トランスフォーマーによるOCRフリーの文書データ抽出(2/2)
OCRフリーの文書データ抽出(2/2)
カスタムデータ上でのドーナツとPix2Structの比較
これらの2つのトランスフォーマーモデルは、ドキュメントをどれだけ理解できるのでしょうか?この第2部では、それらをトレーニングしてキーインデックスの抽出タスクの結果を比較します。
ドーナツの微調整
では、カスタムデータの準備方法を説明した第1部から始めましょう。データセットの2つのフォルダをZIP圧縮し、新しいハギングフェイスデータセットにアップロードしました。使用したコラボノートブックはこちらからダウンロードできます。データセットをダウンロードし、環境をセットアップし、ドーナツモデルをロードしてトレーニングします。
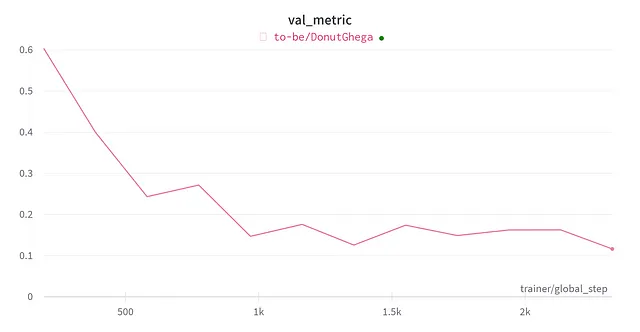
75分間の微調整後、検証メトリック(編集距離)が0.116に達した時点で停止しました:
フィールドレベルでは、検証セットに対して以下の結果が得られます:
- 「データサイエンスの観点からFCバルセロナのディフェンスを分析する」
- 「コンパートメント化拡散モデル(CDM) 異なるデータソース上で異なる拡散モデルまたはプロンプトをトレーニングするためのAIアプローチ」
- AdaTape 適応計算とダイナミックな読み書きを持つ基礎モデル
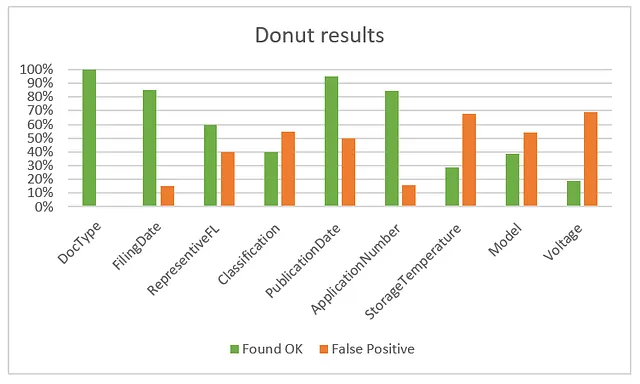
Doctypeを見ると、ドーナツは常に特許またはデータシートとしてドキュメントを正しく識別しています。したがって、分類は100%の正確さに達していると言えます。また、クラスがデータシートであるにもかかわらず、この正確な単語がドキュメントにある必要はありません。ドーナツにとっては、それをそのように認識するために微調整されているためです。
他のフィールドもかなり良いスコアですが、このグラフだけでは内部で何が起こっているかは分かりません。特定のケースでモデルが正しく認識しているかどうかを確認したいと思います。したがって、ノートブックにHTML形式のレポートテーブルを生成するルーチンを作成しました。検証セットの各ドキュメントには、次のような行エントリがあります:

左側には認識(推論)されたデータとその正解が表示されています。右側には画像があります。また、色コードも使用して、簡単に概要を把握できます:
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
