NODE:表形式に特化したニューラルツリー
NODE A neural tree specialized in tabular form.
NODEの探索:表形式データのためのニューラル決定木アーキテクチャの探求
近年、機械学習は人気を爆発させ、ニューラルディープラーニングモデルは画像やテキスト処理などの複雑なタスクにおいて、XGBoost[4]のような浅いモデルを圧倒してきました。しかし、ディープモデルはしばしば、表形式データに関してはこれらの浅いモデルよりも効果が低く、決定木を勾配ブースティングする手法においても、一貫して優れたディープラーニングアプローチはありません。
このギャップを埋めるために、ロシアのインターネットサービス会社であるYandexの研究者たちは、新しいアーキテクチャ「Neural Oblivious Decision Ensembles(NODE)」[1]を提案しました。このネットワークは、軽量で解釈可能なニューラル決定木を活用し、それらをニューラルネットワークのフレームワーク内に統合します。これにより、モデルは表形式データにおける複雑な相互作用や依存関係を捉えることができる一方で、解釈性を維持することができます。
この記事では、NODEの仕組みや、堅牢でありながら解釈可能な予測モデルとなるさまざまな特徴について説明します。いつものように、オリジナルの論文を読むことをおすすめします。もしNODEを使用したい場合は、モデルのGitHubをチェックしてください。
この記事は、高い説明力を持ち、伝統的なディープネットワークと同等の予測力を提供するニューラル決定木に関するシリーズの一部です。
- 小さな言語モデルでも高い性能を発揮できるのか?StableLMに会ってみてください:適切なトレーニングで高性能なテキストとコードを生成できるオープンソースの言語モデル
- 大規模言語モデル(LLM)とは何ですか?LLMの応用と種類
- 人工知能の未来を形作る:進歩と革新のための迅速なエンジニアリングの重要性

Nakul Upadhya
ソフト/ニューラル決定木
リスト2つのストーリーを表示する

NODE決定木の構造
ニューラル決定木
この記事では、ニューラル決定木についてある程度の知識を前提としています。もし知識がない場合は、詳細な説明のために以前の記事を読むことを強くお勧めします。しかし、要約すると、ニューラル決定木はソフトで斜めな決定木です。
斜めの木は、各ノードで複数の変数を使用して決定を行う木です(通常は線形組み合わせで配置されます)。例えば、車の事故を予測するために、直交する木は「car_speed – speed_limit < 10」というルールを使用して分岐の決定をします。これは、「直交する」木であるCART(基本的な決定木)とは異なり、任意のノードで1つの変数しか使用せず、同じ決定境界を近似するためにより多くのノードが必要になります。
ソフト木は、すべての分岐の決定が確率的であり、各ノードでの計算が特定の枝に入る確率を定義します。これは、通常の「ハード」な決定木であるCARTとは異なり、各分岐の決定が確定的であるという点です。
木は各ノードで使用する変数の数を制限せず、分岐の決定は連続的であるため、全体の木が微分可能です。木全体が微分可能であるため、PytorchやTensorflowなどの任意のニューラルネットワークフレームワークに統合し、従来のニューラル最適化手法(例:確率的勾配降下法やAdam)を使用して学習することができます。
NODE木
NODEが使用する決定木は、従来のニューラルツリーとは若干異なります。すべての違いを解説しましょう。
忘却性の特性
最初の重要な変更点は、木が忘却性であるということです。つまり、同じ深さのすべての内部ノードで、木は同じ分割の重みと閾値を使用します。その結果、忘却性決定木(ODT)は、エントリーが2^ d個(dは深さを表す)の決定表として表現することができます。その利点は、ODTが従来の決定木よりも解釈可能であることです。解釈する必要がある決定が少なくなるため、決定経路を視覚化して理解することが容易になります。ただし、ODTは従来の決定木と比較して学習能力が著しく低下します(再び、分割関数の制約のためです)。
したがって、パフォーマンスが目標である場合、なぜODTを使用するのでしょうか? CATBoost [2]の開発者が示したように、ODTはアンサンブルとして非常に優れた機能を持ち、データの過学習のリスクが低いです。また、ODTの推論は非常に効率的です。スプリットはすべて並列に計算され、テーブル内の適切なエントリを迅速に見つけることができます。
特徴選択と分岐のためのEntmax
NODEが伝統的なニューラル意思決定木に対して行った2番目の改善は、そのアーキテクチャにおけるシグモイドの代わりにアルファエントマックス[3]の使用です。アルファエントマックスは、ほとんどの結果がゼロに等しい疎な分布を生成できるソフトマックスの一般化バージョンです。この疎さは、パラメータ(アルファであり、そのため名前が付けられています)によって制御されます。アルファが大きいほど、分布はより疎になります。
![Peters et al. 2019 [3]の図](https://miro.medium.com/v2/resize:fit:640/format:webp/0*F_Ar1Nyc6BxnVXsP.png)
この変換は2つの主要な場所で使用されます。最初の使用は疎な特徴選択です。NODEには訓練可能な特徴選択重み行列F(サイズがd x nで、nは特徴の数であり、dは木の深さです)が含まれており、エントマックス変換を経て渡されます。エントマックス変換のほとんどのエントリがゼロに等しいため、これにより各意思決定ノードで使用される特徴の数が自然に少なくなります。
![分岐関数(Popov et al. 2019 [1]の図)](https://miro.medium.com/v2/resize:fit:640/format:webp/1*hCu6EpU9LVxeHL2cLN6UVQ.png)
特徴選択に加えて、エントマックスは分岐確率にも使用されます。これは、分岐関数の結果を渡し、学習された閾値を引き、適切にスケーリングした後に行われます。この値は0と連結され、エントマックス関数に渡されて2クラスの確率分布を作成します。これが分岐に必要な正確に必要なものです。
![分岐式([1]からのもの)。b_iは分岐閾値、tau_iはデータをスケーリングするための学習された値(著者による図)](https://miro.medium.com/v2/resize:fit:640/format:webp/0*bWVGEq4eXFEVWwa3.png)
これを使用すると、すべての分岐分布cの外積を計算して「選択」テンソルCを定義することができます。これは、リーフの値と乗算することでネットワークの結果を作成するためです。
アンサンブル
名前が示すように、これらのNeural Oblivious Decision Treesはアンサンブルされます。NODEレイヤーは、個々のツリーが連結され、それぞれが独自の分岐決定とリーフ値を持つ連結として定義されます。前述のように、このアンサンブルは個々のツリーの無関心な性質と相乗効果を持ち、過学習のリスクを減らして精度を向上させるのに役立ちます。
Multi-layer NODE
NODEは、単独で訓練することも(意思決定ツリーの単一のアンサンブルを結果として生成する)複雑なマルチレイヤー構造で訓練することもできる柔軟なアーキテクチャです。各アンサンブルセットは前のレイヤーからの入力を受け取ります。
![Multilayer NODE Architecture (Figure from Popov et al. 2019 [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WyQVp9Dg6JygVcKTPtYtAg.png)
NODEの多層アーキテクチャは、人気のあるDenseNetアーキテクチャに密接に従います。各NODEレイヤーには、複数のツリーが含まれており、出力は連結され、後続のレイヤーの入力となります。最終的な出力は、すべてのレイヤーのすべてのツリーの出力の平均値を求めることで得られます。各レイヤーは、すべての前の予測のチェーンに依存しているため、ネットワークは複雑な依存関係を捉えることができます。
実験的なパフォーマンス
Popov et al. (2019)は、NODEをCatBoost [2]、XGBoost [4]、完全に接続されたニューラルネットワーク、mGBDT [5]、DeepForest [6]と比較するために、6つの異なるデータセットでモデルをテストしました。具体的には、各モデルのデフォルトパラメータを使用した比較と、各モデルのチューニングされたハイパーパラメータを使用した比較を行いました。
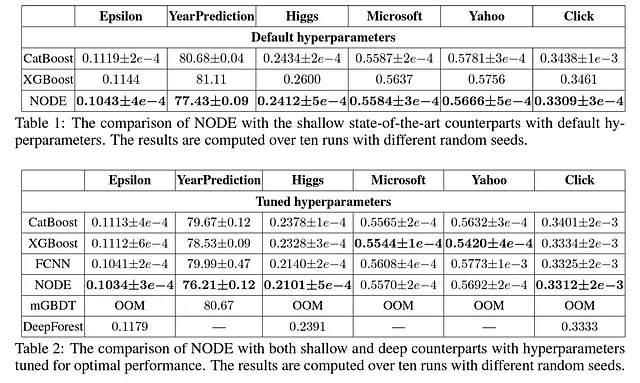
NODEの実験結果は非常に励みになります。まず、デフォルトのパラメータで、NODEのアーキテクチャは他のすべてのモデルを上回っています。チューニングされたパラメータでも、NODEは選択された6つのデータセットのうち4つで他のほとんどのモデルよりも優れた結果を出しています。
結論
決定木の利点をニューラルネットワークのアーキテクチャに取り入れることにより、NODEは金融、医療、顧客分析など、構造化された表形式のデータが一般的な領域において、深層学習の応用に新たな可能性を開いています。
ただし、NODEが完璧であるとは言えません。まず、アーキテクチャのアンサンブルにより、ニューラル決定木を使用することで得られる多くの局所的な解釈性の向上が失われ、モデルからはグローバルな特徴の重要性のみが得られます。ただし、このアーキテクチャはニューラル解釈性の向上のための基盤を提供し、解釈性のギャップを埋めるための後続モデル(NODE-GAM [7])が提案されています。
また、NODEは多くの浅いモデルを上回りますが、私の使用経験からは、GPUを使用していてもトレーニングに時間がかかることが示されています(論文の著者による実験結果もこの結論を支持しています)。
全体として、これは非常に有望なアプローチであり、将来の深層学習モデルの構成要素として積極的に使用する予定です。
リソースと参考文献
- NODE論文: https://arxiv.org/abs/1909.06312
- NODEのコード: https://github.com/Qwicen/node
- NODEはPytorch Tabularパッケージでも利用可能です: https://github.com/manujosephv/pytorch_tabular
- 解釈可能な機械学習や時系列予測に興味がある場合は、私をフォローしてください: https://medium.com/@upadhyan
- ニューラル決定木に関する他の記事はこちら: https://medium.com/@upadhyan/list/3b4a9cb97b84
参考文献
[1] Popov, S., Morozov, S., & Babenko, A. (2019). Neural oblivious decision ensembles for deep learning on tabular data. Eight International Conference on Learning Representations.
[2] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: unbiased boosting with categorical features. Advances in neural information processing systems , 31 .
[3] Peters, B., Niculae, V., & Martins, A. (2019). Sparse Sequence-to-Sequence Models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 1504–1519). Association for Computational Linguistics.
[4] Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785–794).
[5] Feng, J., Yu, Y., & Zhou, Z. H. (2018). Multi-layered gradient boosting decision trees. Advances in neural information processing systems , 31 .
[6] Zhou, Z. H., & Feng, J. (2019). Deep forest. National science review , 6 (1), 74–86.
[7] Chang, C.H., Caruana, R., & Goldenberg, A. (2022). NODE-GAM: Neural Generalized Additive Model for Interpretable Deep Learning. In International Conference on Learning Representations .
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





