「NVIDIAのグレース・ホッパー・スーパーチップがMLPerfの推論ベンチマークを席巻する」
NVIDIAのグレース・ホッパー・スーパーチップがMLPerfの推論ベンチマークを席巻する
MLPerf業界ベンチマークに初登場したNVIDIA GH200 Grace Hopperスーパーチップは、すべてのデータセンターインファレンステストを実行し、NVIDIA H100 Tensor Core GPUのリーディングパフォーマンスを拡張しました。
全体的な結果は、NVIDIA AIプラットフォームの卓越したパフォーマンスと多機能性を示しており、クラウドからネットワークのエッジまでの幅広い領域で活躍しています。
別途、NVIDIAは性能、エネルギー効率、総所有コストの向上をユーザーにもたらすインファレンスソフトウェアを発表しました。
GH200スーパーチップがMLPerfで輝く
GH200は、Hopper GPUとGrace CPUを1つのスーパーチップに結合しています。この組み合わせにより、より多くのメモリ、帯域幅、およびCPUとGPUの間で自動的に電力を切り替えてパフォーマンスを最適化する能力が提供されます。
また、8つのH100 GPUを搭載したNVIDIA HGX H100システムは、今回のMLPerfインファレンステストのすべての項目で最も高いスループットを実現しました。
Grace HopperスーパーチップとH100 GPUは、コンピュータビジョン、音声認識、医療画像などのMLPerfのデータセンターテスト全般でリードし、推薦システムや生成AIにおける大規模言語モデル(LLM)など、より要求の厳しいユースケースでも優れたパフォーマンスを発揮しました。
全体的に、これらの結果は、2018年のMLPerfベンチマークの開始以来、NVIDIAがAIトレーニングとインファレンスのパフォーマンスリーダーシップを証明し続ける記録を続けています。
最新のMLPerfラウンドでは、推薦システムのテストが更新され、AIモデルのサイズの大まかな指標である6兆パラメータを持つGPT-Jの最初のインファレンスベンチマークが実施されました。
TensorRT-LLMがインファレンスを強化
NVIDIAは、推論を最適化する生成AIソフトウェアであるTensorRT-LLMを開発しました。このオープンソースライブラリは、MLPerfへの8月の提出に間に合わなかったものの、既に購入済みのH100 GPUのインファレンスパフォーマンスを追加費用なしで2倍以上向上させることができます。
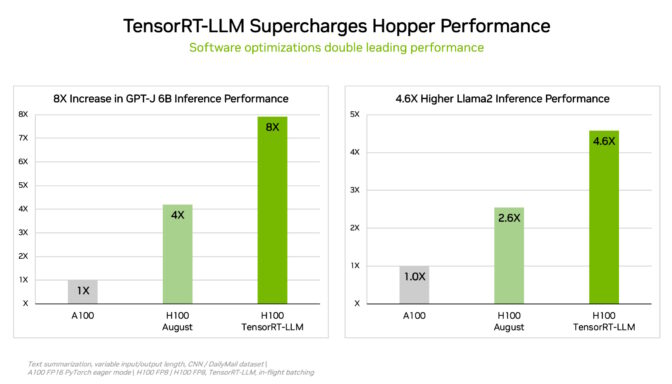
NVIDIAの内部テストでは、TensorRT-LLMをH100 GPUで使用すると、ソフトウェアなしでGPT-J 6Bを実行する前世代のGPUと比較して最大8倍のパフォーマンス向上が得られることが示されています。
このソフトウェアは、Meta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(現在はDatabricksの一部)、OctoML、Tabnine、Together AIなどの主要企業と共同でLLMの推論を加速し、最適化するためのNVIDIAの取り組みから始まりました。
MosaicMLは、TensorRT-LLMの上に必要な機能を追加し、既存のサービングスタックに統合しました。「使いやすく、機能が充実し、効率的です」とDatabricksのエンジニアリング担当副社長であるNaveen Raoは述べています。「NVIDIAのGPUを使用したLLMサービングにおいて最先端のパフォーマンスを提供し、お客様へのコスト削減を可能にします」とRao氏は述べています。
TensorRT-LLMは、NVIDIAのフルスタックAIプラットフォームにおける継続的なイノベーションの最新の例です。これらの継続的なソフトウェアの進歩により、ユーザーは追加費用なしで時間とともに成長するパフォーマンスを得ることができ、多様なAIワークロードに対応できます。
L4がメインストリームサーバーにおけるインファレンスを向上
最新のMLPerfベンチマークでは、NVIDIAのL4 GPUがあらゆるワークロードを実行し、全体的に優れたパフォーマンスを発揮しました。
たとえば、72WのコンパクトなPCIeアクセラレータで実行されるL4 GPUは、ほぼ5倍の消費電力に評価されるCPUよりも最大6倍のパフォーマンスを実現しました。
さらに、L4 GPUにはCUDAソフトウェアと組み合わせて、NVIDIAのテストにおいてコンピュータビジョンに対して最大120倍の高速化を提供する専用のメディアエンジンが搭載されています。
L4 GPUはGoogle Cloudや多くのシステムビルダーから利用可能であり、消費者インターネットサービスから医薬品発見までのさまざまな産業の顧客にサービスを提供しています。
エッジでのパフォーマンス向上
別途、NVIDIAは新しいモデル圧縮技術を適用し、L4 GPU上でBERT LLMを実行することで最大4.7倍のパフォーマンス向上を実現しました。この結果は、新しい機能を紹介するためのMLPerfの「オープンディビジョン」と呼ばれるカテゴリーでのものです。
この技術は、すべてのAIワークロードで利用されることが期待されています。特に、サイズと消費電力の制約があるエッジデバイスでモデルを実行する場合に特に有用です。
エッジコンピューティングにおけるリーダーシップの別の例として、NVIDIA Jetson Orinシステムオンモジュールは、オブジェクト検出というエッジAIやロボティクスシナリオで一般的なコンピュータビジョンにおいて、前回のラウンドに比べ最大84%のパフォーマンス向上を示しました。
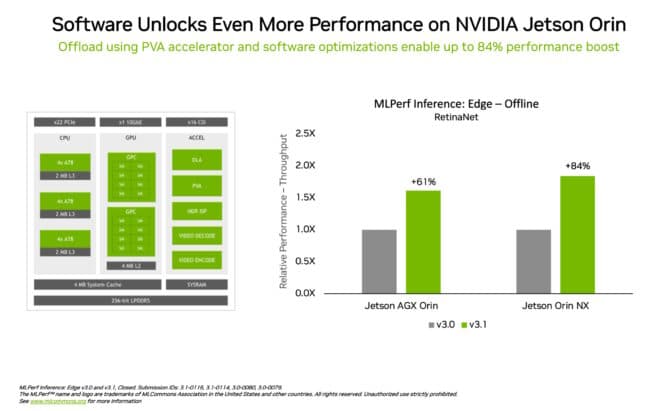
Jetson Orinの進化は、最新バージョンのチップのコアを活用したソフトウェアによってもたらされました。これには、プログラマブルなビジョンアクセラレータ、NVIDIA AmpereアーキテクチャのGPU、そして専用のディープラーニングアクセラレータが含まれます。
多目的なパフォーマンス、広範なエコシステム
MLPerfベンチマークは透明性があり客観的ですので、結果に基づいて購買決定を行うことができます。また、さまざまなユースケースとシナリオをカバーしているため、信頼性のあるパフォーマンスと展開の柔軟性を得ることができます。
今回の提出パートナーには、クラウドサービスプロバイダのMicrosoft AzureとOracle Cloud Infrastructure、システムメーカーのASUS、Connect Tech、Dell Technologies、Fujitsu、GIGABYTE、Hewlett Packard Enterprise、Lenovo、QCT、Supermicroが含まれています。
MLPerfは、Alibaba、Arm、Cisco、Google、Harvard University、Intel、Meta、Microsoft、University of Torontoを含む70以上の組織によって支持されています。
最新の結果を達成するためにNVIDIAがどのようにしているかの詳細については、技術ブログをご覧ください。
NVIDIAのベンチマークで使用されるすべてのソフトウェアは、MLPerfリポジトリから入手可能ですので、誰もが同じ世界クラスの結果を得ることができます。最適化は、GPUアプリケーションのためのNVIDIA NGCソフトウェアハブで利用可能なコンテナに継続的に組み込まれています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Flash-AttentionとFlash-Attention-2の理解:言語モデルの文脈長を拡大するための道」
- 4/9から10/9までの週のためのトップ重要なコンピュータビジョンの論文
- ディープラーニングを使用した自動音楽生成
- 「ゼロからヒーローへ:PyTorchで最初のMLモデルを作ろう」
- 「Verbaに会ってください:自分自身のRAG検索増強生成パイプラインを構築し、LLMを内部ベースの出力に活用するためのオープンソースツール」
- 高性能意思決定のためのRLHF:戦略と最適化
- 「ResFieldsをご紹介します:長くて複雑な時間信号を効果的にモデリングするために、時空間ニューラルフィールドの制約を克服する革新的なAIアプローチ」






