「機械学習支援コンピュータアーキテクチャ設計のためのオープンソースジムナジウム」
Open Source Gymnasium for Machine Learning-Assisted Computer Architecture Design
Amir Yazdanbakhsh氏、研究科学者およびVijay Janapa Reddi氏、訪問研究者、Google Research
コンピュータアーキテクチャの研究は、コンピュータシステムの設計を評価し形成するためのシミュレータとツールの開発の長い歴史があります。たとえば、SimpleScalarシミュレータは1990年代末に導入され、さまざまなマイクロアーキテクチャのアイデアを探索することができました。gem5、DRAMSysなどのコンピュータアーキテクチャのシミュレータとツールは、コンピュータアーキテクチャの研究の進歩において重要な役割を果たしてきました。その後、これらの共有リソースとインフラストラクチャは、産業界と学界の両方に利益をもたらし、研究者がお互いの業績を体系的に積み重ねることを可能にし、この分野での重要な進展をもたらしました。
それにもかかわらず、コンピュータアーキテクチャの研究は進化し続けており、産業界と学界は機械学習(ML)最適化に向かって進んでいます。これには、コンピュータアーキテクチャのためのML、TinyMLアクセラレーションのためのML、DNNアクセラレータデータパス最適化、メモリコントローラ、消費電力、セキュリティ、プライバシーなど、厳格な特定のドメイン要件が含まれます。以前の研究は、設計最適化におけるMLの利点を示していますが、強力で再現性のあるベースラインの欠如は、異なる方法間での公平で客観的な比較を妨げ、展開にいくつかの課題を提起しています。着実な進歩を確保するためには、これらの課題を共同で理解し対処することが重要です。
これらの課題を緩和するために、「ArchGym:機械学習支援アーキテクチャ設計のためのオープンソースジム」というタイトルでISCA 2023で採用された論文において、ArchGymを紹介しました。ArchGymにはさまざまなコンピュータアーキテクチャシミュレータとMLアルゴリズムが含まれています。ArchGymの利用により、十分な数のサンプルがあれば、さまざまなMLアルゴリズムのいずれかが各ターゲット問題の最適なアーキテクチャ設計パラメータセットを見つけることができることが示されています。どの解決策も必ずしも他の解決策よりも優れているわけではありません。これらの結果はまた、与えられたMLアルゴリズムの最適なハイパーパラメータを選択することが、最適なアーキテクチャ設計を見つけるために不可欠であることを示していますが、それらを選択することは容易ではありません。私たちは、複数のコンピュータアーキテクチャシミュレーションとMLアルゴリズムを含むコードとデータセットを公開します。
- 「脳のように機能するコンピュータビジョンは、人々が見るように見ることができます」
- 「テキスト生成推論によるコンピュータからの大規模言語モデルの提供」
- 「高次元のカテゴリ変数に対する混合効果機械学習 – 第二部 GPBoostライブラリ」
機械学習支援アーキテクチャ研究の課題
機械学習支援アーキテクチャ研究には、次のようないくつかの課題があります:
- 特定の機械学習支援コンピュータアーキテクチャ問題(たとえば、DRAMコントローラの最適な解を見つける)に対して、最適なMLアルゴリズムやハイパーパラメータ(学習率、ウォームアップステップなど)を特定するための体系的な方法がありません。ランダムウォークから強化学習(RL)まで、MLとヒューリスティックな手法の幅広い範囲がDSEのために使用される可能性があります。これらの手法は、ベースラインの選択に比べて顕著な性能向上を示していますが、最適化アルゴリズムやハイパーパラメータの選択が改善の要因であるかどうかは明確ではありません。したがって、ML支援アーキテクチャDSEの再現性を確保し、普及を促進するために、体系的なベンチマーキング方法を明示する必要があります。
- コンピュータアーキテクチャシミュレータは、アーキテクチャのイノベーションの基盤となっていましたが、アーキテクチャの探索における正確性、速度、コストのトレードオフに対応する必要が出てきています。性能推定の正確性と速度は、サイクル精度とMLベースのプロキシモデルなどの基礎となるモデリングの詳細によって大きく異なります。解析的またはMLベースのプロキシモデルは詳細なレベルの詳細を捨てることによって俊敏性を持ちますが、一般に高い予測エラーを抱えます。また、商業ライセンスにより、シミュレータから収集された実行回数には厳しい制限がある場合があります。全体として、これらの制約は、パフォーマンスとサンプル効率のトレードオフに影響を与え、アーキテクチャ探索のための最適化アルゴリズムの選択に影響を与えるものです。これらの制約の下でさまざまなMLアルゴリズムの効果を体系的に比較する方法を明確にすることは困難です。
- 最後に、MLアルゴリズムの状況は急速に変化しており、一部のMLアルゴリズムはデータを必要とします。また、DSEの結果をデータセットなどの有意義な成果物に変換することは、設計空間に関する洞察を得るために重要です。この急速に変化するエコシステムでは、探索アルゴリズムのオーバーヘッドをどのように分散するかが重要です。基礎となる探索アルゴリズムには無関係に、探索データをどのように活用するかは明白ではなく、体系的に研究されていません。
ArchGymの設計
ArchGymは、異なるMLベースの探索アルゴリズムを公平に評価するための統一されたフレームワークを提供することによって、これらの課題に対処しています。主なコンポーネントは2つあります:1)ArchGym環境、および2)ArchGymエージェントです。環境は、アーキテクチャのコストモデルをカプセル化しています。これには、レイテンシ、スループット、面積、エネルギーなどが含まれます。アーキテクチャパラメータのセットに基づいて、ワークロードを実行するための計算コストを決定するためのものです。エージェントは、探索に使用されるMLアルゴリズムをカプセル化しています。これにはハイパーパラメータとガイドポリシーが含まれます。ハイパーパラメータは、最適化されるモデルに固有のアルゴリズムにとって内在的なものであり、パフォーマンスに大きな影響を与えることがあります。一方、ポリシーは、エージェントが反復的にパラメータを最適化するためにどのように選択するかを決定します。
特に、ArchGymにはこれらの2つのコンポーネントを接続する標準化されたインターフェースも含まれており、同時に探索データをArchGymデータセットとして保存します。インターフェースは、ハードウェアの状態、ハードウェアのパラメータ、およびメトリックスという3つの主要なシグナルから成り立っています。これらのシグナルを使用して、エージェントはハードウェアの状態を観測し、ハードウェアのパラメータのセットを提案し、(ユーザー定義の)報酬を反復的に最適化します。報酬は、パフォーマンス、エネルギー消費などのハードウェアのパフォーマンスメトリックスの関数です。
 |
| ArchGymは、ArchGym環境とArchGymエージェントの2つの主要なコンポーネントで構成されています。ArchGym環境はコストモデルをカプセル化し、エージェントはポリシーとハイパーパラメーターの抽象化です。これらの2つのコンポーネントを接続する標準化されたインターフェースにより、ArchGymは異なるMLベースの探索アルゴリズムを公平に評価する統一されたフレームワークを提供し、探索データをArchGymデータセットとして保存します。 |
MLアルゴリズムはユーザー定義のターゲット仕様を満たすために同様に好ましいです
ArchGymを使用して、さまざまな最適化目標とDSE問題において、他のMLアルゴリズムと同じハードウェアのパフォーマンスをもたらす少なくとも1つのハイパーパラメータのセットが存在することを実証的に示します。MLアルゴリズムまたはそのベースラインの適切に選択されていない(ランダムな選択)ハイパーパラメータは、特定のMLアルゴリズムの特定のファミリーが他のアルゴリズムよりも優れているという誤った結論につながる可能性があります。私たちは、十分なハイパーパラメータの調整により、ランダムウォーク(RW)を含むさまざまな探索アルゴリズムが最良の報酬を特定できることを示します。ただし、適切なハイパーパラメータのセットを見つけるには、徹底的な探索または運も必要な場合があります。
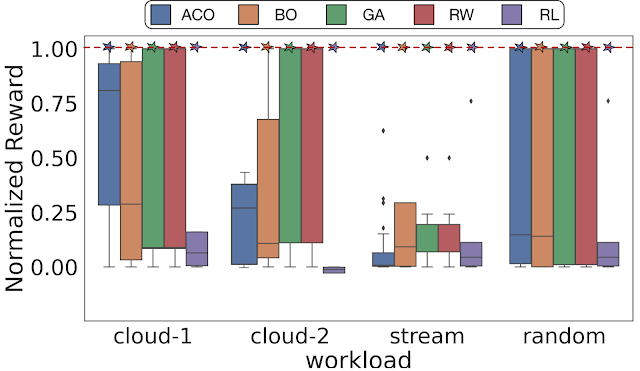 |
| 十分な数のサンプルがあれば、一連の探索アルゴリズムにわたって同じパフォーマンスをもたらす少なくとも1つのハイパーパラメータのセットが存在します。ここで、破線は最大の正規化報酬を示しています。Cloud-1、cloud-2、stream、randomはDRAMSys(DRAMサブシステム設計空間探索フレームワーク)の4つの異なるメモリトレースを示しています。 |
データセットの作成と高精度プロキシモデルのトレーニング
ArchGymを使用して統一されたインターフェースを作成することは、アーキテクチャシミュレーションの速度を向上させるためのデータ駆動型のMLベースのプロキシアーキテクチャコストモデルの設計に使用できるデータセットの作成を可能にします。アーキテクチャコストを近似するためのMLモデルを評価するために、ArchGymはDRAMSysからの各ランのデータを記録する能力を活用して、4つのデータセットバリアントを作成します。各バリアントには、2つのカテゴリを作成します:(a)異なるエージェント(ACO、GA、RW、BO)から収集されたデータを表す「多様なデータセット」と、(b)ACOエージェントのみから収集されたデータを示す「ACOのみ」。これらのデータセットはArchGymとともにリリースされます。私たちは、各データセットでランダムフォレスト回帰を使用してプロキシモデルをトレーニングし、DRAMシミュレータの設計のレイテンシを予測することを目的としています。私たちの結果は次のとおりです:
- データセットのサイズを増やすと、平均正規化二乗平均誤差(RMSE)はわずかに減少します。
- しかし、データセットの多様性を導入すると(例:異なるエージェントからデータを収集する)、異なるデータセットサイズ間で9倍から42倍低いRMSEが観測されます。
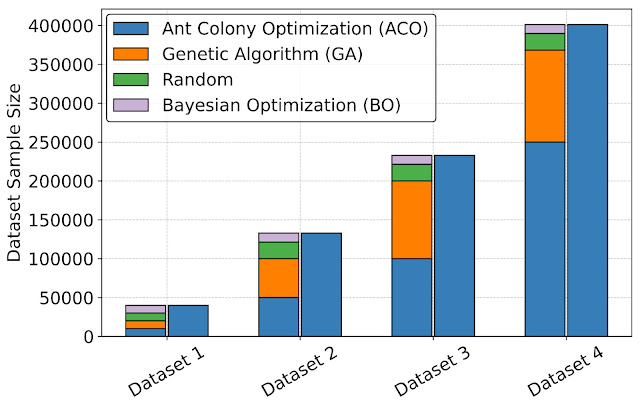 |
| ArchGymインターフェースを使用して異なるエージェント間で多様なデータセットを収集します。 |
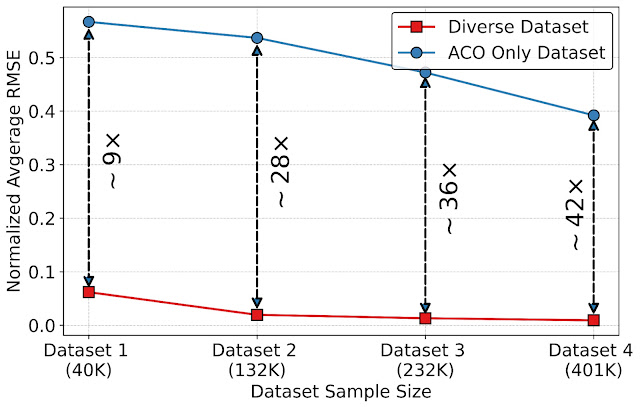 |
| 多様なデータセットとデータセットのサイズが正規化RMSEに与える影響。 |
ML支援アーキテクチャ研究のためのコミュニティ主導のエコシステムの必要性
ArchGymは、(1)さまざまな検索アルゴリズムをコンピュータアーキテクチャシミュレータに統一され、拡張しやすい方法で接続する、オープンソースのエコシステムを作成する初期の取り組みです。さらに、(2)ML支援コンピュータアーキテクチャの研究を促進し、(3)再現可能なベースラインを開発するための足場を形成します。しかし、これらの課題にはコミュニティ全体の支援が必要です。以下では、ML支援アーキテクチャ設計のいくつかの課題を概説します。これらの課題に取り組むには、よく調整された取り組みとコミュニティ主導のエコシステムが必要です。
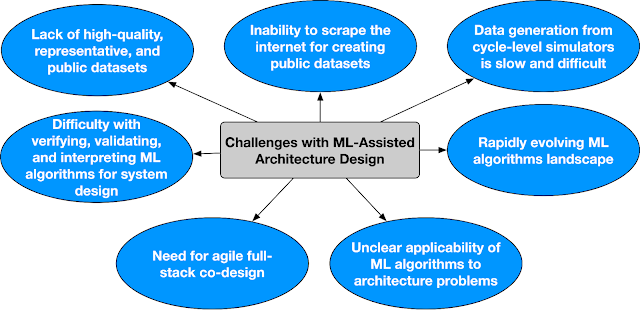 |
| ML支援アーキテクチャ設計の主要な課題。 |
このエコシステムをアーキテクチャ2.0と呼びます。MLをコンピュータアーキテクチャの研究に適用するための長年の課題に取り組むために、異分野の研究者の包括的なエコシステムを構築するビジョンと主要な課題について概説します。このエコシステムを形成するのに興味がある場合は、興味調査にご記入ください。
結論
ArchGymはMLアーキテクチャDSEのためのオープンソースのジムであり、異なるユースケースに合わせて簡単に拡張可能な標準化されたインターフェースを提供します。また、ArchGymは異なるMLアルゴリズム間での公平かつ再現可能な比較を可能にし、コンピュータアーキテクチャの研究問題に対するより強力なベースラインを確立するのに役立ちます。
私たちは、コンピューターアーキテクチャのコミュニティだけでなく、MLコミュニティにもArchGymの開発に積極的に参加していただくようお願いいたします。コンピューターアーキテクチャの研究のための体育館型の環境の創造は、この分野の大きな進歩となり、研究者がMLを利用して研究を加速し、新しい革新的なデザインにつながるプラットフォームを提供するものと信じています。
謝辞
このブログポストは、Googleとハーバード大学のいくつかの共著者との共同研究に基づいています。ハーバード大学のSrivatsan Krishnan(ハーバード)は、Shvetank Prakash(ハーバード)、Jason Jabbour(ハーバード)、Ikechukwu Uchendu(ハーバード)、Susobhan Ghosh(ハーバード)、Behzad Boroujerdian(ハーバード)、Daniel Richins(ハーバード)、Devashree Tripathy(ハーバード)、およびThierry Thambe(ハーバード)との共同作業において、このプロジェクトにいくつかのアイデアを貢献したことを認め、強調したいと思います。さらに、James Laudon、Douglas Eck、Cliff Young、およびAleksandra Faustにも、この仕事へのサポート、フィードバック、モチベーションに感謝いたします。また、この投稿で使用されているアニメーションフィギュアについては、John Guilyardにも感謝いたします。Amir Yazdanbakhshは現在、Google DeepMindの研究科学者であり、Vijay Janapa Reddiはハーバード大学の准教授です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ソフトウェア開発の革命:AIとコードのダイナミックなデュオ
- ウィスコンシン大学の新しい研究では、ランダム初期化から訓練された小さなトランスフォーマーが、次のトークン予測の目標を使用して効率的に算術演算を学ぶことができるかどうかを調査しています
- このAI論文では、LLMsの既存のタスクの新しいバリアントに適応する能力が評価されています
- 「ディープランゲージモデルは、コンテキストから次の単語を予測することを学ぶことで、ますます優れてきていますこれが本当に人間の脳が行っていることなのでしょうか?」
- 「DeepOntoに会ってください 深層学習を用いたオントロジーエンジニアリングのためのPythonパッケージ」
- 「3Dで動作する魔法の筆:Blended-NeRFはニューラル放射場におけるゼロショットオブジェクト生成を行うAIモデルです」
- 「MosaicMLは、AIユーザーが精度を向上し、コストを削減し、時間を節約するのを支援します」






