「SD-Small」と「SD-Tiny」の知識蒸留コードと重みのオープンソース化
Open-sourcing of knowledge distillation code and weights for 'SD-Small' and 'SD-Tiny

近年、AIコミュニティでは、Falcon 40B、LLaMa-2 70B、Falcon 40B、MPT 30Bなど、より大きく、より高性能な言語モデルの開発が著しく進んでいます。また、SD2.1やSDXLなどの画像領域のモデルでも同様です。これらの進歩は、AIが達成できることの境界を押し広げ、高度に多様かつ最先端の画像生成および言語理解の能力を可能にしています。しかし、これらのモデルのパワーと複雑さを驚嘆しながらも、AIモデルをより小さく、効率的に、そしてよりアクセスしやすくするという成長するニーズの認識が不可欠です。特に、オープンソース化によってこれらのモデルを利用可能にすることが求められています。
Segmindでは、生成型AIモデルをより速く、安価にする方法に取り組んできました。昨年、voltaMLという加速されたSD-WebUIライブラリをオープンソース化しました。これはAITemplate/TensorRTベースの推論高速化ライブラリであり、推論速度が4~6倍向上しました。生成モデルをより速く、小さく、安価にする目標に向けて、私たちは圧縮されたSDモデル「SD-Small」と「SD-Tiny」の重みとトレーニングコードをオープンソース化しています。事前学習済みのチェックポイントはHuggingfaceで利用可能です🤗
知識蒸留

私たちの新しい圧縮モデルは、知識蒸留(KD)技術に基づいてトレーニングされており、この論文に大きく依存しています。著者は、いくつかのUNetレイヤーを削除し、学習された生徒モデルの重みを説明したブロック除去知識蒸留法について説明しています。論文で説明されているKDの手法を使用して、圧縮モデル2つをトレーニングしました。🧨 diffusersライブラリを使用してトレーニングした「Small」と「Tiny」は、ベースモデルと比較してそれぞれ35%と55%少ないパラメータを持っており、ベースモデルと同様の画像品質を実現しています。私たちはこのリポジトリで蒸留コードをオープンソース化し、Huggingfaceで事前学習済みのチェックポイントを提供しています🤗
ニューラルネットワークの知識蒸留トレーニングは、先生が生徒をステップバイステップで指導するのと似ています。大きな先生モデルは大量のデータで事前トレーニングされ、その後、より小さなモデルは小規模なデータセットでトレーニングされ、クラシカルなトレーニングと共に、大きなモデルの出力を模倣するようになります。
この特定の種類の知識蒸留では、生徒モデルは通常の拡散タスクである純粋なノイズからの画像の復元を行うようにトレーニングされますが、同時に、モデルは大きな先生モデルの出力と一致するようになります。出力の一致はU-netの各ブロックで行われるため、モデルの品質はほとんど保たれます。したがって、前述のアナロジーを使用すると、このような蒸留中、生徒は質問と回答だけでなく、先生の回答からも学び、回答に至る方法もステップバイステップで学ぼうとします。これを達成するために、損失関数には3つのコンポーネントがあります。まず、ターゲット画像の潜在変数と生成された画像の潜在変数の間の従来の損失です。次に、先生が生成した画像の潜在変数と生徒が生成した画像の潜在変数の間の損失です。そして最後に、最も重要なコンポーネントであるフィーチャーレベルの損失です。これは、先生と生徒の各ブロックの出力の間の損失です。
これらすべてを組み合わせて、知識蒸留トレーニングが成り立ちます。以下は、論文「テキストから画像への拡散モデルのアーキテクチャ圧縮について」(Shinkookら)からのアーキテクチャの例です。
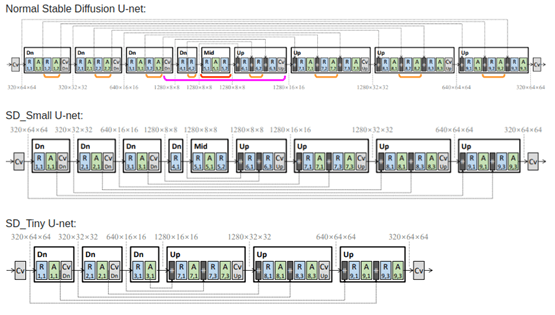
画像はShinkookらによる論文「テキストから画像への拡散モデルのアーキテクチャ圧縮について」から取得
私たちは、ベースとなる先生モデルとしてRealistic-Vision 4.0を選び、高品質な画像の説明を持つLAION Art Aestheticデータセットでトレーニングしました(画像スコアが7.5以上のもの)。論文とは異なり、私たちはSmallモードでは100Kステップ、Tinyモードでは125Kステップで1M枚の画像で2つのモデルをトレーニングしました。蒸留トレーニングのコードはこちらで見つけることができます。
モデルの使用方法
モデルは🧨 diffusersのDiffusionPipelineを使用して利用できます
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "美しい少女の肖像"
negative_prompt = "(変形した虹彩、変形した瞳孔、半リアル、CGI、3D、レンダリング、スケッチ、カートゥーン、ドローイング、アニメ:1.4)、テキスト、クローズアップ、切り抜き、フレーム外、最悪の品質、低品質、JPEGアーティファクト、醜い、重複、病的、切断された指、変異した手、下手に描かれた手、下手に描かれた顔、変異、変形、ぼやけた、脱水、悪い解剖学、悪い比例、余分な手足、複製された顔、変形した、不自然な比例、形成不全の手足、欠損した腕、欠損した足、余分な腕、余分な足、融合した指、指が多すぎる、長い首"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")推論の遅延時間における速度
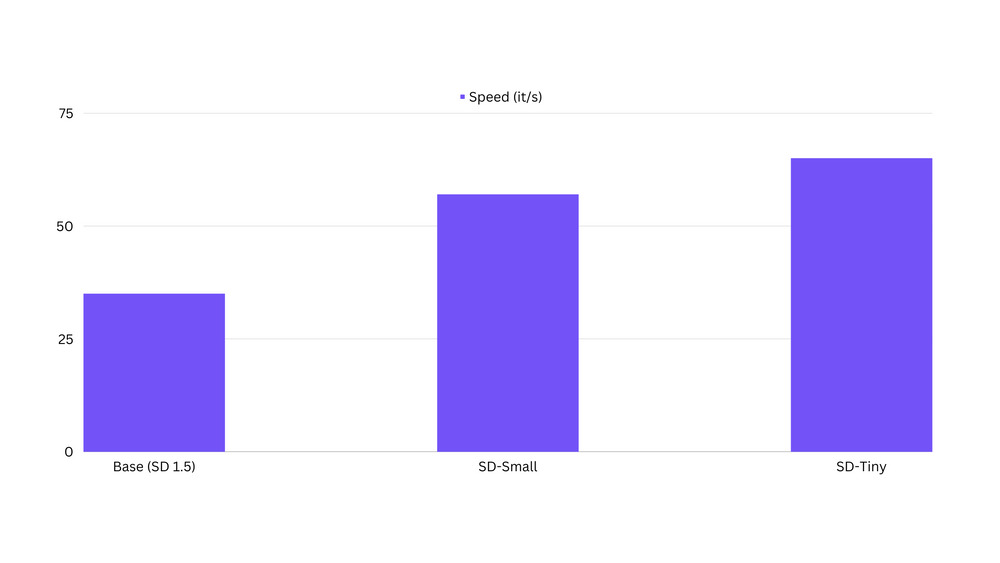
私たちは、蒸留モデルが元のベースモデルよりも最大100%高速であることを観察しています。ベンチマークコードはこちらで見つけることができます。
潜在的な制約事項
蒸留モデルは初期の段階にあり、出力はまだ製品品質ではないかもしれません。これらのモデルは最高の一般的なモデルではありません。それらは特定の概念/スタイルに微調整またはLoRAトレーニングされることが最適です。蒸留モデルはまだコンポジション性やマルチコンセプトには向いていません。
ポートレートデータセットでのSD-tinyモデルの微調整
私たちは、Realistic Vision v4.0モデルで生成されたポートレート画像に対してsd-tinyモデルを微調整しました。以下は使用された微調整パラメータです。
- ステップ数:131000
- 学習率:1e-4
- バッチサイズ:32
- 勾配蓄積ステップ:4
- 画像解像度:768
- データセットサイズ-7k枚の画像
- 混合精度:fp16
私たちは、元のモデルによって生成された画像にほぼ等しい画質を持つことができ、パラメータが約40%少なく、以下のサンプル結果が語っています。

ベースモデルの微調整のコードはこちらで見つけることができます。
LoRAトレーニング
蒸留モデルでのLoRAトレーニングの利点の1つは、より早いトレーニングです。以下は、いくつかの抽象的な概念に対して蒸留モデルでトレーニングした最初のLoRAのいくつかの画像です。LoRAトレーニングのコードはこちらで見つけることができます。

結論
我々はオープンソースコミュニティに私たちの蒸留SDモデルの改善と広範な採用を手伝ってもらいたいと思います。ユーザーは私たちのDiscordサーバーに参加することができます。そこでは、これらのモデルの最新のアップデート、より多くのチェックポイント、そしていくつかのエキサイティングな新しいLoRAを発表します。そして、私たちの作品が気に入った場合は、Githubでスターを付けてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






