『広範な展望:NVIDIAの基調講演がAIの更なる進歩の道を指し示す』
NVIDIA's Keynote Speech Points the Way to Further Advances in AI
ハードウェア性能の劇的な向上により、生成型AIが生まれ、将来の高速化のアイデアの豊富なパイプラインが構築され、機械学習を新たな高みに導くでしょう。これについて、NVIDIAの最高科学者であり、研究担当のシニアバイスプレジデントであるビル・ダリー氏は、今日の基調講演で述べました。
ダリー氏は、プロセッサとシステムアーキテクトのための年次イベントであるHot Chipsでの講演で、すでに印象的な結果を示しているいくつかの手法について説明しました。
「AIの進歩は莫大であり、ハードウェアのおかげで可能になっていますが、まだ深層学習ハードウェアに制約を受けています」とダリー氏は述べ、世界有数のコンピュータ科学者であり、かつてスタンフォード大学のコンピュータ科学部の部長を務めた人物です。
彼は、例えば、数百万人に使用されている大規模言語モデル(LLM)であるChatGPTが、彼の講演のアウトラインを提案することができることを示しました。このような能力は、過去10年間のGPUによるAI推論性能の向上に大いに負うところがあると彼は述べました。
- 「この新しいAI研究は、事前学習されたタンパク質言語モデルを幾何学的深層学習ネットワークに統合することで、タンパク質構造解析を進化させます」
- スタンフォードの研究者たちは、DSPyを紹介します:言語モデル(LM)と検索モデル(RM)を用いた高度なタスクの解決のための人工知能(AI)フレームワーク
- 「ATLAS研究者は、教師なし機械学習を通じて異常検出を行い、新しい現象を探求しています」
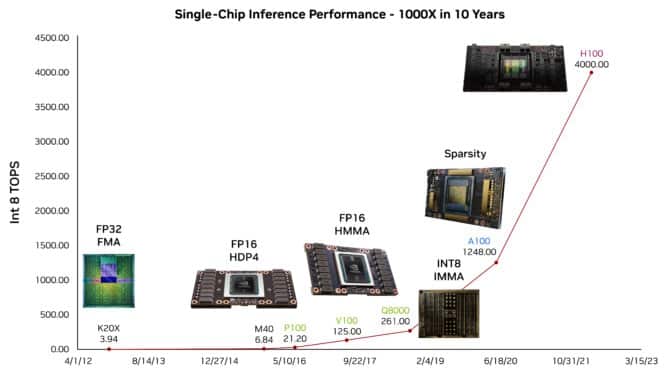
研究成果:100 TOPS/Wattを達成
研究者たちは、次の進歩に向けて準備を整えています。ダリー氏は、LLM上で1ワットあたりほぼ100テラオペレーションを実証したテストチップについて説明しました。
この実験では、生成型AIで使用されるトランスフォーマーモデルをさらに高速化する省エネの方法を示しました。これには、将来の進歩を約束するいくつかの簡略化された数値アプローチの1つである4ビット算術が適用されています。

さらにダリー氏は、対数的な数学を使用して計算を高速化し、エネルギーを節約する方法についても議論しました。これは、NVIDIAが2021年に特許を取得した手法です。
AI向けのハードウェアの最適化
彼は、AIタスクに合わせてハードウェアを最適化するための半ダースの他の手法を探求しました。これは、新しいデータ型や演算を定義することで実現されることが多いです。
ダリー氏は、ニューラルネットワークを簡素化する方法についても説明しました。NVIDIA A100 Tensor Core GPUで最初に採用された構造的疎結合という手法で、シナプスとニューロンを剪定します。
「スパース化に関してはまだ終わっていません」と彼は言いました。「アクティベーションに何かする必要があり、重みにもより大きなスパース化を行うことができます。」
彼はまた、研究者がハードウェアとソフトウェアを同時に設計する必要があると述べ、貴重なエネルギーをどこに使うかを慎重に決定する必要があると指摘しました。たとえば、メモリと通信回路はデータ移動を最小限に抑える必要があります。
「コンピュータエンジニアであることは楽しい時代です。AIにおけるこの巨大な革命を実現していますが、まだその革命がどれほど大きいかを完全に理解していないのです」とダリー氏は述べました。
より柔軟なネットワーク
別の講演では、NVIDIAのネットワーキング副社長であるケビン・ディアリング氏が、NVIDIA BlueField DPUsとNVIDIA Spectrumネットワーキングスイッチのユニークな柔軟性について説明しました。これにより、ネットワークトラフィックやユーザールールの変更に基づいてリソースを割り当てることができます。
これらのチップは、ハードウェアアクセラレーションパイプラインを秒単位で動的に切り替えることができるため、最大限のスループットで負荷分散を実現し、コアネットワークに新しい適応性をもたらします。これは、サイバーセキュリティの脅威に対抗するのに特に有用です。
「現在の生成型AIのワークロードやサイバーセキュリティでは、すべてが動的で、常に変化しています」とディアリング氏は述べました。「したがって、ランタイムのプログラム可能性と、フライで変更できるリソースに移行しています。」
さらに、NVIDIAとライス大学の研究者は、人気のあるP4プログラミング言語を使用して、ユーザーがランタイムの柔軟性を活用する方法を開発しています。
GraceがサーバーCPUをリード
ArmによるNeoverse V2コアに関する講演では、NVIDIA Grace CPU Superchipのパフォーマンスについての最新情報が含まれています。これは、それらを実装した最初のプロセッサです。
テストによると、同じ電力の条件下で、GraceシステムはさまざまなCPUワークロードにおいて、現行のx86サーバーのスループットを最大2倍向上させることができます。さらに、ArmのSystemReadyプログラムにより、Graceシステムは既存のArmオペレーティングシステム、コンテナ、およびアプリケーションを変更せずに実行できることが認定されています。
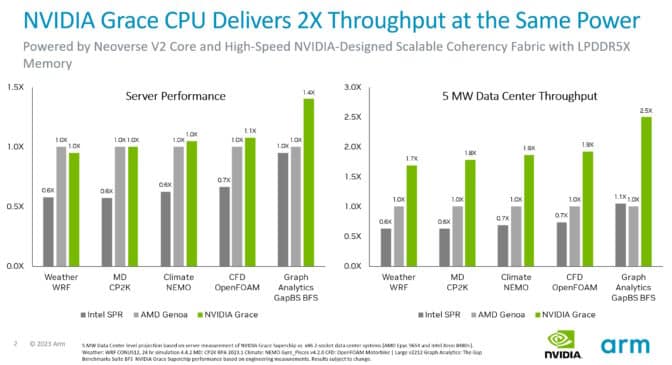
Graceは、シングルダイ内に72のArm Neoverse V2コアを接続するための超高速ファブリックを使用し、それらのダイを2つのパッケージで接続するNVLinkのバージョンを使用して、900 GB/sの帯域幅を提供します。これは、サーバークラスのLPDDR5Xメモリを使用する最初のデータセンターCPUであり、似たコストでメモリ帯域幅を50%増加させながら、通常のサーバーメモリの1/8の電力を使用します。
Hot Chipsは8月27日にAIの推論やチップ間接続のプロトコルについてのNVIDIAの専門家による講演を含むチュートリアルの一日をもってスタートし、今日まで続きます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「大規模な言語モデルは、多肢選択問題の選択の順序に敏感なのか」という新しいAI研究に答える
- CMU(カーネギーメロン大学)と清華大学の研究者が提案した「Prompt2Model:自然言語の指示から展開可能なAIモデルを生成する汎用メソッド」
- ETHチューリッヒの研究者が、大規模な言語モデル(LLM)のプロンプティング能力を向上させるマシンラーニングフレームワークであるGoT(Graph of Thoughts)を紹介しました
- UCSFとUC Berkeleyの研究者たちは、脳幹の脳卒中による重度の麻痺を持つ女性がデジタルアバターを通じて話すことができるようにする脳-コンピューターインタフェース(BCI)を開発しました
- DeepMindの研究者が、成長するバッチ強化学習(RL)に触発されて、人間の好みに合わせたLLMを整列させるためのシンプルなアルゴリズムであるReinforced Self-Training(ReST)を提案しました
- 「研究によると、YouTube広告が子どもたちのオンライン追跡を引き起こした可能性がある」と言われています
- 「MITの研究者たちは、人工知能(AI)の技術を開発しましたこの技術により、ロボットは手全体を使ってオブジェクトを操作するための複雑な計画を立てることが可能になります」





