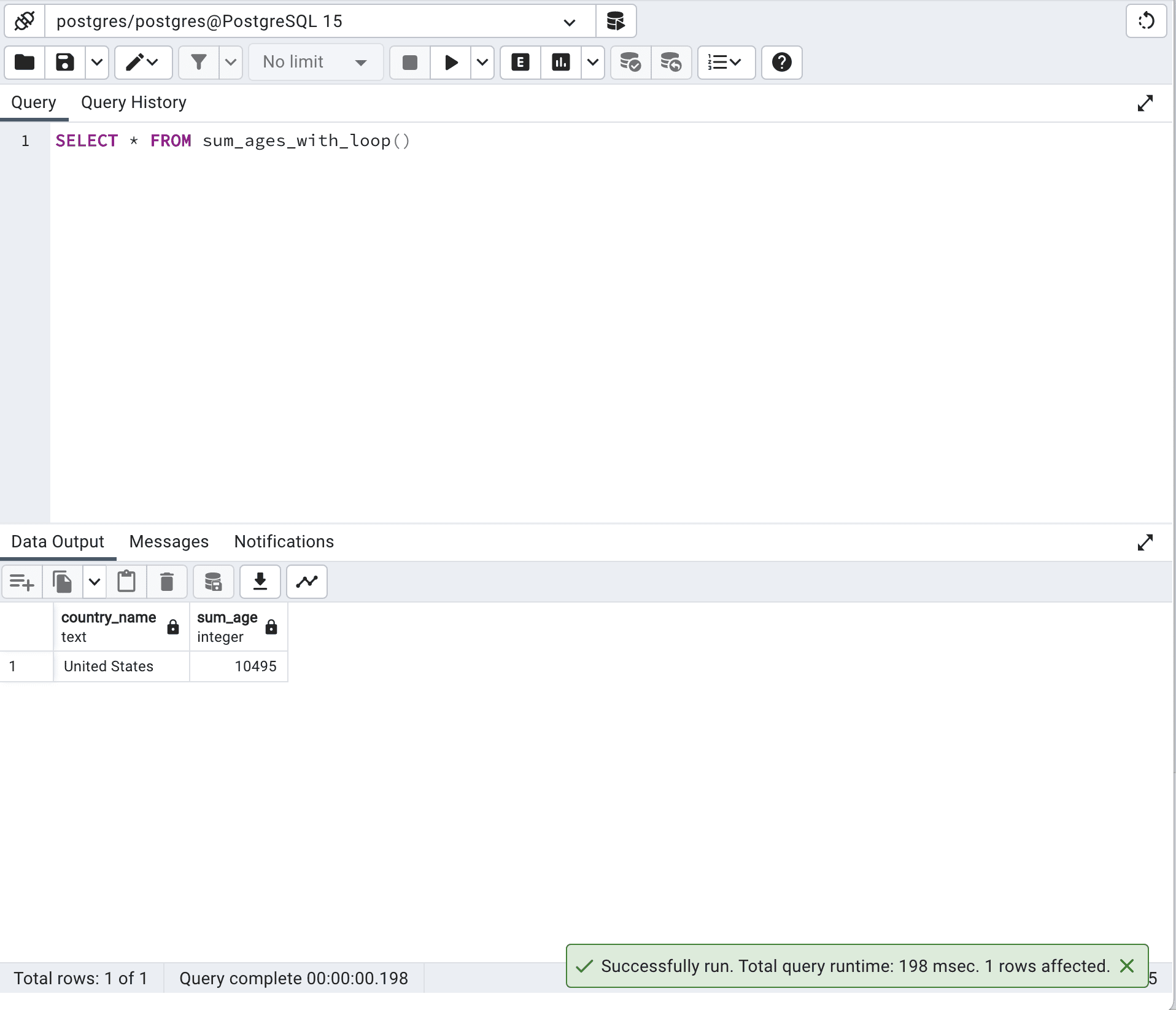
このアプローチでは、実行時間が198ミリ秒かかります。
最適化されたSQLコードを見てみましょう。
SELECT country,
SUM(age) AS sum_age
FROM customer
WHERE segment = 'Corporate'
GROUP BY country;以下が出力結果です。
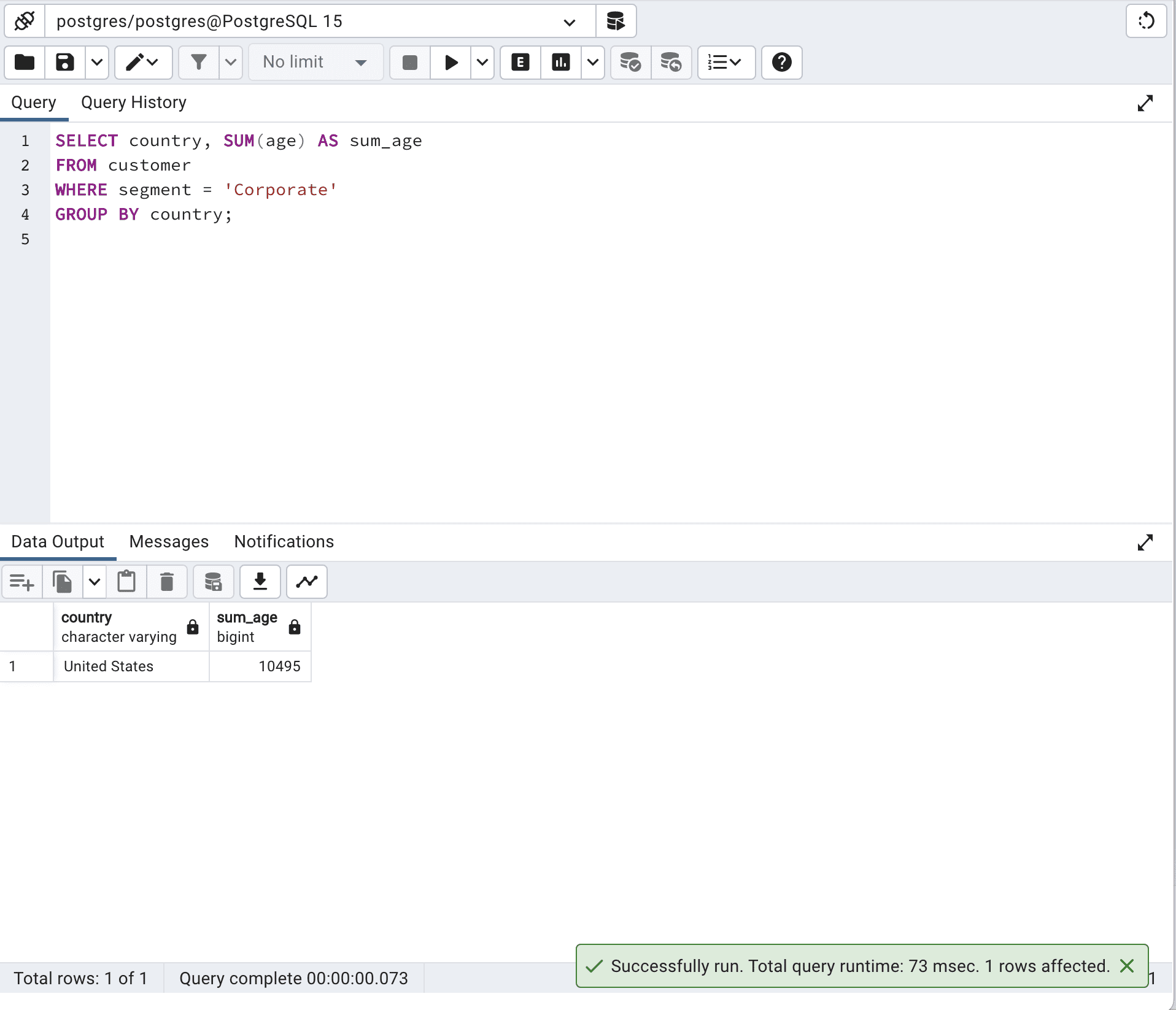
一般的に、データベースエンジンの最適化機能を活用する単一のSQLクエリを使用した最適化バージョンの方が、優れたパフォーマンスを発揮します。
同じ結果を得るために、最初のコードではPL/pgSQL関数内でループを使用することがありますが、これは単一のSQLクエリで行うよりも遅く、効果的ではなく、コードの行数が多くなるように強制されます。
ワイルドカードを適切に使用する
ワイルドカードの適切な使用は、特に文字列やパターンの一致に関してSQLクエリの最適化にとって重要です。
ワイルドカードは、SQLクエリで特定のパターンを検索するために使用される特殊文字です。
SQLで最も一般的なワイルドカードは「%」と「_」であり、「%」は任意の文字列のシーケンスを表し、「_」は1つの文字を表します。
適切にワイルドカードを使用することは重要です。不適切な使用は、特に大規模なデータベースではパフォーマンスの問題を引き起こす可能性があります。
ただし、効率的に使用することで、文字列一致とパターン一致のクエリのパフォーマンスを大幅に向上させることができます。
さて、以下は例です。
このクエリでは、RIGHT()関数を使用してcustomer_name列の最後の3文字を抽出し、それが ‘son’と等しいかどうかを確認しています。
SELECT customer_name
FROM customer
WHERE RIGHT(customer_name, 3) = 'son';以下は出力です。
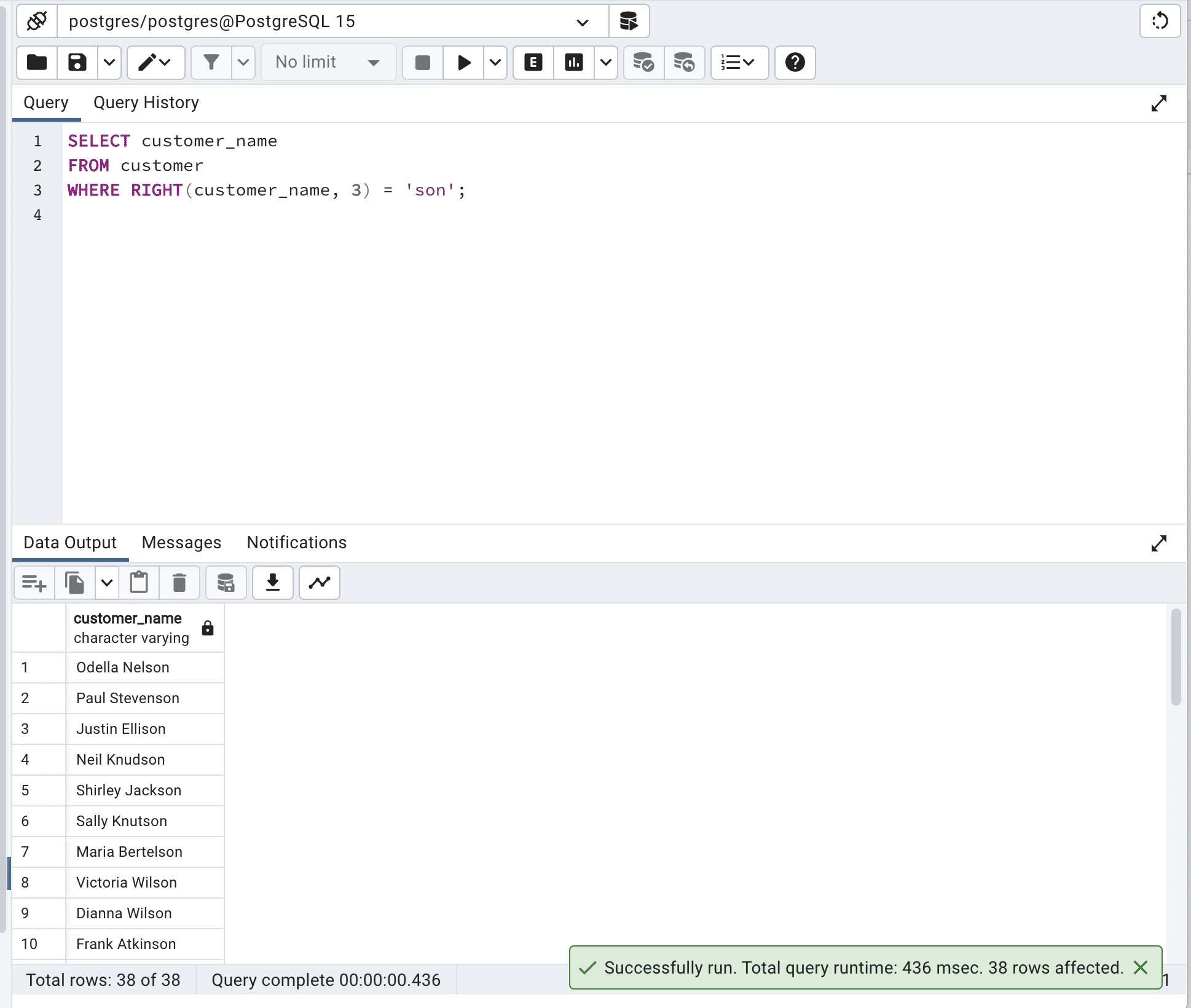
このクエリは、望ましい結果を得ますが、RIGHT()関数をテーブル内のすべての行に適用する必要があるため、効率的ではありません。
ワイルドカードを使用してコードを最適化しましょう。
SELECT customer_name
FROM customer
WHERE customer_name LIKE '%son';以下は出力です。
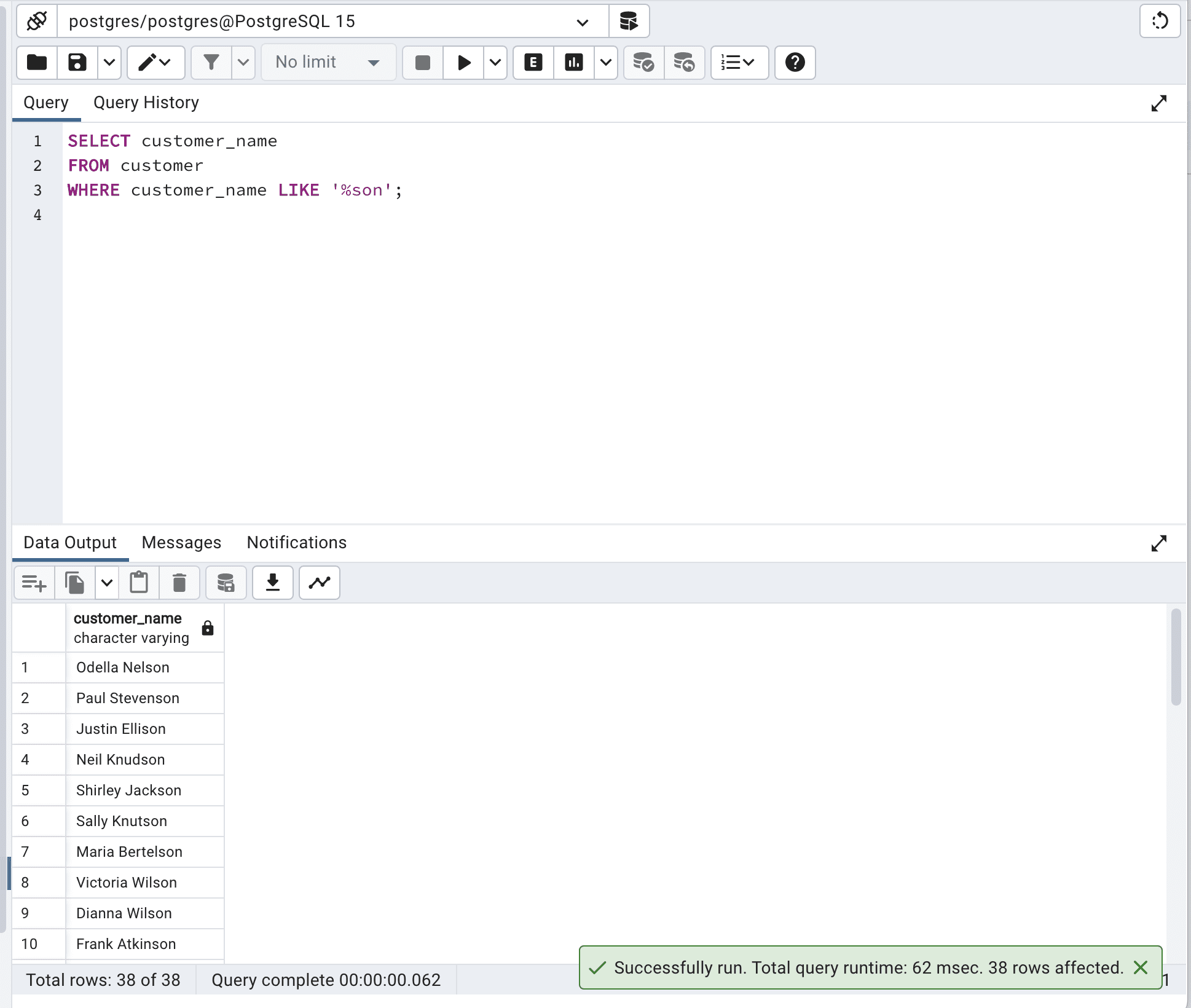
この最適化されたSQLクエリは、LIKE演算子とワイルドカード「%」を使用して、customer_name列が ‘son’で終わるレコードを検索します。
このアプローチは、データベースエンジンのパターンマッチング機能を活用し、利用可能な場合はインデックスをより効果的に使用できるため、より効率的です。
そして、合計クエリ時間が436ミリ秒から62ミリ秒に減少していることがわかります。これは、ほぼ7倍速くなっています。
TopまたはLIMITを使用してサンプル結果の数を制限する
大きなテーブルを扱う場合、SQLクエリの最適化において、サンプル結果の数を制限するためにTOPまたはLIMITを使用することが重要です。
これらの句は、すべてのレコードではなく、指定された数のレコードのみをテーブルから取得できるため、パフォーマンスに対して有益です。
今回は、customerテーブルからすべての情報を取得します。
SELECT *
FROM customer以下は出力です。
大きなテーブルを扱う場合、この操作はI/Oとネットワークレイテンシを増加させ、SQLクエリのパフォーマンスを低下させる可能性があります。
出力を制限することで、ネットワークレイテンシやメモリ使用量を減らし、レスポンス時間を改善することができます。大きなテーブルを扱う場合、特に効果があります。この例では、SQLクエリの最適化後、合計クエリ実行時間が260ミリ秒から89ミリ秒に減少しました。
クエリは、ほぼ3倍高速化されました。
インデックスを使用する
今回は、WHERE、JOIN、ORDER BY句で使用される列に適切なインデックスを識別して作成して、クエリのパフォーマンスを改善します。
頻繁にアクセスされる列にインデックスを付けることで、データベースはより迅速にデータを取得できます。
今回は、最初に次のクエリを実行します。
SELECT customer_id,
customer_name
FROM customer
WHERE segment = 'Corporate';以下は出力です。 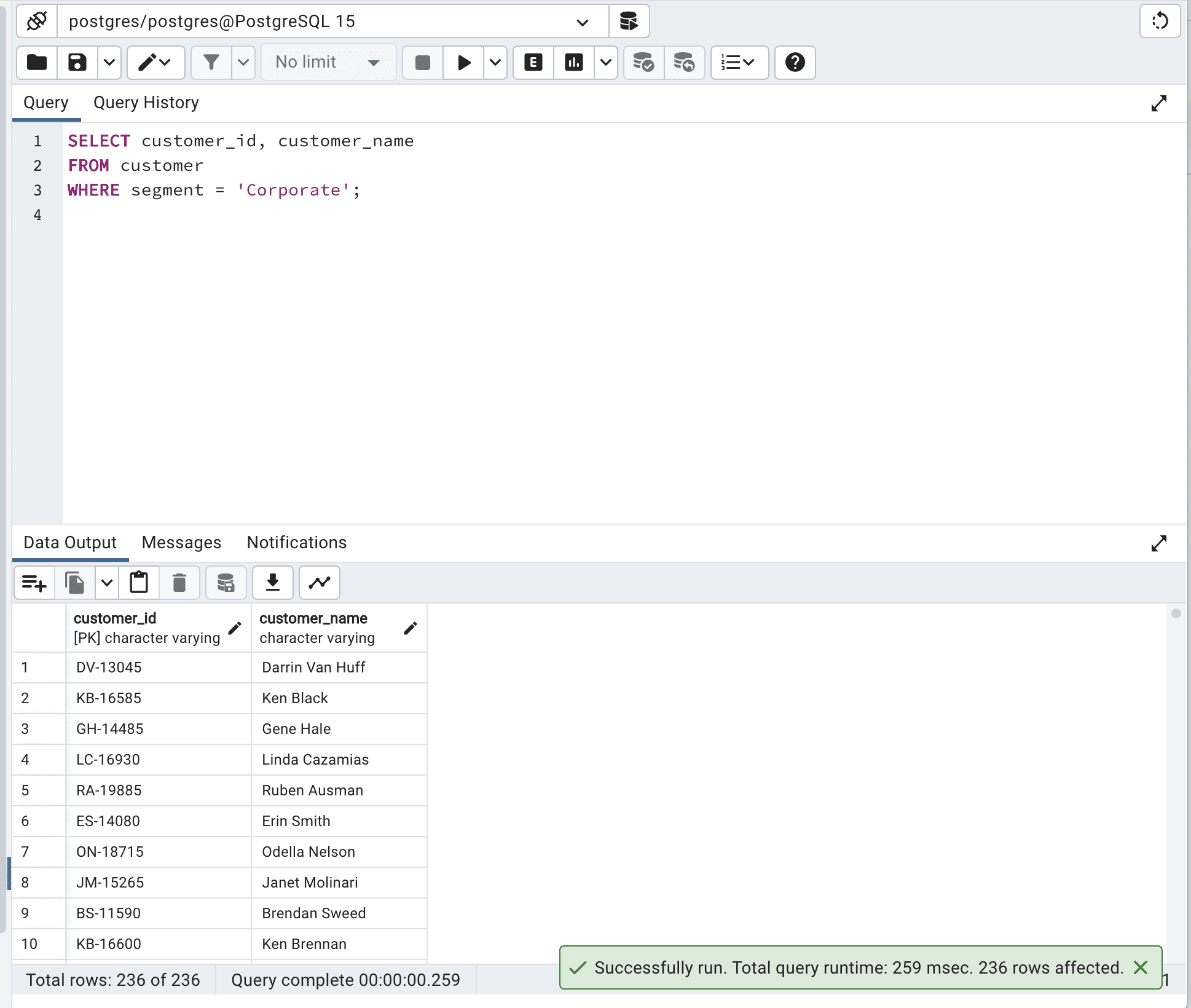
クエリの実行時間は259ミリ秒です。
それを改善するために、インデックスを作成してみましょう。
CREATE INDEX idx_segment ON customer (segment);素晴らしいですね、今度はコードを再実行しましょう。
SELECT customer_id,
customer_name
FROM customer WITH (INDEX(idx_segment))
WHERE segment = 'Corporate';ここに出力結果があります。
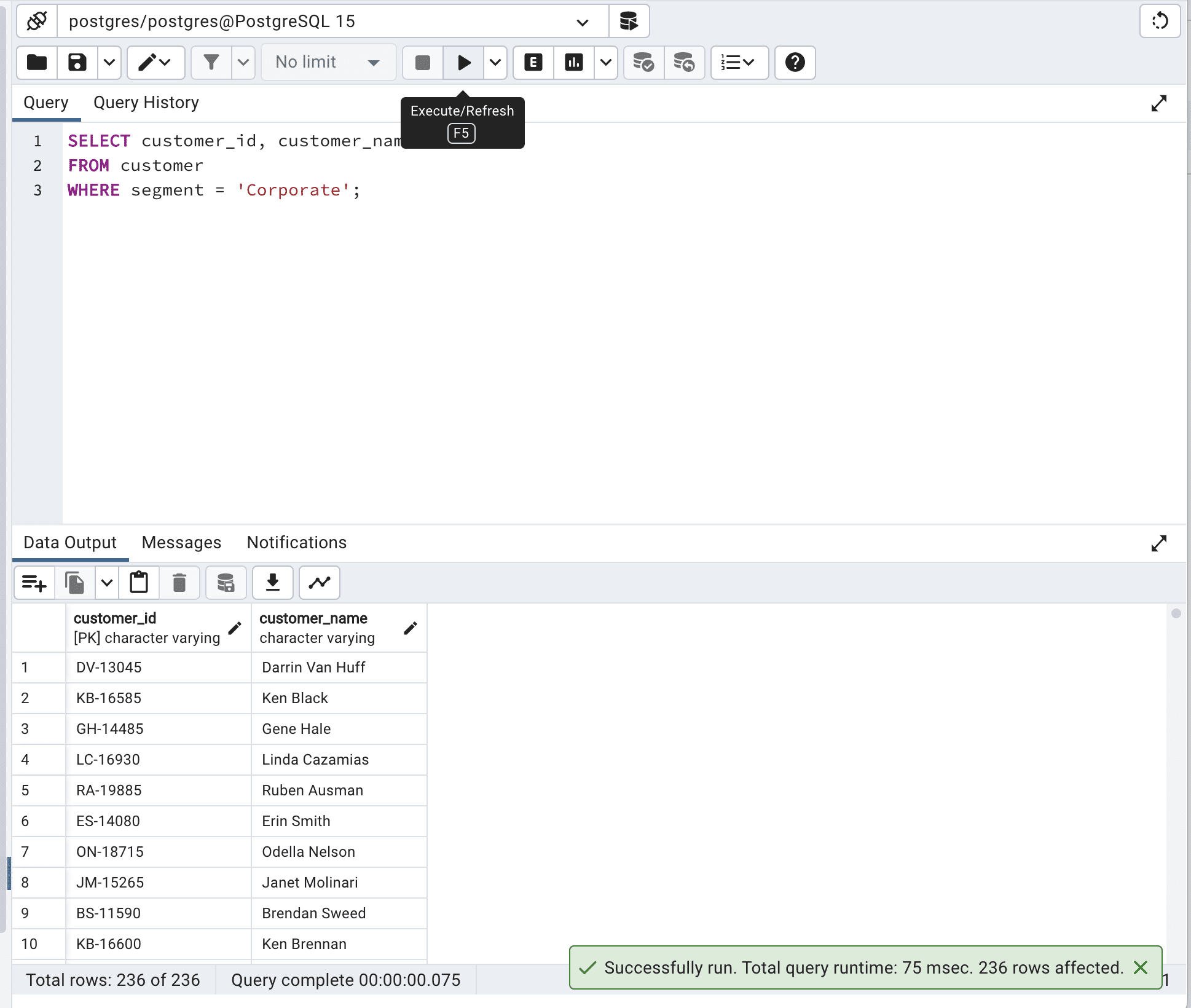
INDEX()のidx_segmentを使用することで、データベースエンジンは、セグメント列に基づいて顧客テーブルを効率的に検索でき、クエリの実行が高速化されました。クエリの合計時間を259ミリ秒から75ミリ秒に減少させました。
ボーナスセクション:SQLクエリ最適化ツールの使用
長いコードや複雑なクエリの複雑さにより、クエリ最適化ツールの使用を検討する必要があるかもしれません。
これらのツールを使用すると、クエリの実行計画を分析し、インデックスの不足を特定し、クエリを最適化するための代替クエリ構造を提案できます。人気のあるクエリ最適化ツールには、次のものがあります。
- SolarWinds Database Performance Analyzer:このツールは、データベースのパフォーマンスを監視して改善するのに役立ちます。クエリの問題とその実行方法を示します。SQL Server、Oracle、MySQLなど、さまざまなデータベースシステムで動作します。
ここで見つけることができます。
- SQL Query Tuner for SQL Diagnostic Manager:このツールには、パフォーマンスのヒント、インデックスのチェック、クエリの実行方法の表示など、クエリをより良く機能させるための高度な機能があります。問題を見つけて修正することで、SQLクエリをより良くするのに役立ちます。
- SQL Server Management Studio (SSMS):SSMSには、アクティビティモニター、実行計画解析、インデックスチューニングウィザードなど、パフォーマンスのチェックとクエリの改善のための組み込みツールがあります。
- EverSQL:EverSQLは、データベース構造とクエリの実行方法を見て、自動的にクエリを改善するオンラインツールです。アドバイスを与え、SQLクエリを再書き込みして、より高速に機能させます。
SQLクエリ最適化ツールとリソースを使用することは、クエリを改善するために不可欠です。これらのツールを使用すると、クエリの動作方法を学び、問題を見つけ、データをより速く取得し、アプリケーションを改善できます。
複雑なSQLクエリを簡素化するには、「複雑なSQLクエリを簡素化する方法」を参照してください。
最終的なメモ
上記のSQLクエリを最適化することで行った変更は、そのスケール(ms)のために些細なものに見えるかもしれません。しかし、扱うデータ量が増えるにつれて、これらのミリ秒は秒、分、そして可能性があれば時間にまで増加します。その時、これらのSQLクエリ最適化技術が非常に重要であることに気づくでしょう。
さらに知りたい場合は、「トップ30のSQLクエリインタビューの質問」を参照してください。これにより、学習中にインタビューの準備をする人々に役立ちます。
読んでいただきありがとうございます!Nate Rosidiは、データサイエンティストであり、プロダクト戦略家です。彼は、アナリティクスを教える非常勤講師であり、トップ企業からの実際のインタビューの質問を用いてデータサイエンティストの面接の準備を支援するプラットフォームであるStrataScratchの創設者でもあります。Twitter:StrataScratchまたはLinkedInで彼に連絡してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
