MySQLのJSON_ARRAYAGG関数をハッキングして、動的で複数値の次元を作成する
MySQLのJSON_ARRAYAGG関数をハッキングして、動的な複数値次元を作成する' The condensed version is Hacking the MySQL JSON_ARRAYAGG function to create dynamic multidimensional values.
MySQLのあまり知られていない欠点の一つをカバーする
イントロダクション
サブスクリプションボックス会社のデータチームのメンバーであると想像してみましょう。MySQLデータベースでは、購入のトランザクションレコードがsubscriptionsというテーブルに書き込まれます。メタデータを除くと、テーブルにはcustomer_idとsubscriptionのフィールドが含まれ、次のような形式になります:
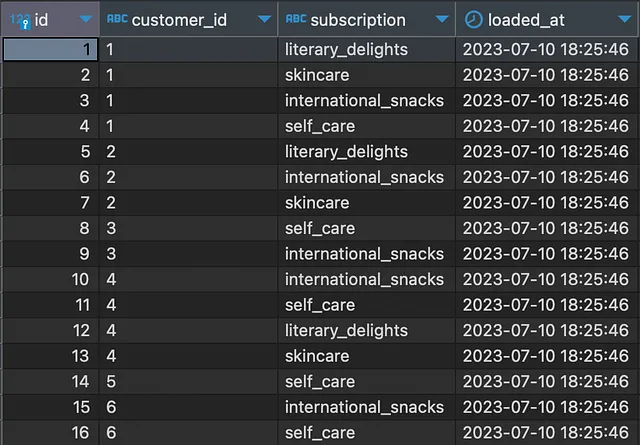
この例のシナリオでは、顧客は複数のサブスクリプションを持つことができます。各レコードの一意性は、顧客IDとサブスクリプションの両方によって定義されます。つまり、同じサブスクリプションを2回持つことはできません。このテストデータを自分のデータベースにロードしたい場合は、ここでそのコードを見つけることができます。
サブスクリプションボックス会社として、私たちの目標はより多くのサブスクリプションボックスを販売することです。そのため、プロダクトチームは最近、現在のすべての顧客が複数のサブスクリプションを持っていることに気付きました。彼らはこのことが顧客の行動について何を示しているのかに興味を持っています。彼らは私たちのチームに、ユーザーが購入したサブスクリプションの組み合わせを示すデータモデルを求め、また、どの組み合わせが最も一般的かも知りたいと頼んでいます。
マーケティングチームもこのモデルに興味を示しています。彼らはこの結果が、商品のバンドルプロモーション、顧客のプロファイリング、およびメールキャンペーンの対象になる可能性があると考えています。同じ理由で、彼らは各顧客が購入した最も一般的なサブスクリプションの合計数も見たいと頼んでいます。
- 「データエンジニア vs データサイエンティスト:どちらのキャリアを選ぶべきか?」
- 「データレイクの形式の選択:実際に見るべきものは何ですか」
- 「北極の画像の新しいデータセットが人工知能研究を促進するでしょう」
要するに、要求されているデータモデルは、理想的にはサブスクリプションボックスの販売数を増やす結果につながる重要な質問に答えることを目指しています。問題は、具体的にどのように実行すべきかです。
この記事では、MySQLのあまり知られていない欠点をカバーすることで、ユニークなデータモデリングの課題に取り組みます。定性的な集計、JSONデータ型、およびMySQLに値のリストを生成するように順序付ける方法について説明します。
目次
- 寸法としての集計
- MySQLのJSONデータ型の概要
- JSON_ARRAYAGG
- ROW_NUMBERを使用して値の順序付けを強制する
- まとめると
寸法としての集計
概念的には、私たちが行う必要があることは比較的単純です:顧客ごとにサブスクリプションをバンドル(グループ化)する必要があります。その後、これらのバンドルを見て、最も一般的なものとそれらに含まれるサブスクリプションの数を調べる必要があります。
データモデリングの観点では、いくつかの形式の集計を見ています:具体的には、顧客ごとにサブスクリプションを集計しています。
集計関数は、定量的な意味で(SUM、COUNTなど)について考えることが一般的です。これは、SQLでのほとんどの集計関数がこのように動作するためです。ただし、連結された文字列値を長いリストのような文字列に集計することもできます。
ただし、この場合、これらの連結された文字列内の値にアクセスしたり、操作したり、評価したりすることが困難です。MySQLは、値foo、bar、hello、worldをリストではなくテキストとして扱います。
なぜこれが関連しているのでしょうか?仮想のシナリオでは、各組み合わせの購読数を数えたいのです。長いカンマ区切りの文字列ではなく、本当のリストのようなものが欲しいのです。
これをPythonで解決するのは簡単です。pandasやpolars、または単にPythonのネイティブなデータ構造を使用することができます。しかし、このようなオプションがないケースもあります。Dataチームがdbtのみを使用する会社であるかもしれません。または、より一般的な場合として、IT部門がローカル環境を厳密に制限している会社で働いているかもしれません。
どのような場合でも、SQLのみを使用できる場合、最も読みやすいコードと最も柔軟な結果を提供する解決策が必要です。これを実現するのは直感的ではありません。たとえば、この問題に直面したときに最初に思いついたのは、グループ化を定義に従って文字列を連結する関数GROUP_CONCATを使用することでした:
WITH subscriptions_grouped AS ( SELECT customer_id, GROUP_CONCAT(subscription) AS subscriptions FROM subscriptions GROUP BY customer_id )SELECT subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;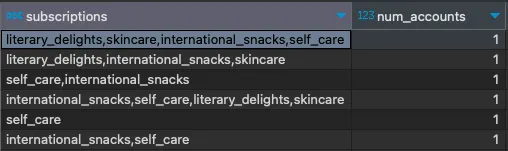
ご覧のように、集計は技術的には機能していますが、ビジネスロジックに沿って機能していません。最初と最後の行をご覧ください。サブスクリプションの組み合わせ「international_snacks, self_care」は、「self_care, international_snacks」と同じ組み合わせです。(2番目と4番目の行も同様です。)
この特定の問題を解決するために、GROUP_CONCAT内にORDER BY句を使用することができます:
WITH subscriptions_grouped AS ( SELECT customer_id, GROUP_CONCAT(subscription ORDER BY subscription) AS subscriptions FROM subscriptions GROUP BY 1 )SELECT subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;
しかし、これによって各組み合わせに含まれるサブスクリプションの数を数える問題が残ります。
方法がありますが、それは不必要に複雑で読みにくいだけでなく、いくつかの明らかでない落とし穴もあります。
MySQLでカンマ区切りの文字列の値の数を数える方法についてのクイック検索は、StackOverflowからの解決策を提示します。次のようなものです(subscriptions_grouped CTEは除外されています):
SELECT subscriptions, LENGTH(subscriptions) - LENGTH(REPLACE(subscriptions, ',', '')) + 1 AS num_subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;これは基本的にはカンマの数を数え、その結果に1を加えるものです。これは機能します。しかし、一目では理解しにくいだけでなく、潜在的なミスを引き起こす可能性もあります: LENGTHとCHAR_LENGTH関数は同じものを数えません。
おそらく推測できるように、この記事は私が似たような状況に陥ったときに仕事で遭遇した障害の詳細を説明しています。
最終的に、解決策はややハッキーでありながら、非常に理解しやすいワークアラウンドで、ネイティブのMySQL JSONデータ型を使用することで見つかりました。
MySQLのJSONデータ型の概要
MySQLのJSONデータ型はバージョン5.7.8で追加され、ストレージとモデリングの両方に非常に便利なユーティリティを提供します。
JSONデータ型の下に(公式には「JSONドキュメント」と呼ばれる)2つの異なるデータ構造があります:JSON配列とJSONオブジェクトです。
JSON配列は単純に配列(Pythonistaの場合はリスト)と考えることができます:角かっこ[ ]で囲まれた値で、カンマで区切られています。
- MySQLのJSON配列の例:
[“foo”, “bar”, 1, 2]
JSONオブジェクトはハッシュテーブル(またはPythonの場合は辞書)と考えることができます:カンマで区切られたキーと値で、波かっこ{ }で囲まれています。
- MySQLのJSONオブジェクトの例:
{“foo”: “bar”, 1: 2}
MySQLには、これらの形式に対処するために使用できる多くの関数がありますが、ほとんどがいかなる集計も行いません。
しかし、幸いにも、2つの関数があります。そして、いずれもJSONドキュメントを返すため、MySQLの組み込み関数を使用してその中の値にアクセスすることができます。
JSON_ARRAYAGG
MySQLの関数JSON_ARRAYAGGはGROUP_CONCATに非常に似ています。最大の違いは、JSON配列を返すことであり、再び、上記リンクのいくつかの便利な組み込み関数が付属していることです。
JSON配列データ型は、驚くほどの簡単さで2つの問題のうち1つを解決します:組み合わせでのサブスクリプションの数を確実に数える問題です。これは、JSON_LENGTH関数を使用して実現されます。構文は非常に簡単です:
SELECT JSON_LENGTH(JSON_ARRAY("foo", "bar", "hello", "world"));-- ここでは例として配列を簡単に作成するためにJSON_ARRAY関数を使用この文の結果は4です。生成されたJSON配列には4つの値があるためです。
しかし、サブスクリプションの組み合わせに戻りましょう。残念ながら、JSON_ARRAYAGGにはGROUP_CONCATにあるような順序付けの機能がありません。順序付けは、ベースクエリの前にCTEでさえ行っても、望ましい結果を返しません:
WITH subscriptions_ordered AS ( SELECT customer_id, subscription FROM subscriptions ORDER BY subscription ) , subscriptions_grouped AS ( SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptions, JSON_LENGTH(JSON_ARRAYAGG(subscription)) AS num_subscriptions FROM subscriptions_ordered GROUP BY customer_id )SELECT subscriptions, COUNT(*) AS num_accounts num_subscriptionsFROM subscriptions_groupedGROUP BY subscriptions;
JSON_LENGTH関数のおかげで、各組み合わせのサブスクリプションの数が表示されますが、順序の違いにより、同じような組み合わせも別々のものとして誤って扱われます。
値の順序付けにROW_NUMBERを使用する
ROW_NUMBERは、ウィンドウ関数でインデックスを作成します。インデックスは定義する必要があります。つまり、どこから始めるか、どのように増やすか(方向)、どこで終了するかを指定する必要があります。
これをROW_NUMBER関数に適用し、subscriptionフィールドで順序付けすることにより、これの簡単な例を見ることができます:
SELECT customer_id, subscription, ROW_NUMBER() OVER(ORDER BY subscription) AS alphabetical_row_numFROM subscriptions;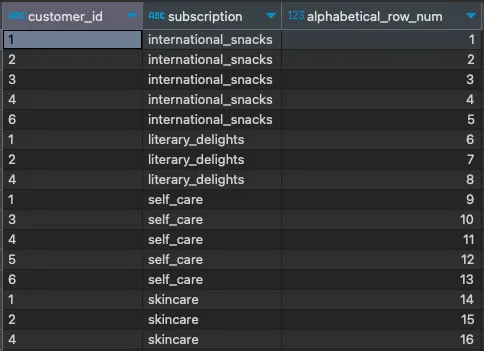
結果をよく見てください。クエリの末尾にORDER BYステートメントを使用しなかったにもかかわらず、データはOVER節で指定されたORDER BYに従って順序付けられています。
しかし、これはまだ正確には望んでいるものではありません。次に、ウィンドウ関数にPARTITION BY節を追加し、結果の順序付けが各顧客IDに関連付けられ(実際には制約され)るようにする必要があります。以下のように:
SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_orderFROM subscriptions;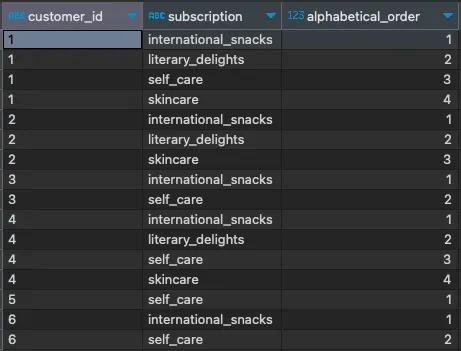
これがどこに向かっているかはおそらくわかるでしょう。
これらの結果に対してJSON_ARRAYAGG関数をCTEで実行すると、重複した組み合わせがROW_NUMBER関数によってアルファベット順に強制されるため、完全に同じように見えることがわかります:
WITH subscriptions_ordered AS ( SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_order FROM subscriptions )SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptionsFROM subscriptions_orderedGROUP BY 1ORDER BY 2;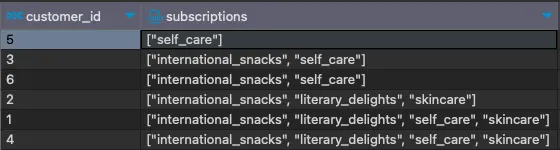
今や行番号を実行するものに続いてグループ化CTEを追加し、ベースクエリを変更する必要があります:
WITH subscriptions_ordered AS ( SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_order FROM subscriptions ) , subscriptions_grouped AS ( SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptions, JSON_LENGTH(JSON_ARRAYAGG(subscription)) AS num_subscriptions FROM subscriptions_ordered GROUP BY customer_id )SELECT subscriptions, COUNT(*) AS num_customers, num_subscriptionsFROM subscriptions_groupedGROUP BY subscriptionsORDER BY num_customers DESC;これにより、単一のサブスクリプションの組み合わせだけでなく、それらの組み合わせを購入した顧客の数と、それぞれの組み合わせを構成するサブスクリプションの数も正確に取得できます:

ボワッ!
まとめると
- 私たちは、異なる組み合わせのサブスクリプションを購入した顧客の数と、それぞれの組み合わせに含まれるサブスクリプションの数を知りたかった。これには2つの問題がありました:後者を最適に取得する方法と、正確に異なるサブスクリプションの組み合わせを生成する方法。
- 各組み合わせに含まれるサブスクリプションの数を取得するために、MySQLのJSON関数の1つである
JSON_ARRAYAGGを選びました。結果の集計はJSONデータ型として返され、JSON_LENGTH関数を使用できました。 - 次に、JSON配列内の値の順序付けを強制する必要がありました。これにより、重複する組み合わせが間違って異なるものに表示されることがありませんでした。これには、ベースクエリの前にCTEでウィンドウ関数
ROW_NUMBERを使用し、顧客IDでパーティション分割し、サブスクリプションをアルファベット順(昇順)で並べ替えました。 - これにより、正確に異なるサブスクリプションの組み合わせを集計することができました。そして、これにより、各組み合わせを購入した顧客数を簡単な
COUNT関数を使用して確認することができました。
お読みいただきありがとうございます! 🤓
お役に立てたら嬉しいです! SQL(方言に関係なく)での他の巧妙なトリック/回避策をご存知の場合は、ぜひ教えてください。 SQLは構造化データを変換するための事実上のリンガ・フランカとして長い間使われていますが、完璧ではありません。革新的で/または巧妙な実世界の課題に対する解決策について学ぶのはいつも楽しいです。 🔥
データエンジニアリングと分析のトピックについて定期的に執筆しており、常にできるだけ明確かつシンプルに書くことを目指しています。この記事で何か分かりにくい点があった場合は、コメントで教えてください。また、このような記事をもっと読みたい場合は、お気軽にフォローまたはLinkedInでつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
