「NTUシンガポールの研究者がResShiftを導入:他の手法と比較して、残差シフトを使用し、画像超解像度をより速く実現する新しいアップスケーラモデル」
NTU Singapore researchers introduce ResShift a new upscaler model that achieves image super-resolution faster using residual shift compared to other methods.


低レベルビジョンの基本的な課題の1つは、画像のスーパーレゾリューション(SR)であり、低解像度(LR)の画像から高解像度(HR)の画像を復元することを目指しています。実世界の環境での劣化モデルの複雑さと不明瞭さのため、この問題は解決される必要があります。最近開発された生成モデルである拡散モデルは、画像の作成において非凡な成功を収めています。また、画像編集、画像補完、画像着色など、いくつかの下流の低レベルビジョンの問題にも有望な成果を示しています。さらに、困難で時間のかかるSRの作業に対して拡散モデルがどれだけうまく機能するかを調べるための研究がなされています。
典型的な手法の1つは、現在の拡散モデル(例:DDPM)の入力にLR画像を導入した後、SRのためのトレーニングデータを使用してモデルをゼロから再トレーニングすることです。もう1つの一般的な手法は、目的のHR画像を生成する前に、無条件の事前トレーニング済みの拡散モデルの逆経路を変更することです。残念ながら、これらのアルゴリズムの両方には、DDPMを基盤とするマルコフ連鎖が継承されています。図1の推論を高速化するためにDDIMアルゴリズムが使用されていますが、推論中のサンプルステップを圧縮するためのいくつかの加速手法が考案されています。これらの手法は、パフォーマンスのかなりの低下と過度に滑らかな結果につながることがしばしばあります。
効率とパフォーマンスの両方を損なうことなく、SRのための新しい拡散モデルを作成する必要があります。画像作成のための拡散モデルを見直してみましょう。前進のプロセスでは、マルコフ連鎖が多くのステップで構築され、観測データが事前に指定された分布(通常は従来のガウス分布)に徐々に変換されます。次に、事前分布からノイズマップをサンプリングし、マルコフ連鎖の逆経路に供給することで、画像を生成することができます。ガウス分布は画像生成には適していますが、LR画像が既に利用可能なため、SRには最適な選択肢ではないかもしれません。
- UCバークレーの研究者たちは、ビデオ予測報酬(VIPER)というアルゴリズムを紹介しましたこれは、強化学習のためのアクションフリーの報酬信号として事前学習されたビデオ予測モデルを活用しています
- 「このAI研究は、合成的なタスクにおけるTransformer Large Language Models(LLMs)の制限と能力を、経験的および理論的に探求します」
- 「Pythia 詳細な研究のための16個のLLMスイート」

この研究での主張によれば、SRの適切な拡散モデルは、ガウスのホワイトノイズではなく、LR画像を基にした事前分布から始めるべきであり、LR画像からHR画像を反復的に復元することが可能です。このような設計は、サンプリングに必要な拡散ステップの数を削減し、推論の効率を高めることもできます。南洋理工大学の研究者たちは、HR画像とそれに相当するLR画像の間を切り替えるために、より短いマルコフ連鎖を使用する効果的な拡散モデルを提案しています。マルコフ連鎖の初期状態はHR画像の分布を近似し、終端状態はLR画像の分布を近似します。
彼らは丁寧にトランジションカーネルを作成し、それらの間の残差を徐々に調整するために使用しています。残差情報はいくつかの段階で迅速に伝達することができるため、この技術は現在の拡散ベースのSR手法よりも効果的です。さらに、彼らのアーキテクチャは、訓練の最適化目標の導出を簡素化するために、証拠下限を明確で分析的な方法で表現することが可能です。彼らはこの構築された拡散カーネルに基づく非常に柔軟なノイズスケジュールを作成し、残差の移動速度と各ステップのノイズレベルを調整します。
ハイパーパラメータを調整することで、このスケジュールは取得した結果の忠実度と現実性のトレードオフを可能にします。以下に、この研究の重要な貢献を示します:
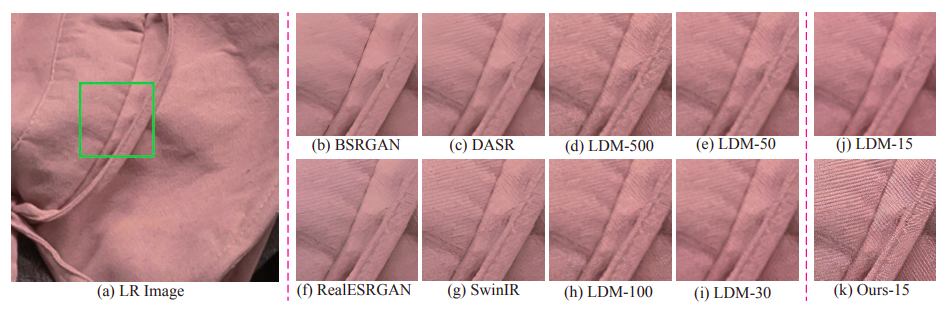
• 彼らはSRに対して効果的な拡散モデルを提供しており、推論時に2つの間の残差を移動することで、望ましくないLR画像から望ましいHR画像への反復サンプリングプロセスを可能にします。詳細な研究により、彼らの手法の効率性が示されています。望ましい結果を得るためにわずか15の簡単なステップしか必要とせず、長時間のサンプリング手法が必要な既存の拡散ベースのSR技術を上回るか、少なくとも同等の結果を示します。図1は、既存の技術と比較した彼らの取得した結果の一部を示しています。
• 提案された拡散モデルに対して、より正確な制御を可能にする高度に可変なノイズスケジュールを開発しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「新しいAI研究が、PanGu-Coder2モデルとRRTFフレームワークを提案し、コード生成のための事前学習済み大規模言語モデルを効果的に向上させる」というものです
- 「AIと脳インプラントにより、麻痺した男性の運動と感覚が回復する」
- UCバークレーの研究者が、Neural Radiance Field(NeRF)の開発に利用できるPythonフレームワーク「Nerfstudio」を紹介しました
- AIを使用してAI画像の改ざんを防ぐ
- 「NYUとMeta AIの研究者は、ユーザーと展開されたモデルの間の自然な対話から学習し、追加の注釈なしで社会的な対話エージェントの改善を研究しています」
- 中国からの新しいAI研究が提案するSHIP:既存のファインチューニング手法を改善するためのプラグアンドプレイの生成AIアプローチ
- ETHチューリッヒの研究者たちは、LMQLという言語モデルとの相互作用のためのプログラミング言語を紹介しました






