NLP で仕事検索を強化しましょう
NLPで仕事検索を強化しましょう' can be condensed to 'NLPで仕事検索強化
sBERTをベースにしたセマンティック検索機能とPlotly Dashインターフェースを備えたWebアプリの紹介 | ライブアプリ | Git Hub
はじめに
一般的な求人プラットフォームでは、検索機能はいくつかの入力ワードといくつかのフィルタ(場所など)に基づいて求人を絞り込むことができます。これらのワードは一般的に、ドメインまたは希望するポジションを示し、ほとんどの場合、検索システムが取得する求人の説明文には入力ワードが「必ず」含まれている必要があります。最新の自然言語処理(NLP)の技術がどの程度採用されているかは正確にはわかりません。
NLPは近年、注目すべき進展を遂げており、検索を次のレベルに引き上げるためのいくつかの技術を活用することができます。たとえば、クエリ文のセットに基づいてセマンティック検索を使用することが考えられます。これらのクエリ文は、次のような内容を示します。
- 次の仕事で実行したいタスク
- 企業文化などの理想的な働き方の環境
- (テック系の仕事の場合)使用したいテックスタック
本記事では、sBERT(sentence BERT)モデルの仕組みを説明し、事前学習済みモデルを活用して求人検索などの日常的なタスクの改善方法を紹介します。
Dashアプリには、これらの検索機能が組み込まれています。以下はその様子です:
- チャットGPTからPiへ、そしてなぜそうするのかをお伝えします!
- ローカルで質問応答(QA)タスク用にLLMを微調整する方法
- 「GPT4Readability — リードミーをもう一度書く必要はありません」

目次
1. sBERTとは?1.1 NLPエンベディング技術のクイックレビュー1.2 Transformersの概要1.3 TransformersからsBERTへ1.4 BERTからsBERTへ2. 文のエンベディングの生成2.1 事前学習済みモデルの選択2.2 セマンティック検索に事前学習済みモデルを使用する3. Dashを使用してすべてを統合する3.1 データの準備3.2 アプリの入力3.3 マッチングメカニズム参考文献
1. sBERTとは?
1.1 NLPエンベディング技術のクイックレビュー
検索などのNLPタスクでは、テキストを数値ベクトルに変換する必要があります。これにより、数学的な操作を行うことができます。エンベディング技術には、さまざまな手法があります:
- 「単語の袋」:これらの伝統的な手法では、単語の頻度または用語の共起を使用して、単語(またはドキュメント)レベルでのエンベディングを作成します。各ベクトルはバイナリエントリまたは頻度エントリで構成されます(頻度を測定する方法はいくつかあります:tf-idf、ppmi、bm25など)。生成されるベクトルは通常、大きすぎて疎なものとなります。
- 「カウントベースのモデル」:これらのモデルは、上記の手法のサイズ/疎さの制約を克服します。用語の共起行列(またはドキュメント-用語行列)から始めて、次元削減技術を適用して密で小さいベクトルを作成します。これらの手法の例には、GloVe(サイズを減らすためにSVD、特異値分解の拡張バージョンを使用する)、LSA(潜在的意味解析)などがあります。
- 「予測モデル」:これらのモデルは、単語を予測するためにトレーニングされた単純な(1つの隠れ層を持つ)ニューラルネットワークを使用します。Word2Vecは非常に有名なモデルです(詳細はこちら)。Word2Vecは、周囲の単語(固定ウィンドウを使用)からターゲットの単語を予測するか、逆に(与えられた単語から文脈を予測する)トレーニングできます。隠れ層が学習した重みは、単語のエンベディングとして使用することができます。
- 「コンテキストエンベディング」:より最近の研究では、コンテキストを考慮した単語表現の作成に焦点を当てています。実際には、Word2Vecなどのモデルは各単語の「グローバル」な表現を作成し、いくつかの明らかな制約があります(多義性、文脈依存の用語などを考えてください)。コンテキストエンベディングモデルは、コンテキスト、単語のタイプ(名詞/動詞)、文法ルールなどに応じて変化する動的な単語表現を作成できます。これらのモデルはディープニューラルネットワークに基づいています。一時期、異なるタイプのRNN(再帰ニューラルネットワーク)(LSTM、GRUなど)が提案されましたが、いくつかの制約がありました:(a)これらのアーキテクチャは順次トレーニングする必要があるため、計算上遅かったこと、(b)コーパス内で非常に遠い単語を関連付ける際に制約がありました。これらの制約は、Googleによって作成されたネットワークアーキテクチャであるTransformersによって克服され、BERT、GPTなどのさまざまなモデルの作成にインスピレーションを与えました。
1.2 トランスフォーマーの概要
トランスフォーマーのニューラルネットワークは、機械翻訳のタスクで提案されました。エンコーダーアーキテクチャとデコーダーアーキテクチャを持っています。この記事では、テキスト埋め込みにトランスフォーマーを使用することに興味があるため、エンコーダーパートにのみ焦点を当てます:
![Transformer Encoding Architecture | Picture from [1] (Figure 1)](https://miro.medium.com/v2/resize:fit:640/format:webp/1*oiwWwhHc5QoQI5kguuE21g.png)
- 入力埋め込み: トランスフォーマーアーキテクチャは、各単語ごとに次元512の埋め込みベクトルを入力として受け取ります(入力埋め込みは後で改善される初期化です)。
- 位置エンコーディング: トランスフォーマーはRNNのように単語ごとに入力を受け取るのではなく、すべての単語埋め込みを同時に受け取るため、各単語の位置に関する追加情報が必要です。そのため、入力埋め込みベクトルは位置ベクトルに加算されます。各位置ベクトルはフーリエ級数理論を使用して構築されます。sinとcos関数を使用して、文中の単語の位置(pos)とベクトルのi番目の次元(i)に依存しない一意のベクトルを取得します。各単語と次元ごとに、位置スコアは対応する埋め込みに追加されます(グラフィカルかつより包括的な説明については、このリンクを参照してください)。
- セルフアテンションメカニズム: 直感的には、アテンションメカニズムはモデルにタスクの完了に関連する入力の重みを割り当てることを可能にします。これには、コンピュータビジョン(例:物体検出)で明確な例があります。CNN(畳み込みニューラルネットワーク)は、画像に適用されるための「フィルタ」を学習し、ネットワークが関連するピクセルに焦点を当てることができます。このコンセプトは、Q(クエリ)、K(キー)、V(値)行列を使用してNLPにも適用され、入力ベクトルの単なるコピーです。QとKの行列は、各用語のペアごとの注意スコアが含まれる「マスク」行列を構築するために乗算されます。乗算により、類似したペアはより高いスコアを取得します(softmax関数によりこれらのスコアは0から1に制約されます)。このアテンションフィルタは、V行列と乗算され、各用語のペアごとに重み付けられた値を取得します。直感的には、この方法により、タスクを完了するために各用語を入力文の他の部分とリンクすることができます(例:機械翻訳)(グラフィカルかつより包括的な説明については、このリンクを参照してください):
![Self-attention mechanism | Picture from [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*21-74hrxnaZ-POCKvi7xcA.png)
- マルチヘッドアテンション: 上記のアテンションメカニズムは複数回繰り返されます。直感的には、モデルは異なる視点からタスクを学習するため、一つのレイヤーは語彙に対するアテンションを使用し、別のレイヤーは文法に対するアテンションを使用するなどのことを意味します。
エンコーディング層全体の出力として、すべての埋め込みベクトルを含む行列を得ます。これらのベクトルは、単語の埋め込み、位置エンコーディング情報、およびアテンションレイヤーによって優先された文の他の単語に関するコンテキスト情報を格納します。
1.3 トランスフォーマーからBERTへ
トランスフォーマーペーパー以降、特定の目的のためにこのアーキテクチャの変種を使用したいくつかのモデルが作成されました。
BERT(トランスフォーマーからの双方向エンコーダーレプレゼンテーション)は、Googleが2018年に作成したものです[2]。このモデルは、トランスフォーマーアーキテクチャのエンコーダーコンポーネントのみを使用して作成されました。このモデルのアイデアは、コンテキストに依存した意味的な埋め込みを生成し、その埋め込みをファインチューニングステップに渡すことができる汎用の事前学習モデルを作成することでした。簡単に言えば、ユーザーは特定のタスクに応じて、事前学習済みのBERTモデルを使用し、ファインチューニングレイヤーを追加してトレーニングを完了させることができます(例:特定の分類タスクに応じて)。
元のエンコーダーと比較して、BERTモデルは次のような変更が加えられています:
- アーキテクチャにいくつかの変更を加えます:トランスフォーマーエンコーダーをより多く重ねる(「BERTベース」バージョンでは12回、「BERTラージ」バージョンでは24回);セルフアテンションメカニズムにより多くのマルチヘッドを追加(「BERTベース」バージョンでは12個、「BERTラージ」バージョンでは16個);最終的な埋め込みベクトルのサイズを大きくする(「BERTベース」では768、「BERTラージ」では1024)。
- BERTは2つの教師なしタスクでトレーニングされます。以下に説明します。
以下の2つのタスクがあります:
- マスクされた言語モデル(MLM):入力の中で破損した単語を予測します。訓練中、入力文の15%のトークンが3つの異なる方法で「マスク」されました(80%の場合、トークンは[MASK]トークンで置き換えられ、10%の場合はランダムな単語で、10%の場合は変更されませんでした)。エンコーダはこれらのトークンを予測するように訓練されました。
- 次の文予測(NSP):BERTは、質問応答や推論のパフォーマンスを向上させるために、2つの文の関係を学習するように訓練されました。入力として文A、Bのペアが与えられると(特別な[SEP]トークンで区切られている)、BがAの直後の自然な文である場合は50%の確率で、Bがランダムな文である場合は50%の確率で、エンコーダはAからBへの関連性を示す「isNext」ラベルを予測するように訓練されました。
1.4 BERTからsBERTへ
2019年にsBERT(sentence-BERT)モデルが作成され、文の類似性や文のクラスタリングなどの特定のタスクにおいてBERTモデルを改善するために使用されました。sBERTの論文では、元のBERTモデルの以下の「弱点」が強調されています:
- BERTはNSPで訓練されましたが、それは正確には2つの文AとBの類似性を予測するものではありません。
- BERTは2つの入力文が必要ですが、これはコーパス内で最も類似した文を探す際に計算を遅くします。
- BERTは単一の文の埋め込みを出力しません。(BERTから文の埋め込みを抽出するためにいくつかの戦略がテストされましたが、一致する方法は見つかりませんでした)。
sBERTモデルは、以下のアーキテクチャで作成されました:
![sBERT architecture | Picture from [3]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*1It9uBtVSHJtsrT6nFG7IQ.png)
- BERTモデルは各文に対して埋め込みを生成するために使用されます。先に述べたように、BERTから文の埋め込みを抽出するための単一の方法はないため、sBERTのデフォルトの方法は、すべてのトランスフォーマの出力の平均値を計算することです。その後、「プーリング」レイヤーが追加され、文の長さに関係なく固定サイズの文の埋め込みが計算されます。
- sBERTはSiameseネットワーク(同じアーキテクチャの2つのコピー)を使用し、異なるタスク(例:文の分類と回帰)で訓練されます(図はこの2番目の場合、つまり文の類似性の予測を示しています)。タスクに応じて、アーキテクチャのトップレベルの目的関数を変更できます。
事前訓練されたsBERTモデルのおかげで、計算効率の良い方法で固定サイズの複雑な文の埋め込みを作成できます!以下に例を見てみましょう。
2. 文の埋め込みの生成
2.1 事前訓練モデルの選択
sBERTのリリース以来、多くの事前訓練モデルが構築され、さまざまなタスクで比較されました。
モデルを選ぶために、まずはタスクに適したモデルに焦点を当てましょう。この記事では、シンタックスの検索に適したモデルを見つけたいと思います。以下の2つのタイプがあります:
- シンメトリック検索:クエリと結果がほぼ同じサイズで、内容も似ている場合、シンメトリック検索があります。
- 非対称検索:クエリが短く、期待される結果はクエリに答えるより長い文です。
ここではシンメトリックなシンタックスの検索を行います。このタスクに事前訓練されたトップパフォーマンスのモデルのリストを以下に示します。この記事の時点では、トップパフォーマンスのモデルはall-mpnet-base-v2 [4]で、以下の特徴があります:
- 上記1億以上の文を使用して文の類似性を予測するために事前訓練されています。
- 最大384トークンの単語の入力文を許可します(長い入力は自動的に切り詰められます)。
- サイズ768の埋め込みを出力します。
2.2 シンタックスの検索に事前訓練モデルを使用する
上記のモデルを実際に使用してみましょう。
2つのジョブの説明から以下の2つの文を抽出したとします。1つはチャーンモデルの経験を持つ候補者を探しており、もう1つはNLPの経験を持つ候補者を探しています:
顧客分析の経験に合った仕事を探しているユーザーは、次のクエリを入力します:
クエリと2つの文の間には、単語の重複がないことに注目してください。従来のモデルでは、意味や文脈情報をエンコードしない限り、クエリを2つの文のいずれかと関連付けることができません。
HuggingfaceからsBERTモデルをダウンロードし、3つの文をエンコードしましょう:
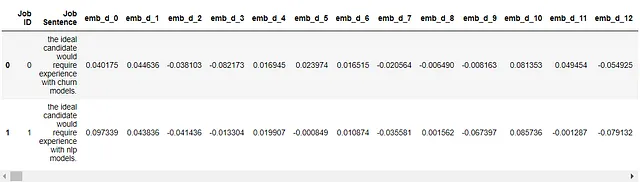
または、Huggingface APIを使用して埋め込みをリクエストすることもできます:
クエリと各仕事の文とのコサイン類似度を計算できます:

そして、埋め込みをプロットします(埋め込みを3次元に削減するためにtSNEを使用します):
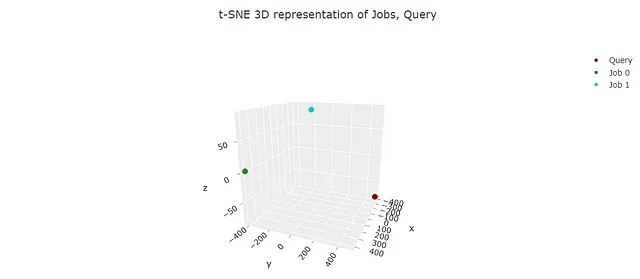
“job 0”がクエリにより類似していると正しく選択されたことが分かります。このモデルは、チャーンモデルが顧客満足度と維持に関連していることを「知っています」。これは、nlpと比較しています!!!
3. Dashを使ってすべてをまとめる
Dashを使って検索システムをシミュレートするWebアプリケーションを作成できます。このアプリはPython Anywhereを使ってデプロイされています。こちらからアクセスできます。
3.1 データの準備
検索を開始する前に、データを準備し、クリーンアップし、各文の埋め込みを生成する必要があります:
- 利用可能な求人の詳細データがあると仮定します。このデータを取得するには、求人プラットフォームをスクレイピングできます(ここには1つの例があります)。
- データは、古典的なNLPの技術を使用して前処理され、文にトークン化される必要があります(このプロジェクトでは、このコードが使用されます)。
- 私が設計したアプリでは、2つのデータフレームが使用されています。1つは「Job_Info」で、すべての求人情報(求人ID、場所、雇用主、詳細な説明など)を含み、もう1つは「df_embeddings」で、1行に1つの文が含まれています。
- 文のデータフレームを使用して、事前学習済みのsBERTモデルのコピーを使用して文の埋め込みを生成します(文の埋め込みは直接「df_embeddings」に保存されます)。
3.2 アプリの入力
アプリは動作するためにユーザー入力が必要です。ユーザーは以下の操作を行う必要があります:
- いくつかのクエリ文を書く。アプリは最大で10個のクエリ文を管理します。
- (オプション)利用可能な場所の中から選択する。
「検索」ボタンを押すと、アプリはHuggingface APIを使用して各クエリ文を埋め込みます(使用されるモデルとコードは上記に表示されます)。 (このアプリのコピーをローカルにセットアップする場合は、「.assets/nlp_functions.py/embed_api」に独自のAPIトークンを入力することを忘れないでください)。
入力インタフェースは次のようになります:
3.3 マッチングメカニズム
アプリは、各求人文と各クエリ文のコサイン類似度を計算して求人をランク付けします。
各求人とクエリ文の最大類似度が保存されます。したがって、4つの入力クエリ文がある場合、各求人には4つの類似度スコアがあります。
これらの類似度スコアを使用して、各求人は1(トップ類似度)からnまでのランク付けがされます。
最後に、異なるランクは重み付け平均を使用して組み合わせられ、求人ごとに単一の最終的なランキングスコアが生成されます。理由と方法は以下の通りです:
- 2つの入力クエリ文があると仮定します。すべてのジョブ文を通じて、クエリ-1の類似度の最大値は0.2であり、クエリ-2の最大値は0.8です。
- クエリ-1で1位にランクされたジョブ(すべての文のcos類似度を比較)が、クエリ-2では10位にランクされた場合、クエリ-1ではスコアが悪くなりましたが、クエリ-2では良くなった他のジョブを優先することができます。
- したがって、各クエリで得られた最大類似度を使用して個々のジョブの順位の加重平均が計算されます。
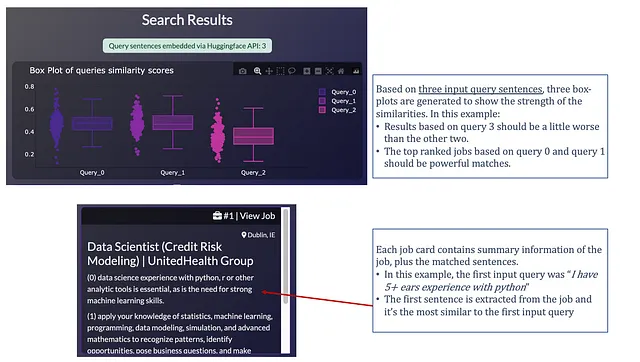
最後に、アプリは2つの出力を生成します:
- 一つのクエリ文ごとに生成されるボックスプロットで、ジョブとクエリ文の類似度スコアの「強さ」を示します。各ジョブの最大類似度スコアが個々のデータポイントとなります。このチャートを使うことで、クエリ文が「強い」一致を生み出したかどうかをすぐに確認できます。
- 順位付けされた結果:最も類似したジョブから最も類似していないジョブまで、1つのdbc.Cardが生成されます。各ジョブカードには、ジョブのランキングに使用されたフルジョブ説明から抽出された文が含まれています。
以下は、出力インターフェースの見た目です:
この情報が役に立ち、自分自身の求職活動に応用していただけると嬉しいです。読んでいただきありがとうございました!!!
参考文献
- [1] “Attention is all you need” (2017) — Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 実装ノート、コードレビュー、例を含む注釈付きバージョン。
- [2] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (2018) — Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
- [3] “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks” (2019) — Nils Reimers, and Iryna Gurevych
- [4] Huggingfaceの「all-mpnet-base-v2」モデル
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






