「マシンラーニングによるNBAの給与予測」
NBA salary prediction using machine learning
Pythonを使用してNBAの給与を予測し、最も影響力のある変数を分析する機械学習モデルの構築
NBAは、スポーツの中でも最も収益性が高く競争力のあるリーグの一つです。最近の数年間、NBA選手の給与は上昇傾向にありますが、魅惑的なスラムダンクやスリーポイントシュートの裏には、これらの給与を決定する複雑な要素のウェブがあります。
選手のパフォーマンスやチームの成功から市場の需要やエンドースメント契約まで、様々な変数が影響を及ぼします。誰もがなぜ自分のチームが成績不振の選手に多額の給与を支払ったのか疑問に思ったことがあるでしょうし、特に成功した契約の背後にある戦略に感嘆したことでしょう。
この記事では、Pythonを使用して機械学習の能力を活用し、NBAの給与を予測し、選手の収入に最も影響を与える重要な要素を明らかにします。
使用したすべてのコードとデータはGitHubで利用可能です。
- 「高等教育の前にデータサイエンスのブートキャンプを検討する5つの理由」
- データアーキテクチャとCAP定理:どこで衝突するのか?
- 「サンフランシスコ大学データサイエンスカンファレンス2023年データソン(Datathon)は、AWSおよびAmazon SageMaker Studio Labと提携して開催されます」
問題の理解
問題に取り組む前に、リーグの給与制度の基本を把握することが重要です。選手が市場で契約を結ぶために利用可能な状態のとき、彼はフリーエージェント(FA)として知られており、このプロジェクトではこの用語がよく使用されます。
NBAは競争力のあるバランスを保つために、複雑なルールと規制の下で運営されています。このシステムの核心には2つの重要な概念があります。それが給与キャップとリッチタックスです。
給与キャップは、チームが特定のシーズンに選手の給与にどれだけ費やすことができるかを制限する支出制限です。キャップはリーグの収益によって決定され、チームが合理的な財務フレームワーク内で運営することを毎年更新して保証します。また、大市場のチームが小市場の競争相手に比べて大幅に支出することを防ぎ、フランチャイズ間の公平性を促進することを目的としています。
給与キャップの分配は、トップクラスの選手には最大給与があり、ルーキーやベテランには最低給与があります。
しかし、給与キャップを超えることは珍しくありません。特に優勝を目指すチームは給与キャップを超えることがあります。給与キャップを超えると、リッチタックスの領域に入ります。リッチタックスは、一定の閾値を超えて支出するチームに罰金を課し、チームが過度な支出をするのを抑制し、同時にリーグに追加の収入を提供します。
他にもミッドレベル例外(MLE)やトレード例外など、戦略的なロスタームーブを行うためのルールがいくつかありますが、このプロジェクトでは給与キャップとリッチタックスの知識が十分です。

給与キャップの持続的な成長により、このプロジェクトでは給与額そのものではなく、キャップの割合を対象とすることになります。この決定はキャップの変動する性質を取り入れ、結果が時間的な変化に影響を受けず、歴史的なシーズンを評価する場合にも適用可能であることを保証するためです。ただし、これは完璧ではなく、近似値に過ぎません。
データ
このプロジェクトでは、来シーズンに新たな契約を結ぶ選手の給与を予測することを目標に、前シーズンのデータのみを使用します。
使用される個々の統計データは以下の通りです:
- 1試合あたりの平均統計データ
- 合計統計データ
- 高度な統計データ
- 個別変数:年齢、ポジション
- 給与関連変数:前シーズンの給与、前シーズンおよび現在のシーズンの最大キャップ、その給与のキャップに対する割合。
選手がどのチームにサインするかはわからないため、個々の特徴のみが含まれています。
この研究では、各選手にはターゲットを含めて78の特徴がありました。
ほとんどのデータは、私が作成した最新のPythonパッケージであるBRScraperを使用して取得されました。このパッケージは、NBA、Gリーグ、その他の国際リーグを含むBasketball Referenceからのバスケットボールデータのスクレイピングと簡単なアクセスを可能にします。ウェブサイトに損害を与えたり、パフォーマンスを妨げるような行動は避けられました。
データの処理
考慮すべき興味深い点の1つは、モデルのトレーニングに選手を選ぶことです。最初に利用可能なすべての選手を選択しましたが、ほとんどの選手は既に契約中であり、その場合給与の値は大幅に変化しません。
例えば、選手が4年間で2,000万ドルの契約を結ぶとします。彼は年間約500万ドルを受け取ります(すべての年が同じ値ではなく、通常は約500万ドルの給与の進行があります)。しかし、フリーエージェントが新しい契約を結ぶ場合、給与の値はより急激に変化する可能性があります。
これは、利用可能なすべての選手でモデルをトレーニングすると、全体的なパフォーマンスが向上する可能性があることを意味します(結局のところ、ほとんどの選手の給与は直近に非常に近いでしょう!)。ただし、フリーエージェントのみを評価する場合、パフォーマンスは著しく悪くなる可能性があります。
目標は新しい契約を結ぶ選手の給与を予測することなので、この種の選手のみがデータに含まれるべきです。そうすれば、モデルはこれらの選手間のパターンをより良く理解できます。
興味のあるシーズンは今後の2023–24シーズンですが、データのサンプル数を増やすために2020–21以降のデータが使用されます。以前のシーズンはフリーエージェントのデータがないため使用されませんでした。
これにより、3シーズンで426人の選手が残り、そのうち84人が2023–24のフリーエージェントです。
モデリング
トレーニングとテストの分割は、2023–24のフリーエージェントがテストセットに独占的に含まれるように設計され、おおよそ70/30の割合を保ちました。
最初に、いくつかの回帰モデルが使用されました:
- サポートベクターマシン(SVM)
- Elastic Net
- ランダムフォレスト
- AdaBoost
- グラディエントブースティング
- Light Gradient Boosting Machine(LGBM)
それぞれのパフォーマンスは、平均二乗誤差(RMSE)と決定係数(R²)で評価されました。
各指標の式と説明については、私の以前の記事「Machine LearningによるNBA MVPの予測」をご覧ください。
Machine LearningによるNBA MVPの予測
NBA MVPの予測と最も影響力のある変数の分析のための機械学習モデルの構築。
towardsdatascience.com
結果
すべてのシーズンを含むデータセットを見ると、以下の結果が得られました:

モデルは全体的に良好なパフォーマンスを示し、ランダムフォレストとグラディエントブースティングが最も低いRMSEを達成し、最も高いR²を示しました。一方、AdaBoostは使用されたモデルの中で最も悪い指標を持っていました。
変数の分析
モデルの予測に影響を与える主要な変数を視覚化するための効果的なアプローチは、SHAP値を通じて行います。これは、各特徴がモデルの予測にどのような影響を与えるかを合理的に説明する手法です。
再度、SHAPについての詳しい説明や、そのチャートの解釈方法については、「機械学習によるNBA MVPの予測」で見つけることができます。
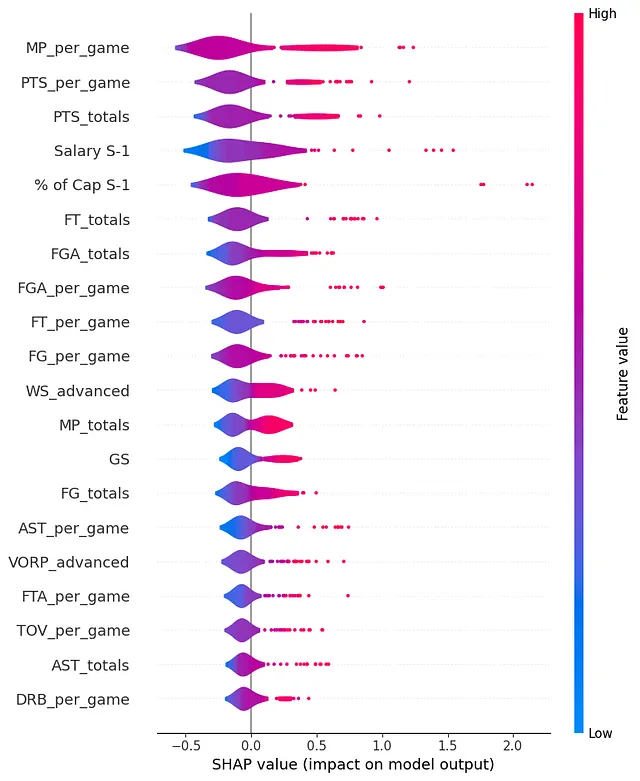
このチャートからいくつか重要な結論を得ることができます:
- 1試合あたりのプレー時間(MP)と1試合あたりの得点(PTS)および合計得点が最も影響力のある3つの特徴です。
- 前シーズンの給与(Salary S-1)およびその給与のキャップに対する割合(% Cap S-1)も非常に影響力があり、4位と5位です。
- 高度な統計は最も重要な特徴の中で主要ではありませんが、リストには2つだけが表示されます。それは、WS(勝利シェア)とVORP(交代選手に対する価値)です。
この結果は非常に驚くべきものです。なぜなら、MVPのプロジェクトとは異なり、高度な統計がSHAPの最終結果を支配していたということであり、プレーヤーの給与は一般的な統計であるプレー時間、得点、試合出場にかなり関連しているように見えるからです。
これは驚くべきことです。なぜなら、ほとんどの高度な統計は、選手のパフォーマンスをより良く評価することを目的として設計されています。上位20位にもかかわらず、最も効果的な特徴の中にPER(プレーヤー効率評価)がない(43位に表示される)ことは特に注目に値します。
これは、給与交渉の際に、ゼネラルマネージャーが比較的簡単なアプローチに従っている可能性があることを示唆しています。それにより、より広範なパフォーマンス評価指標を見落としているかもしれません。
問題はそんなに複雑ではないかもしれません! 一番プレー時間が長く、最も得点を獲得する選手がより多くの給与をもらいます!
追加の結果
今年のフリーエージェントに焦点を当て、彼らの予測と実際の給与を比較すると:
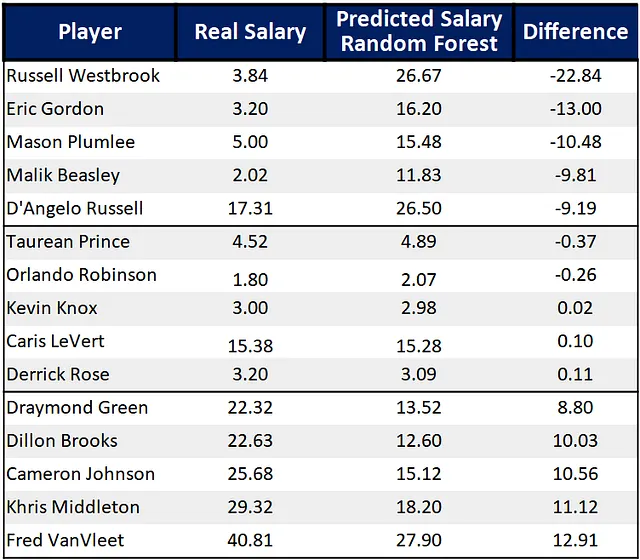
上位には過小評価されているように見える5人の選手がおり、中央には適切な評価を受けている5人の選手、そして下位には過大評価されているように見える5人の選手がいます。これらの評価は、モデルの出力に基づいていることに注意することが重要です。
まず上位から、前回のMVPであるラッセル・ウェストブルックは、モデルによれば最も過小評価されている選手であり、私の意見でも事実です。彼はクリッパーズと約4Mドル/年の契約を結びました。 エリック・ゴードン、メイソン・プラムリー、マリク・ビーズリーも同様の状況で、良いパフォーマンスに対して非常に小さな契約を獲得しています。 ダンジェロ・ラッセルもこのトップ5に入っていますが、年間1700万ドルの給与をもらっていることから、さらに多くの給与をもらうべきだと示しています。
興味深いことに、これらの選手はすべて有力な チーム(クリッパーズ、サンズ、バックス、レイカーズ)と契約しています。これは、選手がタイトルを獲得できるチームでプレーする機会を得るために少ない給与を選ぶという既知の行動です。
中間には、タウリアン・プリンス、オーランド・ロビンソン、ケビン・ノックス、デリック・ローズがすべて適切な給与を得ているように見えます。 カリス・レバートは年間1500万ドルを獲得していますが、まさにその価値があるようです。
下には、Fred VanVleetが最も過大評価された選手として任命されました。再建中のチームとして動作するロケッツは、彼の新しい3年契約が128.5Mドルで評価された注目すべき動きをしました。彼らはまた、Dillon Brooksを予想以上の価値で契約しました。
Khris Middletonはこの夏、大きな延長契約に署名しました。競争力のあるチームであるにもかかわらず、バックスは主要市場に属しておらず、彼らの最高の選手の1人を失うことはできません。 Draymond GreenとCameron Johnsonもそれぞれのチームで似たような状況にあります。
結論
スポーツの結果を予測することは常に挑戦的です。ターゲットの選択から選手の選択まで、このプロジェクトは予想以上に複雑であることが証明されました。しかし、結果は非常にシンプルで、得られた結果は非常に満足できるものでした!
確かに、改善するためには複数の方法があります。その1つが、特徴選択や次元削減技術の使用による特徴空間の削減および分散の削減です。
さらに、前のシーズンのフリーエージェントにアクセスできれば、サンプル数を増やすことも可能になります。ただし、現時点ではそのようなデータは一般に公開されていないようです。
他にも多くの外部変数がこの問題に影響を与えます。たとえば、チームが既知である場合、前年のシード、プレーオフの結果、既に使用されたキャップの割合などの変数は非常に有益な情報となるでしょう。ただし、チームが不明な実際のフリーエージェントのシナリオの状況を反映するアプローチを維持することで、選手の「実際の価値」により近い結果が得られる可能性があります。
このプロジェクトの主要な前提の1つは、次の給与を予測するために前のシーズンのデータのみを使用することでした。過去のシーズンの統計データを組み込むことは、プレーヤーの過去のパフォーマンスが貴重な洞察を提供できるため、改善された結果を生み出す可能性があります。ただし、そのようなデータの広範な性質は、複雑さと高次元性を管理するために慎重な特徴選択を必要とします。
再び、使用されたすべてのコードとデータはGitHubで利用可能です。
常に私のチャンネル(LinkedInとGitHub)で利用可能です。
ご注意いただきありがとうございます!👏
Gabriel Speranza Pastorello
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
