「OpenAI(Python)APIを解説する」
OpenAI API 解説
完全な初心者向けのサンプルコード付きの入門
これは、Large Language Models(LLM)を実践的に使用するためのシリーズの2番目の記事です。ここでは、OpenAI APIの初心者向けの入門を紹介します。これにより、ChatGPTのような制約のあるチャットインターフェースを超えて、独自のユースケースにLLMをより効果的に活用することができます。以下にPythonのサンプルコードとGitHubリポジトリの提供があります。
目次:
- APIとは何か?
- OpenAIの(Python)API
- 始めるための手順(4つ)
- サンプルコード
このシリーズの最初の記事では、Prompt EngineeringをLLMの実践的な使用方法として説明しました。これを行うための最も簡単(かつ人気のある)方法は、ChatGPTなどのツールを使用することです。これにより、LLMとの直感的で無料かつコード不要なやり取りが可能になります。
LLMの実践的な入門
実践的なLLMの使用レベル
towardsdatascience.com
ただし、この使いやすさにはコストがかかります。つまり、チャットUIは制限があり、顧客サポートボットの作成、顧客レビューのリアルタイム感情分析などの多くの実践的なユースケースに適用しづらいということです。
これらの場合、Prompt Engineeringをさらに進めてLLMとプログラム的にやり取りすることができます。その一つの方法がAPIを介する方法です。
1) APIとは何か?
アプリケーションプログラミングインターフェース(API)は、リモートアプリケーションとプログラム的にやり取りすることができます。これは技術的で複雑に聞こえるかもしれませんが、アイデアは非常にシンプルです。次のアナロジーを考えてみてください。
思い出の夏、エルサルバドルで食べたププサへの強烈な渇望があります。残念ながら、自宅に戻っており、良いエルサルバドル料理を見つける方法がわかりません。しかし、幸運なことに、レストランのことをすべて知っているスーパーフーディーな友達がいます。
それで、友達にテキストを送ります。
「町中でププサのお店はありますか?」
すると、数分後に返信が返ってきます。
「はい!エルサルバドルのフレーバーオブエルサルバドルが最高のププサを提供しています!」
APIとの関係は、この例と似ています。リモートアプリケーションにリクエストを送信します。つまり、スーパーフーディーな友達にテキストを送ります。そして、リモートアプリケーションはレスポンスを返します。つまり、友達からの返信テキストです。

APIと上記のアナロジーの違いは、リクエストを自分の電話のテキストアプリで送信する代わりに、お気に入りのプログラミング言語(Python、JavaScript、Ruby、Javaなど)を使用することです。これは、外部情報が必要なソフトウェアを開発している場合に便利です。なぜなら、情報の取得を自動化できるからです。
2) OpenAIの(Python)API
APIを使用してLarge Language Modelsとやり取りすることができます。人気のあるものの一つがOpenAIのAPIで、ChatGPTのWebインターフェースにプロンプトを入力する代わりに、Pythonを使用してOpenAIに送信および受信することができます。
これにより、誰でも最新のLLMs(および他のMLモデル)にアクセスできるようになりますが、それらを実行するために必要な計算リソースを用意する必要はありません。もちろん、デメリットとして、OpenAIはこれを慈善事業として行っていません。各APIコールには費用がかかりますが、それについては後ほど説明します。
APIの注目すべき機能(ChatGPTでは利用できないもの)は以下の通りです。
- カスタマイズ可能なシステムメッセージ(ChatGPTの場合、これは「私はChatGPTです。OpenAIによって訓練された大規模な言語モデルであり、GPT-3.5アーキテクチャに基づいています。私の知識は2021年9月までの情報に基づいています。今日の日付は2023年7月13日です。」などに設定されます)
- 最大応答長、応答数、および応答の「ランダム性」(温度)などの入力パラメータの調整
- プロンプトに画像やその他のファイルタイプを含める
- ダウンストリームタスク用の役立つ単語埋め込みを抽出する
- 転写や翻訳のための入力オーディオ
- モデルの微調整機能
OpenAI APIにはいくつかのモデルがあり、選ぶべき最適なモデルは使用ケースによります。現在利用可能なモデルのリストは以下の通りです[1]。
![List of available models via the OpenAI API as of Jul 2023. Image by author. [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*DDldra_REDf4A_bBdW0McA.png)
注意:上記の各項目には、サイズとコストが異なる複数のモデルが添付されています。最新の情報についてはドキュメントを確認してください。
価格とトークン
OpenAI APIは、開発者に最新のSOTA MLモデルへの簡単なアクセスを提供しますが、明らかなデメリットの1つは費用がかかることです。価格はトークンごとに計算されます(いいえ、NFTやアーケードで使用するものではありません)。
LLMsの文脈では、トークンは基本的に単語と文字のセットを表す一連の数値です。例えば、「The」は1つのトークン、「 end」(スペースを含む)は別のトークン、「.」はまた別のトークンです。
したがって、テキスト「The End.」は、例えば(73、102、6)の3つのトークンで構成されるとします。
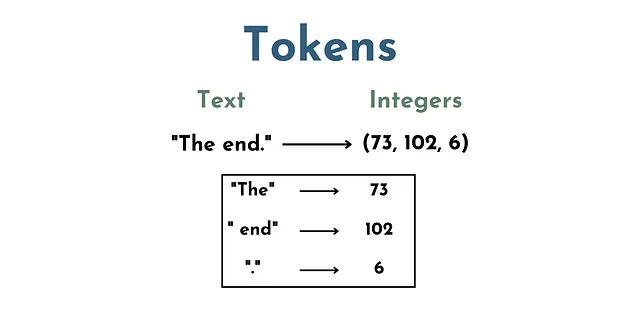
これは重要なステップです、なぜならLLMs(つまり、ニューラルネットワーク)はテキストを直接「理解」しないからです。モデルが入力に対して数学的な操作を行えるように、テキストを数値表現に変換する必要があるからです。したがって、トークン化のステップが必要です。
APIコールの価格は、プロンプトで使用されるトークンの数と指定されたモデルによって決まります。モデルごとの価格はOpenAIのウェブサイトで確認できます。
3) スタートするための手順(4つのステップ)
OpenAI APIの基本的な理解を得たので、どのように使用するかを見てみましょう。コーディングを始める前に、4つの設定が必要です。
3.1) アカウントを作成する(最初の3ヶ月は$5のAPIクレジットがもらえます)
- アカウントを作成するには、OpenAI APIの概要ページにアクセスし、右上の「サインアップ」をクリックします。
- 注意:ChatGPTを使用したことがある場合は、おそらくすでにOpenAIアカウントを持っているでしょう。その場合、「ログイン」をクリックしてください。
3.2) 支払い方法の追加
- アカウントが3ヶ月以上経過しているか、無料の$5のAPIクレジットが十分でない場合は、APIの呼び出しを行う前に支払い方法を追加する必要があります。
- プロフィール画像をクリックし、アカウント管理オプションを選択します。
- 次に、「請求」タブをクリックして、支払い方法を追加します。
3.3) 使用制限の設定
- 次に、予算を超えて請求されないように、使用制限の設定をおすすめします。
- これを行うには、「請求」タブの「使用制限」に移動します。ここで「ソフト」および「ハード」の制限を設定できます。
- 月間の「ソフト制限」に達すると、OpenAIから「電子メール通知」が送信されます。
- 「ハード制限」に達すると、追加のAPIリクエストは拒否されます(つまり、この制限を超えて追加料金は発生しません)。
3.4) APIシークレットキーの取得
- 「APIキーを表示」をクリックします。
- 初めての場合は、新しいシークレットキーを作成する必要があります。これを行うには、「新しいシークレットキーを作成」をクリックします。
- 次に、キーにカスタム名前を付けることができます。ここでは「my-first-key」としました。
- 次に、「シークレットキーを作成」をクリックします。
4) サンプルコード:チャット補完API
セットアップがすべて完了したので、ついに最初のAPI呼び出しを行う準備が整いました。ここでは、OpenAIのモデルをPythonコードに簡単に統合することができるopenai Pythonライブラリを使用します。パッケージはpipを介してダウンロードできます。以下のサンプルコード(およびボーナスコード)は、この記事のGitHubリポジトリで利用できます。
補完APIの非推奨に関する注意事項 — OpenAIは、自由形式のプロンプトパラダイムからチャットベースのAPI呼び出しに移行しています。OpenAIのブログによると、チャットベースのパラダイムは、前のパラダイムと比べて構造化されたプロンプトインターフェースにより優れた応答を提供します[2]。
古いOpenAI(GPT-3)モデルは、まだ「自由形式」のパラダイムで利用できますが、より新しい(かつ強力な)モデル(つまり、GPT-3.5-turboおよびGPT-4)はチャットベースの呼び出しのみで利用できます。
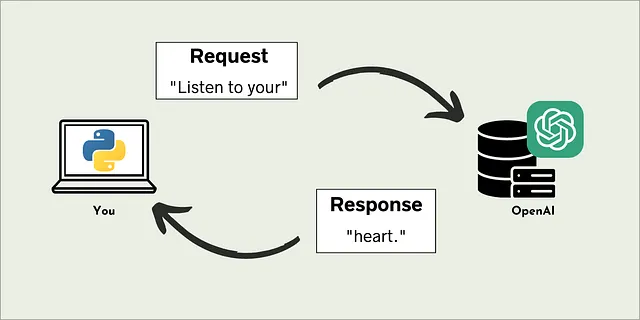
まずは、非常にシンプルなAPI呼び出しを始めましょう。ここでは、2つの入力をopenai.ChatCompletions.create()メソッドに渡します。つまり、モデルとメッセージです。
- モデル — 使用する言語モデルの名前を定義します(前述のモデルから選択できます)。
- メッセージ — 「前の」チャットダイアログを辞書のリストとして設定します。辞書には2つのキーバリューペアがあります(例:{“role”: “user”, “content”: “Listen to your”})。最初に、「role」は話している人物を定義します(例:「role」:「user」)。これは「user」、「assistant」、または「system」のいずれかにすることができます。次に、「content」は役割が言っていることを定義します(例:「content」:「Listen to your」)。これは自由形式のプロンプトインターフェースよりも制約があるかもしれませんが、特定のユースケースに対して応答を最適化するために入力メッセージを工夫することができます(後述)。
これがPythonでの最初のAPI呼び出しの例です。
import openaifrom sk import my_sk # 外部ファイルからシークレットキーをインポートimport time# シークレットキーをインポート(またはここにコピーペースト)openai.api_key = my_sk # チャット補完を作成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Listen to your"}])APIの応答はchat_completion変数に格納されます。chat_completionを表示すると、6つのキーバリューペアからなる辞書のようなものであることがわかります。
{'id': 'chatcmpl-7dk1Jkf5SDm2422nYRPL9x0QrlhI4', 'object': 'chat.completion', 'created': 1689706049, 'model': 'gpt-3.5-turbo-0613', 'choices': [<OpenAIObject at 0x7f9d1a862b80> JSON: { "index": 0, "message": { "role": "assistant", "content": "心臓。" }, "finish_reason": "停止" }], 'usage': <OpenAIObject at 0x7f9d1a862c70> JSON: { "prompt_tokens": 10, "completion_tokens": 2, "total_tokens": 12 }}各フィールドの意味は以下の通りです。
- ‘Id’ = APIレスポンスの一意のID
- ‘Object’ = レスポンスを送信したAPIオブジェクトの名前
- ‘Created’ = APIリクエストが処理されたUNIXタイムスタンプ
- ‘Model’ = 使用されたモデルの名前
- ‘Choices’ = JSON形式でフォーマットされたモデルの応答(辞書のような形式)
- ‘Usage’ = JSON形式でフォーマットされたトークン数のメタデータ(辞書のような形式)
ただし、ここで重要なのは「‘Choices’」フィールドです。なぜなら、これがモデルの応答が格納される場所だからです。この場合、「アシスタント」の役割が「心臓。」というメッセージで応答していることがわかります。
やった!最初のAPI呼び出しを行いました。では、モデルの入力パラメータで遊んでみましょう。
max_tokens
まず、max_tokensの入力パラメータを使用して、モデルの応答で許可されるトークンの最大数を設定できます。これは、使用例に応じてさまざまな理由で役立ちます。この場合、1単語の応答を求めるだけなので、トークンを1つに設定します。
# max_tokensの設定# チャットの完了を作成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "あなたのことを聞いて"}], max_tokens = 1)# チャットの完了を出力print(chat_completion.choices[0].message.content)"""出力:>>> 心臓 """n
次に、モデルから受け取りたい応答の数を設定できます。これも使用例に応じてさまざまな理由で役立ちます。例えば、最も好きな応答を選択できるセットの応答を生成したい場合などです。
# nの設定# チャットの完了を作成chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "あなたのことを聞いて"}], max_tokens = 2, n=5)# チャットの完了を出力for i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""出力:>>> 心臓.>>> 心臓 と>>> 心臓.>>>>>> 心臓,>>>>>> 心臓,"""すべての完了が同一ではないことに注意してください。これは使用例によっては良いことか悪いことかが異なる場合があります(例:創造的な使用例対プロセス自動化の使用例)。そのため、特定のプロンプトに対してチャットの完了の多様性を調整することは有利になる場合があります。
temperature
実際には、temperatureパラメータを調整することで、チャットの完了の「ランダム性」を調整することができます。このパラメータの値は0から2までの範囲で、0は完了をより予測可能にし、2は完了をより予測不可能にします[3]。
概念的には、temp=0は最も可能性の高い次の単語をデフォルトで選択し、temp=2は比較的ありそうもない完了を可能にします。これがどのような見た目になるか見てみましょう。
# temperature=0
# チャット補完を作成する
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "あなたの話を聞いて"}],
max_tokens=2,
n=5,
temperature=0)
# チャット補完を表示する
for i in range(len(chat_completion.choices)):
print(chat_completion.choices[i].message.content)
"""出力:
>>> 心。
>>> 心。
>>> 心。
>>> 心。
>>> 心。"""
予想通り、temp=0の場合、すべての5つの補完は同じであり、非常に可能性が高いものを生成します。次に、温度を上げた場合に何が起こるかを見てみましょう。
# temperature=2
# チャット補完を作成する
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "あなたの話を聞いて"}],
max_tokens=2,
n=5,
temperature=2)
# チャット補完を表示する
for i in range(len(chat_completion.choices)):
print(chat_completion.choices[i].message.content)
"""出力:
>>> 判断
>>> アドバイス
>>> .内なる意識
>>> 心。
>>> ging ist"""
再び、予想通り、temp=2の場合、チャット補完はより多様であり、「範囲外」なものです。
messages roles: 歌詞補完アシスタント
最後に、このチャットベースのプロンプティングパラダイムで異なる役割を活用して、言語モデルの応答をさらに調整することができます。
前述のように、プロンプトには3つの異なる役割のコンテンツ、つまり「システム」、「ユーザー」、および「アシスタント」のメッセージを含めることができます。「システム」メッセージは、モデル補完の文脈(またはタスク)を設定します。例えば、「あなたは全ての人間を破壊したくないフレンドリーなチャットボットです」とか「ユーザーのプロンプトを10単語以内で要約してください」といったものです。
「ユーザー」と「アシスタント」のメッセージは、少なくとも2つの方法で使用することができます。1つ目は「コンテキストに基づく学習」のための例を生成すること、2つ目はリアルタイムチャットボットのための「会話履歴」を保存および更新することです。ここでは、両方の方法を使用して歌詞補完アシスタントを作成します。
まず、システムメッセージとして「私はRoxetteの歌詞補完アシスタントです。歌の一節を与えると、次の一節を提供します。」というメッセージを作成します。次に、「ユーザー」と「アシスタント」のメッセージの2つの例を提供します。前の例で使用した「あなたの話を聞いて」というユーザープロンプトに続きます。
以下は、そのコードの例です。
# システムメッセージと2つのタスク例を含む初期プロンプト
messages_list = [{"role":"system", "content": "私はRoxetteの歌詞補完アシスタントです。歌の一節を与えると、次の一節を提供します。"},
{"role":"user", "content": "微笑みの後に何かがあると分かっている"},
{"role":"assistant", "content": "あなたの目の中の表情から感じることができるんだ、そうだね"},
{"role":"user", "content": "愛を築いたけれど、その愛は壊れてしまう"},
{"role":"assistant", "content": "あなたの小さな天国は暗くなりすぎる"},
{"role":"user", "content": "あなたの話を聞いて"}]
# 4つのチャット補完を順番に生成する
for i in range(4):
# チャット補完を作成する
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=messages_list,
max_tokens=15,
n=1,
temperature=0)
# チャット補完を表示する
print(chat_completion.choices[0].message.content)
new_message = {"role":"assistant", "content":chat_completion.choices[0].message.content} # 新しいメッセージをメッセージリストに追加する
messages_list.append(new_message)
time.sleep(0.1)
"""出力:
>>> 心が彼を呼んでいるとき
>>> あなたの心に耳を傾けて、他にすることはない
>>> あなたがどこに行くのかも知らないし、なぜ行くのかも知らない
>>> でも彼にさよならを伝える前に、あなたの心に耳を傾けて"""ヒット曲のRoxetteの歌詞と出力を比較すると、完全に一致していることがわかります。これは、モデルに提供したさまざまな入力の組み合わせによるものです。
「温度を上げる」ときの見た目を確認するには、GitHubのボーナスコードをチェックしてください(警告:奇妙になります)。
結論
ここでは、OpenAI Python APIの初心者向けガイドと例のコードを紹介しました。OpenAIのAPIを使用する最大の利点は、計算リソースの配備について心配することなく強力なLLM(Language Model)と一緒に作業できることです。ただし、APIの呼び出しには費用がかかり、一部のデータを第三者(OpenAI)と共有することに関するセキュリティ上の懸念があります。
これらのデメリットを回避するために、オープンソースのLLMソリューションに切り替えることができます。次の記事では、Hugging Face Transformersライブラリを探求します。
リソース
連絡先:私のウェブサイト | 電話予約 | 何でも聞いてください
ソーシャル:YouTube 🎥 | LinkedIn | Twitter
サポート:メンバーになる ⭐️ | コーヒーをご馳走になる ☕️
データ起業家
データ領域の起業家のためのコミュニティ。👉 ディスコードに参加してください!
VoAGI.com
[1] OpenAIモデルドキュメント
[2] GPT-4の利用可能性と補完APIの非推奨化
[3] APIリファレンスからの温度の定義
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
