OpenAIを使用してカスタムチャットボットを開発する
OpenAIを使用してチャットボットを開発する
はじめに
チャットボットは自動化されたサポートと個別の体験を提供し、ビジネスが顧客とつながる方法を革新しました。人工知能(AI)の最新の進展により、チャットボットの機能性の基準が引き上げられました。この詳細な書籍では、強力な言語モデルで知られるAIプラットフォームのリーディングカンパニーであるOpenAIを使用してカスタムチャットボットを作成するための詳細な手順が提供されています。
この記事はData Science Blogathonの一環として公開されました。
チャットボットとは何ですか?
チャットボットは人間の会話を模倣するコンピュータプログラムです。自然言語処理(NLP)の技術を使用して、ユーザーの言っていることを理解し、関連性のある助言を提供します。

- Amazon SageMakerを使用して電子メールのスパム検出器を構築する
- メタからのLlama 2基盤モデルは、Amazon SageMaker JumpStartで利用可能になりました
- 「太陽エネルギーが新たな展開を迎える」
大量のデータセットと優れた機械学習アルゴリズムの利用可能性により、チャットボットは近年ますます賢くなっています。これらの機能により、チャットボットはユーザーの意図をより良く把握し、より本物らしい返答を提供することができます。
チャットボットの具体的な利用例:
- 顧客サービスのチャットボットは、よく寄せられる質問に答えて、消費者に24時間体制でサポートを提供します。
- マーケティングのチャットボットは、リードの質を確認し、リードを生成し、製品やサービスに関する質問に答えるのを支援することができます。
- 教育のチャットボットは、個別指導を提供し、学生が自分のペースで学ぶことができるようにします。
- 医療のチャットボットは、健康に関する情報を提供し、薬に関する質問に答え、患者を医師や他の医療専門家とつなげることができます。
OpenAIの紹介
OpenAIは人工知能の研究開発の最前線にあります。自然言語の解釈と生成に優れた言語モデルの開発に先駆けて取り組んでいます。

OpenAIは、GPT-4、GPT-3、Text-davinciなどの高度な言語モデルを提供しており、チャットボットの構築などのNLP活動に広く使用されています。
チャットボットの利点
コーディングと実装に入る前に、チャットボットの利点を理解しましょう。
- 24時間365日の利用可能性: チャットボットはユーザーに24時間体制でサポートを提供し、人間の顧客サービス担当者の制約をなくし、ビジネスが顧客の要求に対応できるようにします。
- 改善された顧客サービス: チャットボットは頻繁に問い合わせられる質問に迅速かつ正確に応答することができます。これにより、顧客サービス全体の品質が向上します。
- コスト削減: ビジネスは顧客サポートの業務を自動化し、大規模なサポートスタッフの必要性を減らすことで、長期的に多額の費用を節約することができます。
- 効率の向上: チャットボットは複数の会話を同時に管理できるため、迅速な応答とユーザーの待ち時間の削減を保証します。
- データの収集と分析: チャットボットはユーザーとのやり取りから有用な情報を収集することができ、企業は顧客の好み、要望、問題点を理解することができます。このデータを活用して、製品やサービスの改善を行います。
チャットボットの利点を把握したので、OpenAIを使用してカスタムチャットボットを構築するために必要なコードのステップバイステップの解説に進みましょう。
ステップ
ステップ1:必要なライブラリのインポート
必要なライブラリをインポートする必要があります。提供されたコードでは、次のインポートステートメントが表示されます:
!pip install langchain
!pip install faiss-cpu
!pip install openai
!pip install llama_index
# または次のように使用することもできます
%pip install langchain
%pip install faiss-cpu
%pip install openai
%pip install llama_index次に進む前に、これらのライブラリがインストールされていることを確認してください。
ステップ2:APIキーの設定
OpenAI APIとのやり取りにはAPIキーが必要です。提供されたコードでは、APIキーを追加する場所を示すプレースホルダがあります:
APIキーを見つけるには、openaiのウェブサイトにアクセスし、新しいopenaiキーを作成します。
import os
os.environ["OPENAI_API_KEY"] = 'ここにAPIキーを追加してください'‘ここにAPIキーを追加してください’を、OpenAIから取得した実際のAPIキーで置き換えてください。
ステップ3:ナレッジベースの作成とインデックス作成
このステップでは、チャットボットがユーザーのクエリに答えるために参照するナレッジベースを作成し、インデックス化します。提供されたコードでは、2つのアプローチが示されています:ディレクトリからドキュメントをロードする方法と、既存のインデックスをロードする方法です。最初のアプローチに焦点を当てましょう。
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('/Users/tarakram/Documents/Chatbot/data').load_data()
print(documents)SimpleDirectoryReaderクラスを使用して、特定のディレクトリからドキュメントをロードします。
‘/Users/tarakram/Documents/Chatbot/data’を、ナレッジベースドキュメントが含まれるディレクトリのパスに置き換えてください。load_data()関数はドキュメントをロードし、それらを返します。
ドキュメントをロードした後、GPTVectorStoreIndexクラスを使用してインデックスを作成する必要があります:
index = GPTVectorStoreIndex.from_documents(documents)このステップでは、ロードしたドキュメントを使用してインデックスを作成します。
ステップ4:インデックスの永続化
コードが実行されるたびにインデックスを再構築する必要を避けるために、インデックスをディスクに永続化することができます。提供されたコードでは、次の行を使用してインデックスを保存します:
# インデックスを保存
index.storage_context.persist('/Users/tarakram/Documents/Chatbot')‘/Users/tarakram/Documents/Chatbot’を、インデックスを保存するディレクトリパスに置き換えてください。
インデックスを永続化することで、追加のトークンコストを発生せずに後続の実行でインデックスをロードすることができます。
ステップ5:インデックスのロード
以前に保存したインデックスをロードしたい場合は、次のコードを使用できます:
from llama_index import StorageContext, load_index_from_storage
# ストレージコンテキストを再構築
storage_context = StorageContext.from_defaults
(persist_dir='/Users/tarakram/Documents/Chatbot/index')
# インデックスをロード
index = load_index_from_storage(storage_context)‘/Users/tarakram/Documents/Chatbot/index’を、インデックスを保存した正しいディレクトリパスに更新してください。
ステップ6:チャットボットクラスの作成
さて、実際のチャットボットクラスを作成し、ユーザーとやり取りし、応答を生成することに移りましょう。提供されたコードは次のとおりです:
# チャットボット
import openai
import json
class Chatbot:
def __init__(self, api_key, index):
self.index = index
openai.api_key = api_key
self.chat_history = []
def generate_response(self, user_input):
prompt = "\n".join([f"{message['role']}: {message['content']}"
for message in self.chat_history[-5:]])
prompt += f"\nUser: {user_input}"
query_engine = index.as_query_engine()
response = query_engine.query(user_input)
message = {"role": "assistant", "content": response.response}
self.chat_history.append({"role": "user", "content": user_input})
self.chat_history.append(message)
return message
def load_chat_history(self, filename):
try:
with open(filename, 'r') as f:
self.chat_history = json.load(f)
except FileNotFoundError:
pass
def save_chat_history(self, filename):
with open(filename, 'w') as f:
json.dump(self.chat_history, f)Chatbotクラスには、提供されたAPIキーとインデックスでチャットボットインスタンスを初期化するための__init__メソッドがあります。
generate_responseメソッドは、ユーザーの入力を受け取り、インデックスとOpenAI APIを使用して応答を生成し、チャット履歴を更新します。
load_chat_historyメソッドとsave_chat_historyメソッドは、それぞれチャット履歴をロードおよび保存するために使用されます。
ステップ7:チャットボットとの対話
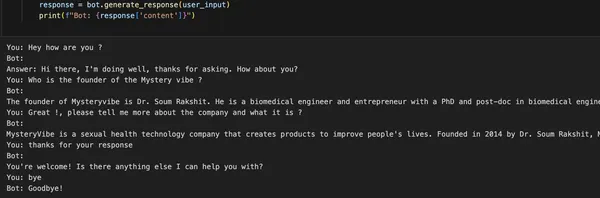
最終のステップは、チャットボットとの対話です。以下は、チャットボットの使用方法を示すコードの断片です。
bot = Chatbot("ここにAPIキーを追加", index=index)
bot.load_chat_history("chat_history.json")
while True:
user_input = input("You: ")
if user_input.lower() in ["bye", "goodbye"]:
print("Bot: Goodbye!")
bot.save_chat_history("chat_history.json")
break
response = bot.generate_response(user_input)
print(f"Bot: {response['content']}")チャットボットを使用するには、Chatbotクラスのインスタンスを作成して、OpenAIのAPIキーとロードされたインデックスを渡します。
「ここにAPIキーを追加」という部分を実際のAPIキーに置き換えてください。load_chat_historyメソッドは、チャット履歴をファイルから読み込むために使用されます(「chat_history.json」の部分を実際のファイルパスに置き換えてください)。
その後、ユーザーの入力を繰り返し取得し、応答を生成するためにwhileループが使用されます。ユーザーが「bye」または「goodbye」と入力するまで、入力と応答を繰り返し表示します。
save_chat_historyメソッドは、チャット履歴をファイルに保存するために使用されます。
ステップ8:Streamlitを使用したWebアプリケーションの構築
提供されたコードには、Streamlitを使用して構築されたWebアプリケーションも含まれており、ユーザーがユーザーインターフェースを介してチャットボットと対話できるようになっています。以下は、提供されたコードです。
import streamlit as st
import json
import os
from llama_index import StorageContext, load_index_from_storage
os.environ["OPENAI_API_KEY"] = 'ここにAPIキーを追加'
# ストレージコンテキストを再構築
storage_context = StorageContext.from_defaults
(persist_dir='/Users/tarakram/Documents/Chatbot/index')
# インデックスをロード
index = load_index_from_storage(storage_context)
# チャットボットを作成
# チャットボット
import openai
import json
class Chatbot:
def __init__(self, api_key, index, user_id):
self.index = index
openai.api_key = api_key
self.user_id = user_id
self.chat_history = []
self.filename = f"{self.user_id}_chat_history.json"
def generate_response(self, user_input):
prompt = "\n".join([f"{message['role']}: {message['content']}"
for message in self.chat_history[-5:]])
prompt += f"\nUser: {user_input}"
query_engine = index.as_query_engine()
response = query_engine.query(user_input)
message = {"role": "assistant", "content": response.response}
self.chat_history.append({"role": "user", "content": user_input})
self.chat_history.append(message)
return message
def load_chat_history(self):
try:
with open(self.filename, 'r') as f:
self.chat_history = json.load(f)
except FileNotFoundError:
pass
def save_chat_history(self):
with open(self.filename, 'w') as f:
json.dump(self.chat_history, f)
# Streamlitアプリ
def main():
st.title("Chatbot")
# ユーザーID
user_id = st.text_input("Your Name:")
# ユーザーIDが提供されているかどうかをチェック
if user_id:
# ユーザーのためのチャットボットインスタンスを作成
bot = Chatbot("ここにAPIキーを追加", index, user_id)
# チャット履歴をロード
bot.load_chat_history()
# チャット履歴を表示
for message in bot.chat_history[-6:]:
st.write(f"{message['role']}: {message['content']}")
# ユーザー入力
user_input = st.text_input("ここに質問を入力してください :) - ")
# 応答を生成
if user_input:
if user_input.lower() in ["bye", "goodbye"]:
bot_response = "さようなら!"
else:
bot_response = bot.generate_response(user_input)
bot_response_content = bot_response['content']
st.write(f"{user_id}: {user_input}")
st.write(f"Bot: {bot_response_content}")
bot.save_chat_history()
bot.chat_history.append
({"role": "user", "content": user_input})
bot.chat_history.append
({"role": "assistant", "content": bot_response_content})
if __name__ == "__main__":
main()Webアプリケーションを実行するには、Streamlitがインストールされていることを確認してください(pip install streamlit)。
実際のOpenAI APIキーで「Add your API Key here」と置き換えてください。
その後、streamlit run app.pyコマンドを使用してアプリケーションを実行できます。
Webアプリケーションがブラウザで開き、提供されたユーザーインターフェースを介してチャットボットと対話することができます。
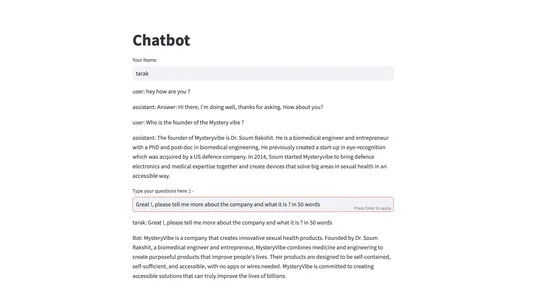
チャットボットのパフォーマンスの向上
以下の方法を考慮して、チャットボットのパフォーマンスを向上させることができます:
- ファインチューニング:さらなるデータでチャットボットモデルの理解能力と応答生成スキルを継続的に向上させるために、ファインチューニングを行います。
- ユーザーフィードバックの統合:ユーザーフィードバックループを統合して、実世界のユーザーインタラクションに基づいてチャットボットのパフォーマンスを向上させるための洞察を収集します。
- ハイブリッドテクニック:ルールベースのシステムとAIモデルを組み合わせたハイブリッドテクニックを調査し、複雑な状況を効果的に処理することができます。
- ドメイン固有の情報:特定のトピック領域でのチャットボットの専門知識と正確性を高めるために、ドメイン固有の情報とデータを含めます。
結論
おめでとうございます!OpenAIを使用してカスタムチャットボットを作成する方法を学びました。このガイドでは、OpenAIを使用して独自のチャットボットを作成する方法を見てきました。必要なライブラリのセットアップ、APIキーの取得、ナレッジベースの作成とインデックス作成、チャットボットクラスの作成、チャットボットとの対話などの手順をカバーしました。
また、使いやすいユーザーインターフェースのためにStreamlitを使用してWebアプリケーションを構築するオプションも探索しました。チャットボットの作成は反復的なプロセスであり、機能を向上させるためには常に改善を行う必要があります。OpenAIの力を活用し、AIの最新の進歩に常にアップデートされることで、優れたユーザーエクスペリエンスと意味のあるサポートを提供するチャットボットを設計することができます。異なるプロンプト、トレーニングデータ、ファインチューニングの技法を試して、特定のニーズに合わせたチャットボットを作成してください。可能性は無限であり、OpenAIはチャットボット技術のポテンシャルを探求し解き放つための強力なプラットフォームを提供しています。
キーポイント
- OpenAIを使用してカスタムチャットボットを構築するプロセスでは、必要なライブラリのセットアップ、APIキーの取得、ナレッジベースの生成とインデックス作成、チャットボットクラスの実装などのステップがあります。
- チャットボットは、自然言語でのヘルプや質問への回答により人間の対話を模倣するコンピュータープログラムです。
- 効率的なチャットボットをトレーニングするためには、信頼できる情報源から関連性の高いさまざまなデータセットを取得することが重要です。
- OpenAIのGPT-3.5言語モデルを使用した対話型AIアプリケーションは、自然言語処理における強力なツールです。
- Llamasライブラリなどのツールを使用してナレッジベースをインデックス化および検索することは、チャットボットの関連データの取得能力を大幅に向上させることができます。
- Streamlitは、直感的なユーザーインターフェースを介してユーザーがチャットボットと対話するための実用的なフレームワークを提供しています。
Githubでコードにアクセスできます – リンク
Linkedinで私とつながってください – リンク
よくある質問
この記事に表示されているメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





