「NTU SingaporeのこのAI論文は、モーション表現を用いたビデオセグメンテーションのための大規模ベンチマーク、MeVISを紹介しています」
NTU Singapore introduces MeVIS, a large-scale benchmark for video segmentation using motion representation.


言語にガイドされたビデオセグメンテーションは、自然言語の記述を使用してビデオ内の特定のオブジェクトをセグメント化およびトラッキングすることに焦点を当てた発展途上の領域です。ビデオオブジェクトを参照するための現行のデータセットは通常、目立つオブジェクトに重点を置き、多くの静的属性を持つ言語表現に依存しています。これらの属性により、対象のオブジェクトを単一のフレームで特定することができます。しかし、これらのデータセットは、言語にガイドされたビデオオブジェクトセグメンテーションにおける動きの重要性を見落としています。

研究者は、私たちの調査を支援するために、Motion Expression Video Segmentation(MeViS)と呼ばれる新しい大規模データセットであるMeVISを紹介しました。 MeViSデータセットは2,006のビデオ、8,171のオブジェクト、および28,570のモーション表現で構成されています。上記の画像は、MeViSの表現を表示しており、これらの表現は主にモーションの属性に焦点を当てており、単一のフレームだけで対象のオブジェクトを特定することはできません。たとえば、最初の例では似たような外観を持つ3羽のオウムが特徴であり、対象のオブジェクトは「飛び去る鳥」と特定されます。このオブジェクトは、ビデオ全体のモーションをキャプチャすることでのみ認識できます。
MeVISデータセットがビデオの時間的なモーションに重点を置くようにするために、いくつかの手順があります。
- 『周期的な時間特徴のエンコード方法』
- 「Googleは、Raspberry Pi向けにMediaPipeを導入し、デバイス内の機械学習のための使いやすいPython SDKを提供します」
- 人工知能の台頭に備えるために、高校生をどのようにサポートできるか
まず、静的属性だけで説明できる孤立したオブジェクトを持つビデオを除外し、モーションと共存する複数のオブジェクトを含むビデオコンテンツを注意深く選択します。
次に、ターゲットオブジェクトをモーションの単語のみで曖昧さなく説明できる場合、カテゴリ名やオブジェクトの色などの静的な手がかりを含まない言語表現を優先します。
MeViSデータセットの提案に加えて、研究者はこのデータセットがもたらす課題に対処するためのベースラインアプローチであるLanguage-guided Motion Perception and Matching(LMPM)を提案しています。彼らのアプローチでは、言語によるクエリの生成を行い、ビデオ内の潜在的な対象オブジェクトを識別します。これらのオブジェクトはオブジェクト埋め込みを使用して表現され、オブジェクトの特徴マップと比較してより堅牢で計算効率の良いものです。研究者はこれらのオブジェクト埋め込みに対してMotion Perceptionを適用し、ビデオのモーションダイナミクスの時間的な文脈を捉え、ビデオ内の瞬間的なモーションと持続的なモーションの両方を把握することができます。
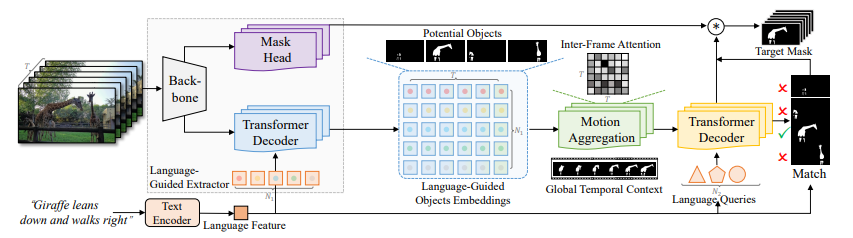
上記の画像はLMLPのアーキテクチャを表示しています。彼らはTransformerデコーダを使用して、モーションに影響を受けた組み合わせられたオブジェクト埋め込みから言語を解釈し、オブジェクトの移動を予測するのに役立ちます。それから、言語特徴を投影されたオブジェクトの動きと比較して、表現で言及されるターゲットオブジェクトを見つけます。この革新的な方法は、言語理解とモーション評価を統合して、複雑なデータセットの課題を効果的に処理します。
この研究は、より高度な言語にガイドされたビデオセグメンテーションアルゴリズムの開発の基盤を提供しました。さらに、以下のようなより困難な方向に向けた道を開拓しました。
- 視覚的および言語的モダリティにおけるより良いモーション理解とモデリングのための新しい技術の探索。
- 冗長な検出されたオブジェクトの数を減らすより効率的なモデルの作成。
- 言語と視覚信号の相補的な情報を活用するための効果的なクロスモーダル融合手法の設計。
- 複数のオブジェクトと表現がある複雑なシーンを処理できる高度なモデルの開発。
これらの課題に取り組むには、言語によるビデオセグメンテーションの現在の最先端を推進するための研究が必要です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




