「NLPモデルの正規化に関するクイックガイド」
NLPモデルの正規化に関するクイックガイド
正規化を使ってモデルの収束を加速し、トレーニングプロセスを安定させましょう
はじめに
ディープラーニングモデルの効率的なトレーニングは困難です。NLPモデルのサイズとアーキテクチャの複雑さが最近増加しているため、問題はより難しくなっています。数十億のパラメータを扱うために、より高速な収束と安定したトレーニングを実現するためのさまざまな最適化手法が提案されています。その中でも特に注目されるのが正規化です。
本記事では、いくつかの正規化手法について学び、それらがどのように機能し、NLPディープモデルにどのように使用できるかを紹介します。
BatchNormではなぜダメなのか?
BatchNorm [2]は、内部共変量シフトを解決するために提案された初期の正規化手法です。
簡単に説明すると、内部共変量シフトは、レイヤーの入力データ分布が変化した場合に発生します。ニューラルネットワークが異なるデータ分布に適合する必要があるとき、勾配の更新はバッチ間で劇的に変化します。そのため、モデルの調整、正しい重みの学習、収束には時間がかかります。モデルのサイズが大きくなるほど、問題は悪化します。
- 「Plotly Graph Objectsを使用してウォーターフォールチャートを作成する方法」
- 「ChatGPT Meme Creator Pluginを使ってミームを作成する(ビジネスを成長させるために)」
- 「MLCommonsがAIモデルを実行するための新しいベンチマーク速度テストを公開しました」
初期の解決策には、学習率を小さくする(データ分布のシフトの影響を軽減する)ことや、注意深い重みの初期化が含まれます。BatchNormは、入力を特徴次元で正規化することで、効果的に問題を解決しました。
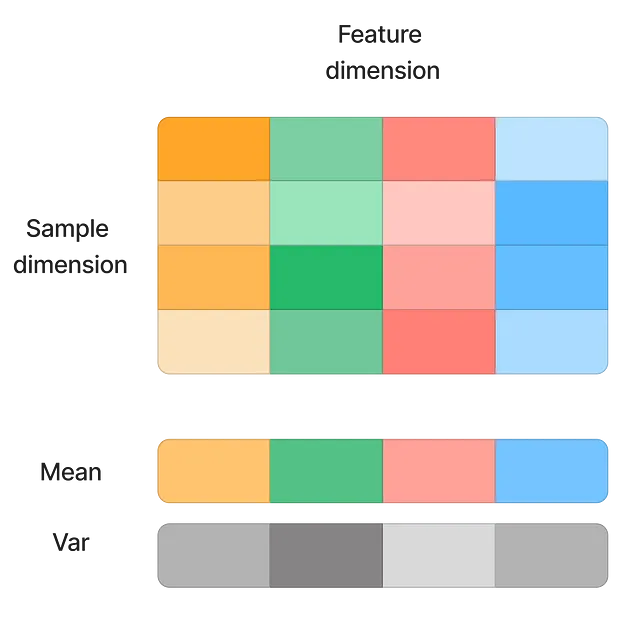
この技術は収束を大幅に高速化し、モデルが外れ値に対してより感度が低くなるため、より高い学習率を許容します。ただし、いくつかの欠点もあります:
- バッチサイズが小さい: BatchNormは、バッチデータを使用して特徴の平均値と標準偏差を計算します。バッチサイズが小さい場合、平均値と分散は母集団を代表できなくなります。そのため、BatchNormではオンライン学習が不可能です。
- シーケンス入力: BatchNormでは、各入力サンプルの正規化は同じバッチ内の他のサンプルに依存します。これはシーケンスデータとはあまりうまく機能しません。例えば…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





