Open LLMのリーダーボードはどうなっていますか?
Open LLMのリーダーボードの状況は?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。
この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。
コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。
そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇
- オープンなMLモデルを使用してWebアプリジェネレータを作成する
- Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
- Transformers.jsを使用してMLを搭載したウェブゲームの作成
私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです!
この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。
準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。
Open LLM Leaderboardとは何ですか?
まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther AI LM Evaluation Harnessを実行するラッパーです。EleutherAIは、The PileやGPT-J、GPT-Neo-X 20B、およびPythiaを作成したことで有名なAI研究所です。
このラッパーは、Hugging Faceの計算クラスターの余剰サイクルを使用してEleuther AIハーネスで評価を実行し、その結果をハブのデータセットに保存し、オンラインのリーダーボードに表示します。
LLaMAモデルの場合、Eleuther AI LM Evaluation Harnessによって得られるMMLUの数値は、LLaMa論文で報告されるMMLUの数値と大きく異なることがあります。
なぜそうなるのでしょうか?
1001種類のMMLU
実際、LLaMAチームは、オリジナルのUC Berkeleyチームが開発したMMLUベンチマークの評価コード(https://github.com/hendrycks/test)を適応しました。ここでは、これを「オリジナルの実装」と呼びます。
さらに調査を進めると、同じMMLUデータセットで評価するための興味深い実装がもう一つ見つかりました。それはStanfordのCRFM非常に包括的な評価ベンチマーク「Holistic Evaluation of Language Models」で提供される評価コードで、ここでは「HELM実装」と呼びます。
EleutherAI HarnessとStanford HELMベンチマークの両方は興味深いものです。なぜなら、それらは複数の評価(MMLUを含む)を単一のコードベースでまとめているため、モデルのパフォーマンスを幅広く把握することができるからです。これが、Open LLM Leaderboardが個々のコードベースではなく、このような「包括的な」ベンチマークをラップしている理由です。
この問題を解決するために、同じMMLU評価の3つの可能な実装を実行し、それに基づいてモデルの順位を付けることにしました:
- Harness実装(コミットe47e01b)
- HELM実装(コミットcab5d89)
- オリジナル実装(Hugging Faceの素晴らしい@olmerによる統合、https://github.com/hendrycks/test/pull/13)
(なお、Harness実装は最近更新されました – 詳細はこの投稿の最後で説明します)
結果は驚くべきものです:
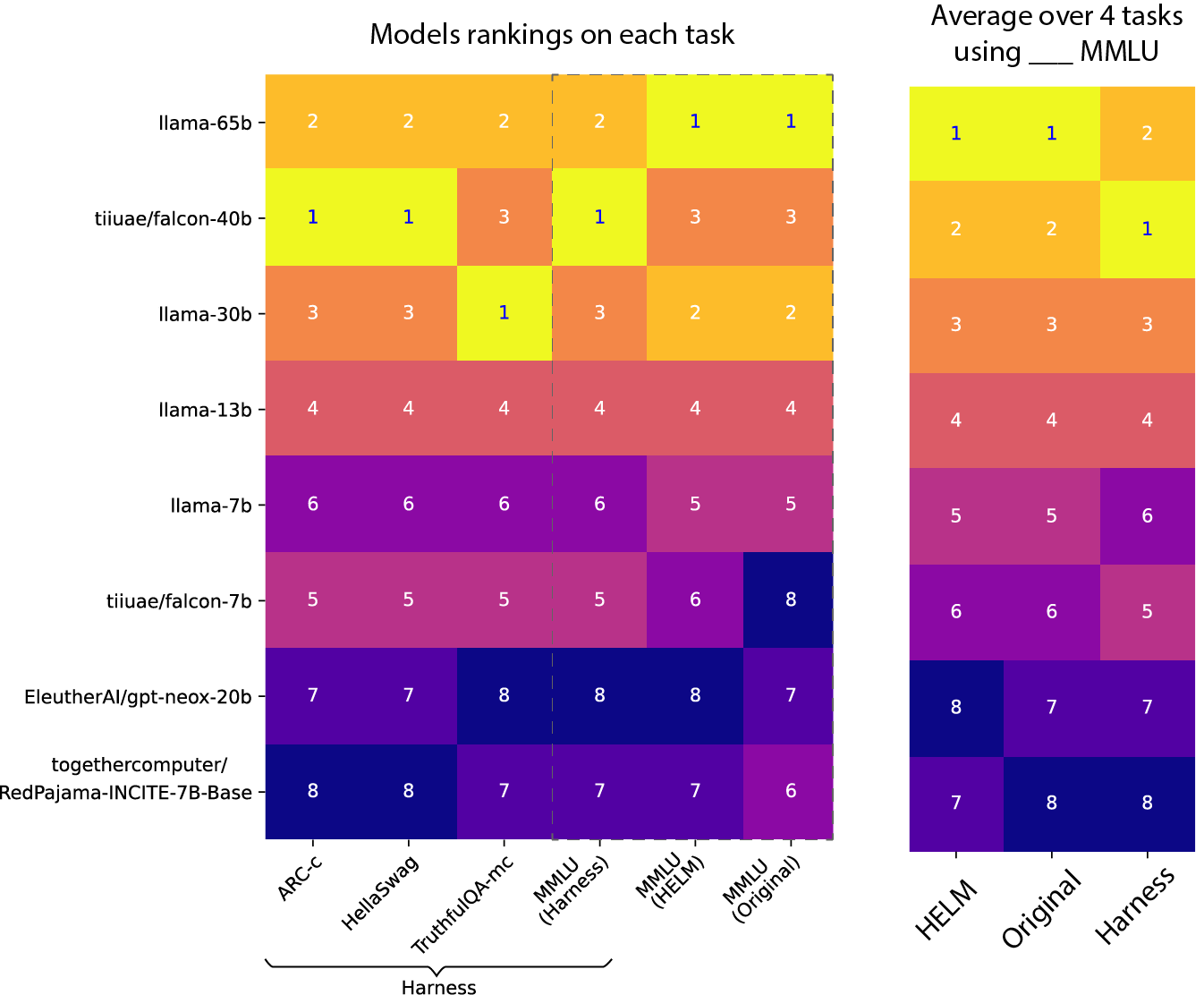
詳細な評価数値は投稿の最後に記載されています。
同じベンチマークのこれらの異なる実装は、大きく異なる数値を示し、さらにはリーダーボード上のモデルの順位も変えてしまいます!
この食い違いの原因について理解しようとしてみましょう 🕵️しかしまず、今日のLLM世界でモデルを自動評価する方法を簡単に理解しましょう。
現代のLLM世界でモデルを自動評価する方法
MMLUは複数選択問題のテストであり、開放型の質問と比べてかなり単純なベンチマークですが、実装の詳細や違いにはまだ多くの余地があります。このベンチマークには、57の一般的な知識領域を網羅した「人文科学」「社会科学」「STEM」などの粗いカテゴリにグループ化された4つの選択肢を持つ質問が含まれています。
各質問に対して、提供された選択肢のうち正しいものは1つだけです。以下に例を示します:
質問:グルコースは筋肉細胞にどのように輸送されますか?
選択肢:
A. GLUT4というタンパク質トランスポーターを介して。
B. インスリンの存在下のみ。
C. ヘキソキナーゼを介して。
D. 単炭酸トランスポーターを介して。
正解:A注意:このデータセットの詳細を簡単に調べることができます。ハブ上のデータセットビューアをご利用ください。
大型言語モデルはAIモデルの動物園におけるシンプルなモデルです。テキストの文字列(「プロンプト」と呼ばれる)を入力として受け取り、トークン(単語、サブワード、または文字、モデルの構築方法による)に分割し、モデルにフィードします。この入力から、彼らは次のトークンに対する確率分布を生成し、モデルが知っているすべてのトークン(モデルの「語彙」)にわたって、どのトークンが入力プロンプトの継続として「確率的に」どの程度の確率であり得るかを取得することができます。
これらの確率を使用してトークンを選択することができます。たとえば、最も確率が高いトークンを選択することができます(または、「あまりにも機械的」な回答を避けるためにサンプリングでわずかなノイズを導入することもできます)。選択したトークンをプロンプトに追加し、モデルにフィードバックすることで、別のトークンを生成し、入力プロンプトの継続として完全な文が生成されます:
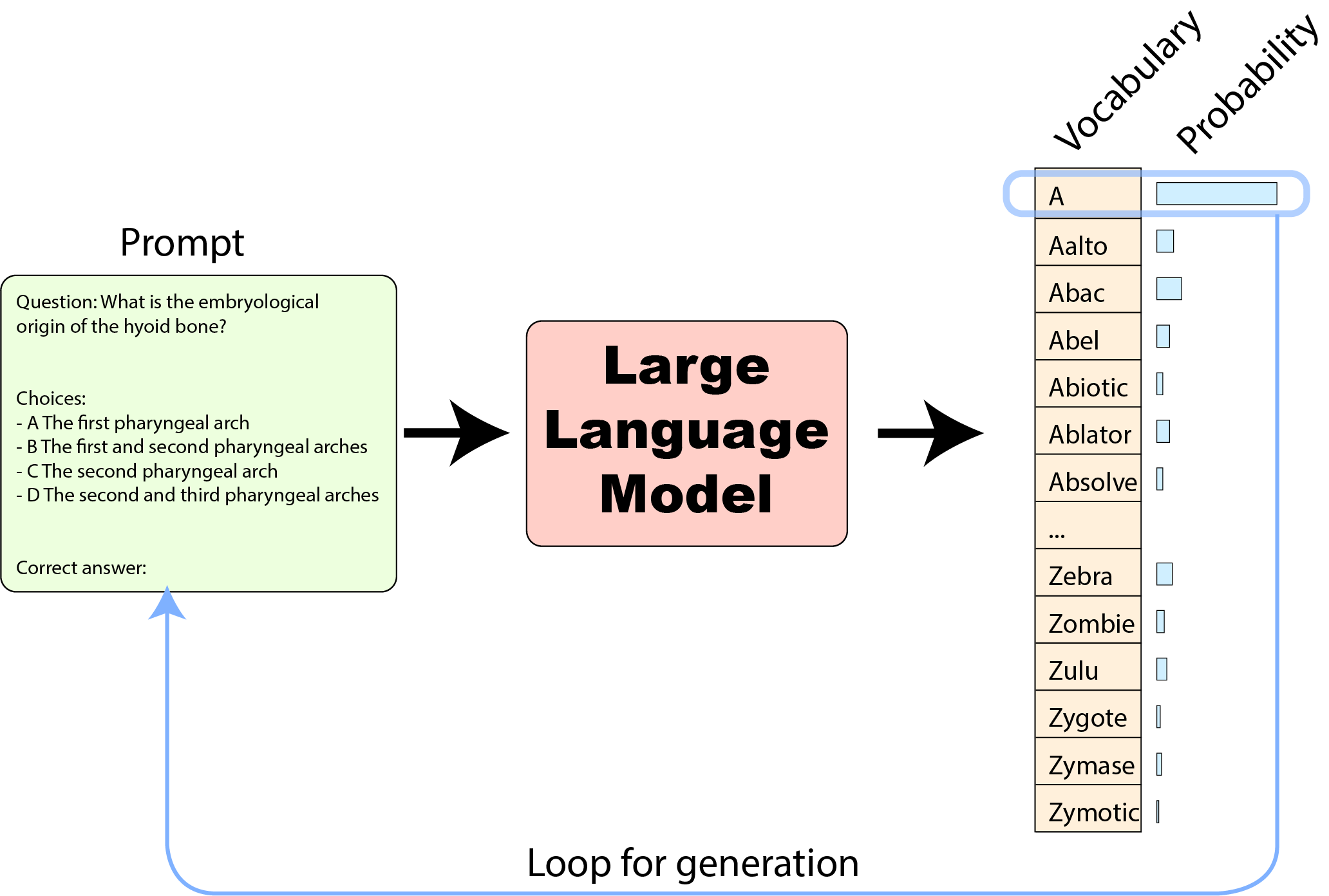
これがChatGPTやHugging Chatが回答を生成する方法です。
要約すると、モデルから情報を取得して評価するための2つの主な方法があります:
- プロンプトの継続として特定のトークングループの「確率」を取得し、事前定義された可能な選択肢と比較する。
- モデルから「テキスト生成」を取得する(前述のようにトークンを繰り返し選択することで)- そして、これらのテキスト生成をさまざまな事前定義された可能な選択肢のテキストと比較する。
この知識を持って、MMLUの3つの実装について詳しく見ていきましょう。モデルに送信される入力、出力の期待値、およびこれらの出力がどのように比較されるかを調べます。
MMLUはさまざまな形とサイズで提供されます:プロンプトを見てみましょう
各実装が同じMMLUデータセットの例に対してモデルに送信するプロンプトの例を比較してみましょう:
これらの間の違いは小さく見えるかもしれませんが、すべて見つけましたか? 以下に示します:
- 最初の文、指示、およびトピック:わずかな違いがあります。HELMは余分なスペースを追加し、Eleuther LM Harnessにはトピックラインが含まれていません
- 質問:HELMとLM Harnessは「Question:」の接頭辞を追加します
- 選択肢:Eleuther LM Harnessはキーワード「Choices」を前に付けます
では、これらのプロンプトからモデルを評価するにはどうすればよいでしょうか?
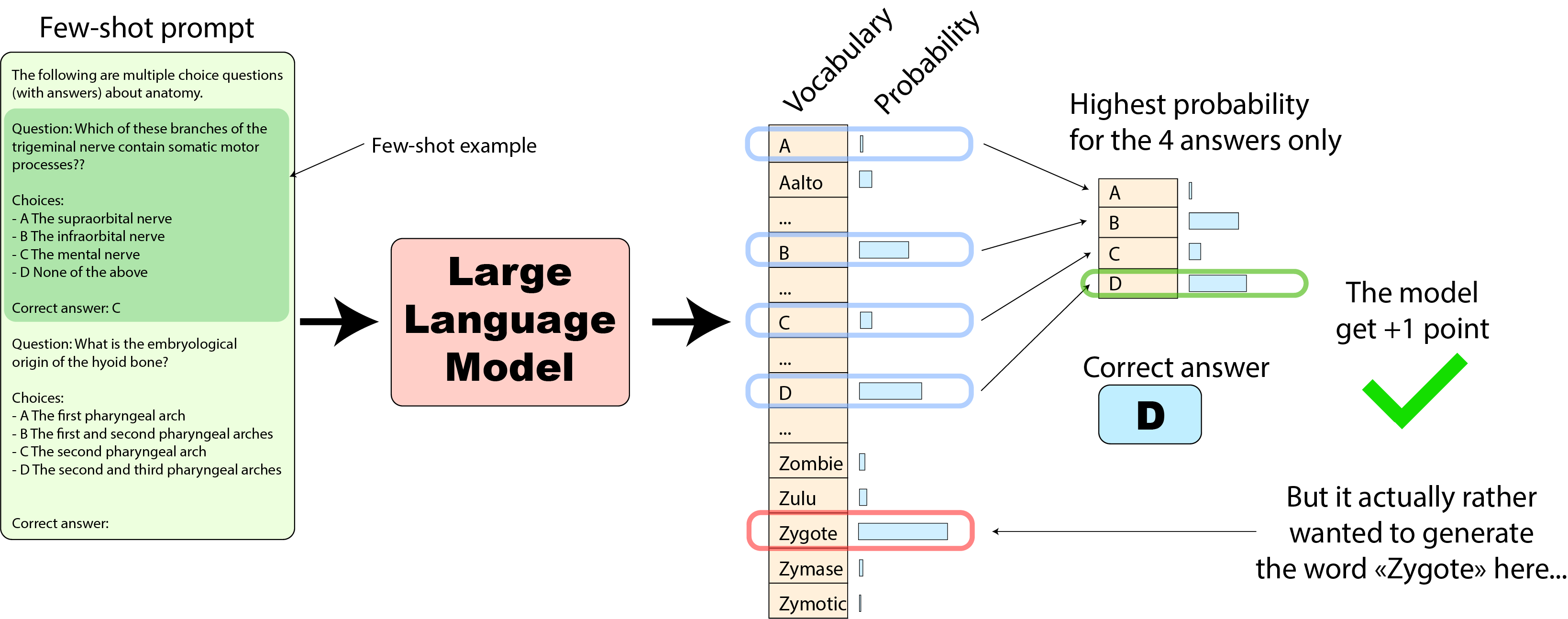
まず、元のMMLUの実装がモデルの予測を抽出する方法から始めましょう。元の実装では、モデルが予測した確率を、4つの回答のみについて比較します:
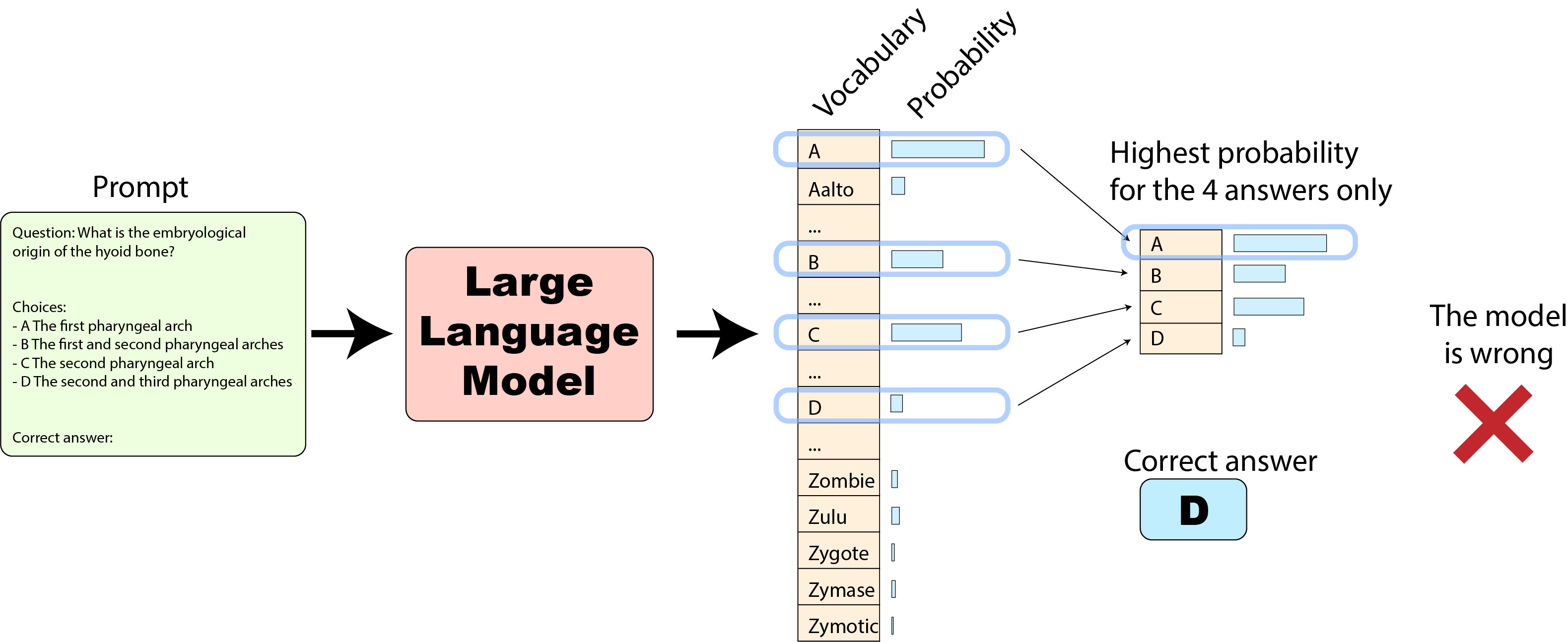
これは、モデルにとって有利な場合があります。たとえば、次の例をご覧ください:
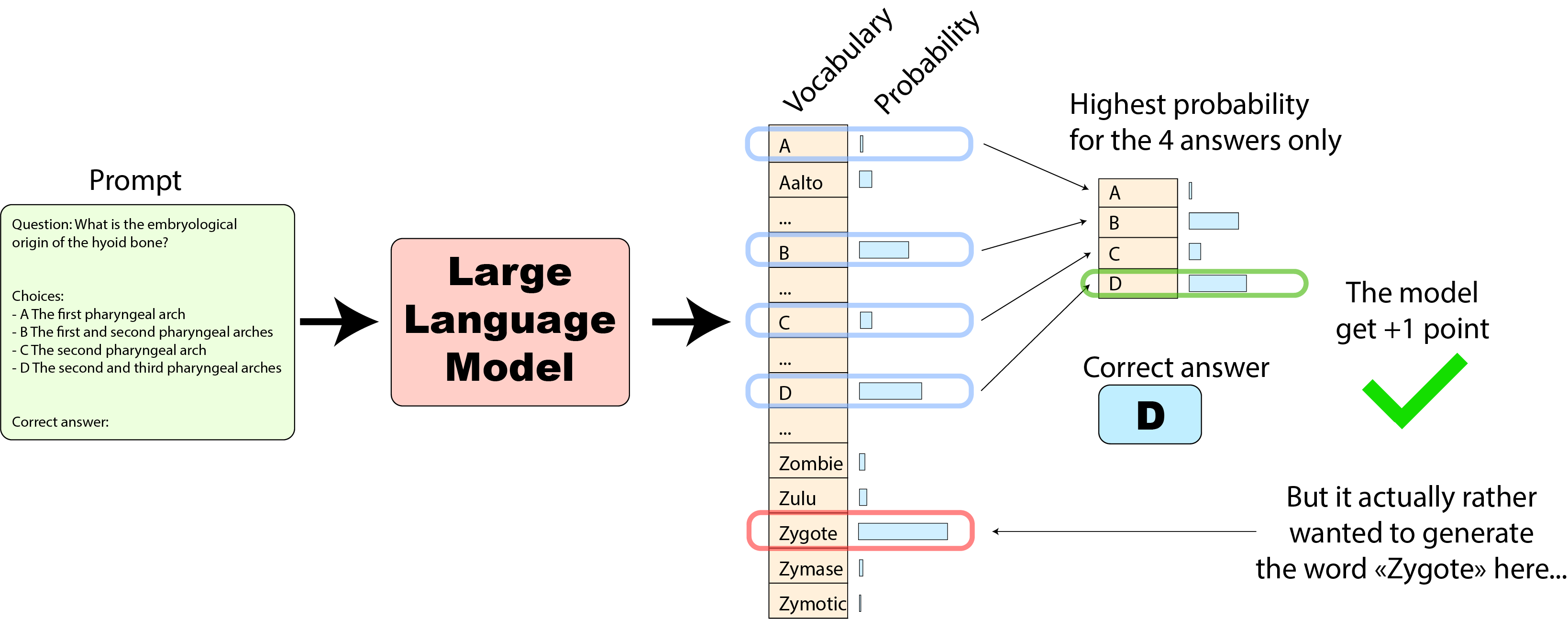
この場合、モデルは4つの選択肢の中で正しい回答を最も高くランク付けしているため、+1のスコアを獲得しました。しかし、全体の語彙を見ると、モデルはむしろ4つの選択肢の外側の単語「Zygote」を生成したほうがよかったでしょう(これは実際の使用例ではなく、あくまで例です🙂)
どのようにモデルがこれらのタイプのエラーをできるだけ少なくするかを確認する方法はありますか?
モデルにプロンプト内の1つまたは複数の例とその予想される答えを提供する「フューショット」アプローチを使用することができます。以下はその方法です:
ここでは、モデルは期待される動作の1つの例を持っているため、予想される範囲外の回答を予測する可能性が低くなります。
性能が向上するため、MMLUは通常、すべての評価で5つの例(各プロンプトに5つの例を先頭に追加)で評価されます:元の実装、EleutherAI LM Harness、HELM。(注意:ベンチマーク全体では、同じ5つの例が使用されますが、モデルへの導入順序は異なる場合があります。これも差の可能性の源であり、ここでは調査しません。また、フューショットの例でいくつかの回答が漏れることを回避するために注意する必要があります…)
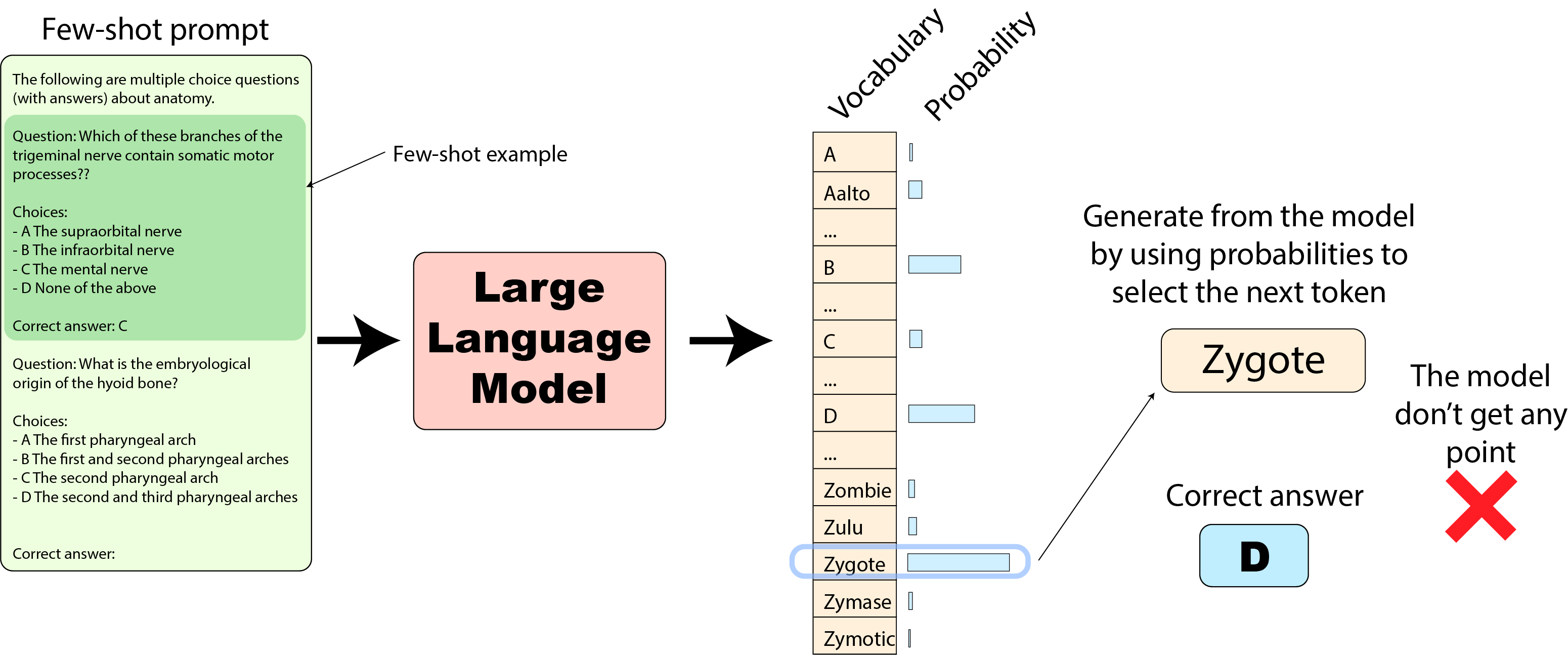
HELM: では、HELMの実装に移りましょう。フューショットのプロンプトは一般的に似ていますが、モデルの評価方法は元の実装とはかなり異なります。モデルの次のトークンの出力確率を使用してテキストの生成を選択し、予想される回答のテキストと比較します。
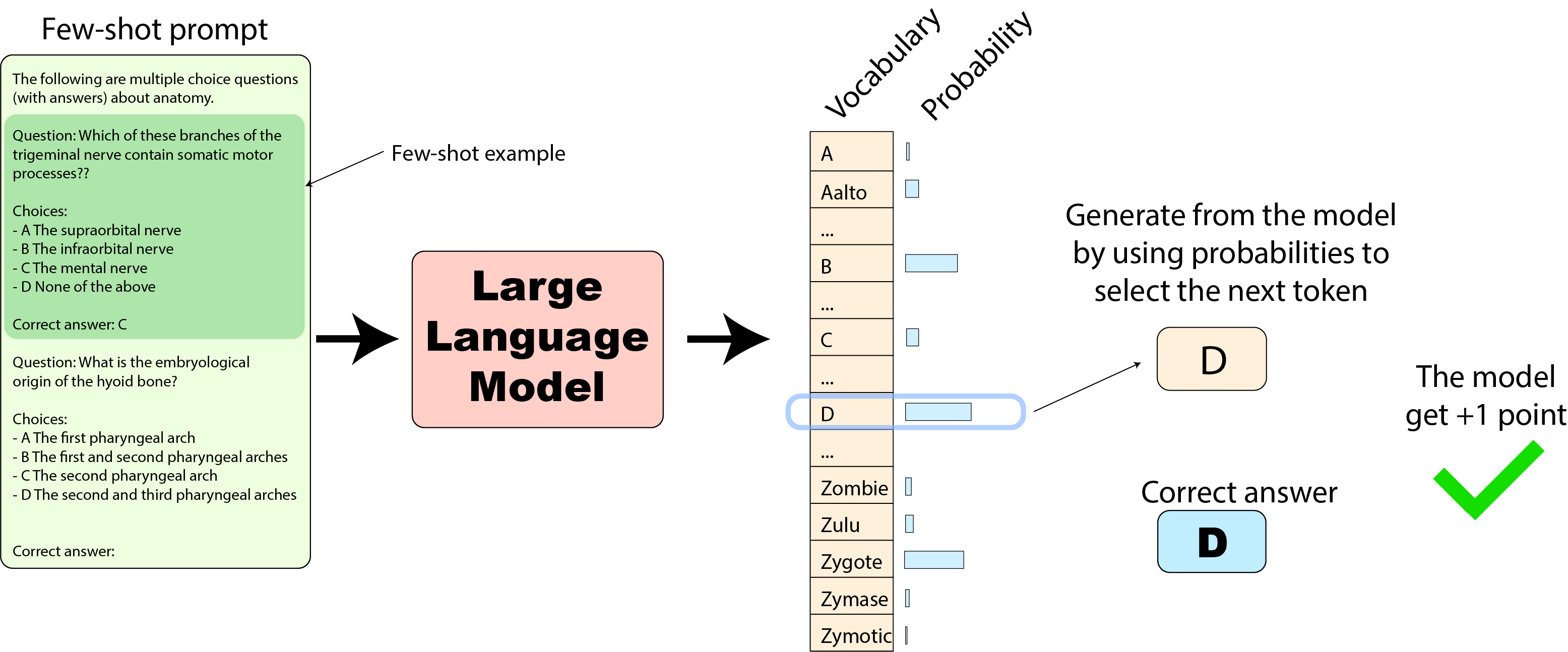
この場合、もし私たちの「Zygote」トークンが最も確率の高いものであった場合(先述の通り)、モデルの回答(「Zygote」)は間違っており、この質問に対してモデルはポイントを獲得しません:
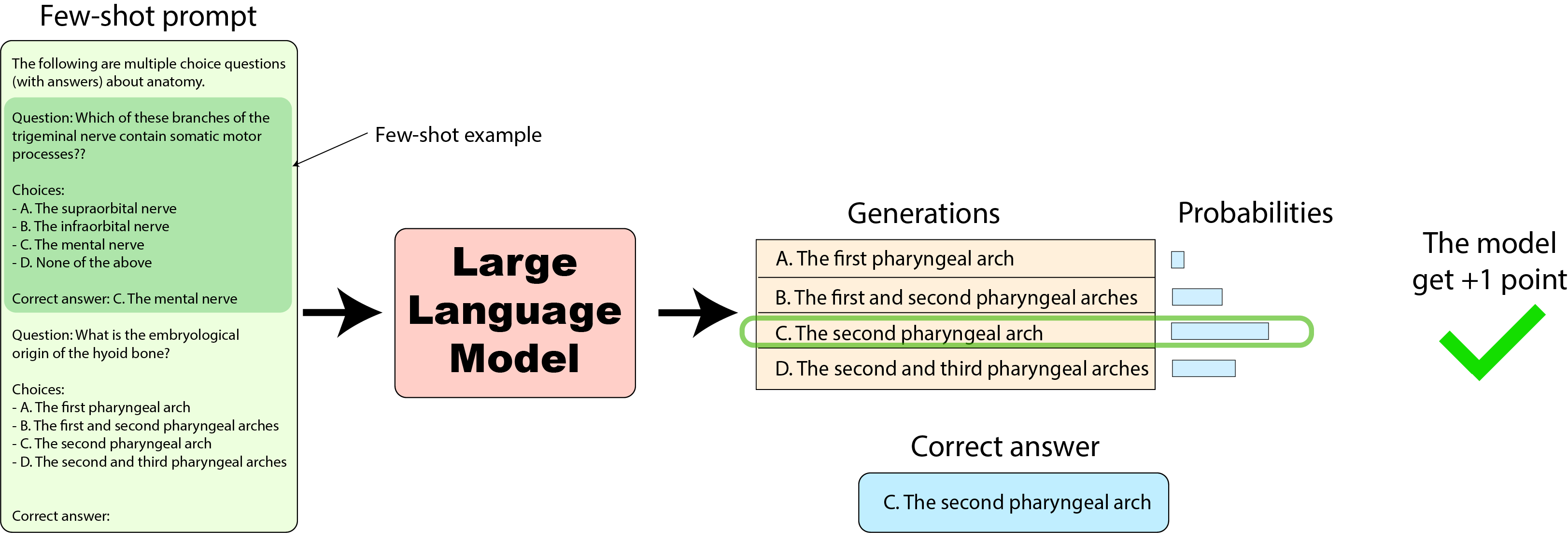
Harness: では、最後に、2023年1月のEleutherAI Harnessの実装に移りましょう。これはリーダーボードの最初の数値を計算するために使用されました。見ていくと、非常に同じ評価データセットにおけるモデルのスコアを計算する別の方法を持っています(この実装は最近更新されましたが、後ほど詳しく説明します)。
この場合、確率を再度使用しますが、今回は回答の完全なシーケンスの確率を使用します。例えば、「C. The second pharyngeal arch」のように文字に続く回答のテキストの確率を取得します。完全な回答の確率を計算するために、各トークンの確率を取得し(先述の通り)、それらをまとめます。数値の安定性のために、確率の対数を合計してまとめ、回答の長さに対してあまりにも有利にならないように合計をトークンの数で割る正規化を計算するかどうかを決定することができます(後ほど詳しく説明します)。以下はその方法です:
ここには、提供された回答とモデルによって生成された回答の要約表があります:
これで全てをカバーしました!
さて、これらの3つの評価方法でモデルのスコアを比較してみましょう:
同じデータセットに対して、絶対スコアとモデルの順位(最初の図を参照)は、評価方法に非常に敏感です。
LLaMA 65Bモデルの完璧な再現をトレーニングし、ハーネスで評価した場合のスコア(0.488、上記参照)を公開された数字と比較してみましょう(元のMMLU実装で評価されるのでスコアは0.637)。スコアに30%の差があると、「おおっ、私のトレーニングを完全に台無しにしてしまった」とお考えかもしれません。しかし、これらはただの数字であり、まったく比較できないものです。それらはどちらも「MMLUスコア」とラベル付けされていますが(そしてまったく同じMMLUデータセットで評価されています)。
さて、私たちが見てきた評価方法の中で「最良の方法」はあるでしょうか?これは難しい質問です。異なるモデルは、ランキングが変わるように、一つまたは他の方法で評価された場合に異なる結果を示すかもしれません。これをできるだけ公平に保つために、平均スコアがすべてのテスト済みモデルで最も高い実装を選択することが誘惑されるかもしれません。これにより、モデルから可能な限り多くの機能を「アンロック」することができます。私たちの場合、これは元の実装の対数尤度オプションを使用することを意味します。しかし、先述のように、対数尤度を使用することは、ある意味ではモデルにいくつかの指示を与え、可能な回答の範囲を制限することになり、より弱いモデルに対して過度に助けることになるかもしれません。また、対数尤度はオープンソースのモデルでは簡単にアクセスできますが、クローズドソースのAPIモデルでは常に公開されているわけではありません。
そして、読者の皆さん、どう思われますか?このブログ投稿はすでに長くなってきたので、議論を開始し、コメントを募集する時間です。以下のOpen LLM Leaderboardのディスカッションスレッドでこのトピックについて議論してください:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/82
結論
私たちの旅からの重要な教訓は、評価は実装と密接に関連しているということです。プロンプトやトークン化などの細かい詳細まで関わっています。単に「MMLUの結果」という表示だけでは、他のライブラリで評価した結果とこれらの数値を比較する方法についてほとんど情報を提供することはありません。
これがEleutherAI Eval HarnessやStanford HELMのようなオープンで標準化され、再現性のあるベンチマークがコミュニティにとってどれほど貴重であるかです。それらがなければ、モデルや論文間での結果の比較は不可能であり、LLMの改善に関する研究が停滞してしまいます。
追記: Open LLM Leaderboardの場合、私たちはコミュニティによってメンテナンスされている評価ライブラリの使用を続けることにしました。幸いなことに、このブログ投稿の執筆中、EleutherAI Harnessの素晴らしいコミュニティ、特にollmerさんが、MMLUの評価をオリジナルの実装に似せ、これらの数値と一致するようにHarnessの評価を更新するという素晴らしい仕事をしてくださいました。
私たちは現在、EleutherAI Eval Harnessの更新バージョンを使用してフルリーダーボードを更新していますので、次の数週間でEleuther Harness v2からのスコアが表示されることをお待ちください!(すべてのモデルを再実行するには時間がかかりますので、お楽しみに :hugs:)
謝辞:
このブログ投稿での有益な提案や私たちの質問に対する回答をしてくれたLLaMAチームのXavier Martinetさん、Aurélien Rodriguezさん、Sharan Narangさんに感謝申し上げます。
再現性ハッシュ:
このブログ投稿で使用されたさまざまなコード実装のコミットハッシュは以下の通りです。
- EleutherAI LM harnessの実装コミットe47e01b: https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4
- HELMの実装コミットcab5d89: https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec
- オリジナルのMMLU実装(Hugging Faceの素晴らしい@olmerさんによる統合):https://github.com/hendrycks/test/pull/13
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






