MuZero ルールなしでGo、チェス、将棋、アタリをマスターする
'MuZero は、Go、チェス、将棋、アタリなどのゲームをルールなしでマスターする'
2016年、私たちは初めて人間を打ち破る人工知能(AI)プログラムであるAlphaGoを導入しました。2年後、その後継であるAlphaZeroは、ゼロから学習してGo、チェス、将棋をマスターしました。そして、私たちは自然誌に掲載された論文で、一般的なアルゴリズムの追求における大きな進歩となるMuZeroを説明しています。MuZeroは、未知の環境で勝利戦略を計画する能力により、ルールを教えられなくてもGo、チェス、将棋、Atariをマスターします。
長年にわたり、研究者たちは環境を説明するモデルを学習し、そのモデルを使用して最適な行動を計画できる方法を模索してきました。しかし、Atariなどのドメインでは、通常、ルールやダイナミクスが未知で複雑なため、ほとんどの手法が効果的に計画することに苦労してきました。
2019年に初めて発表された予備論文であるMuZeroは、計画において環境の重要な側面に焦点を当てたモデルを学習することで、この問題を解決します。AlphaZeroの強力な先読みツリーサーチと組み合わせることで、MuZeroはAtariのベンチマークで新たな最先端の結果を出し、同時にGo、チェス、将棋のクラシックな計画課題ではAlphaZeroと同等のパフォーマンスを達成します。これにより、MuZeroは強化学習アルゴリズムの能力における大きな飛躍を示しています。

未知のモデルへの一般化
計画する能力は人間の知能の重要な部分であり、問題を解決し、将来についての意思決定をすることができます。たとえば、暗い雲が出てきたら、雨が降ると予測し、外出する前に傘を持って行くと決めることができます。人間はこの能力を素早く学習し、新しいシナリオにも一般化することができます。我々のアルゴリズムにもこの特性を持たせたいと考えています。
研究者たちは、このAIの大きな課題に対処するために、主に2つのアプローチを使用してきました。先読み探索またはモデルベースの計画です。
AlphaZeroなどの先読み探索を使用するシステムは、チェッカー、チェス、ポーカーなどのクラシックなゲームで驚異的な成功を収めていますが、ゲームのルールや正確なシミュレータなどの環境のダイナミクスに関する知識を与えられることに依存しています。これにより、一般的に複雑で単純なルールに簡約できない、複雑な現実世界の問題に適用することが難しくなります。
モデルベースのシステムは、環境のダイナミクスの正確なモデルを学習し、それを使用して計画することを目指しています。しかし、環境のすべての側面をモデリングする複雑さのため、これらのアルゴリズムは視覚的に豊かなドメイン(Atariなど)では競争することができません。Atariでは、DQN、R2D2、Agent57などのモデルフリーシステムが最良の結果を出しています。名前が示すように、モデルフリーアルゴリズムは学習済みモデルを使用せず、次にどの行動が最適かを推定します。
MuZeroは、これまでのアプローチの制約を克服するために異なるアプローチを使用しています。MuZeroは環境全体をモデリングしようとするのではなく、エージェントの意思決定プロセスに重要な側面のみをモデル化します。傘があれば乾いたままでいられることを知ることは、空中の雨滴のパターンをモデル化するよりも役に立ちます。
具体的には、MuZeroは計画に重要な3つの要素をモデル化します:
- 価値:現在の位置はどれくらい良いですか?
- 方針:どの行動が最適ですか?
- 報酬:前回の行動はどれくらい良かったですか?
これらはすべて深層ニューラルネットワークを使用して学習し、MuZeroが特定の行動を取った場合に何が起こるかを理解し、それに応じて計画するために必要な要素です。



この手法にはもう1つの重要な利点があります。MuZeroは環境から新しいデータを収集する代わりに、学習済みモデルを繰り返し使用して計画を改善することができます。たとえば、Atariスイートでのテストでは、このバリアントであるMuZero Reanalyzeは、過去のエピソードで実行すべきだった計画を90%の時間で学習済みモデルを使用して再計画しました。
MuZeroのパフォーマンス
MuZeroの能力を評価するために、4つの異なるドメインを選びました。囲碁、チェス、将棋は、困難な計画問題におけるパフォーマンスを評価するために使用されました。一方、Atariスイートは視覚的に複雑な問題のベンチマークとして使用されました。すべての場合で、MuZeroは強化学習アルゴリズムの新たなステートオブジアートを確立し、Atariスイートではこれまでのすべてのアルゴリズムを上回り、囲碁、チェス、将棋ではAlphaZeroの超人的なパフォーマンスに追いつきました。

また、MuZeroが学習済みモデルを使用してより詳細な計画を行う能力もテストしました。まず、一手一手で勝敗の差が生じるクラシックな囲碁の精度計画の課題から始めました。計画時間を増やすと結果が改善されるという直感を確認するために、完全にトレーニングされたMuZeroの各手に対する計画時間の増加に伴う強さの増加を測定しました(下の左側のグラフを参照)。その結果、1/10秒から50秒までの各手の計画時間を増やすと、プレイの強さが1000 Elo(プレイヤーの相対的なスキルの尺度)以上向上することが示されました。これは、強いアマチュアプレイヤーと最強のプロプレイヤーの間の違いに似ています。
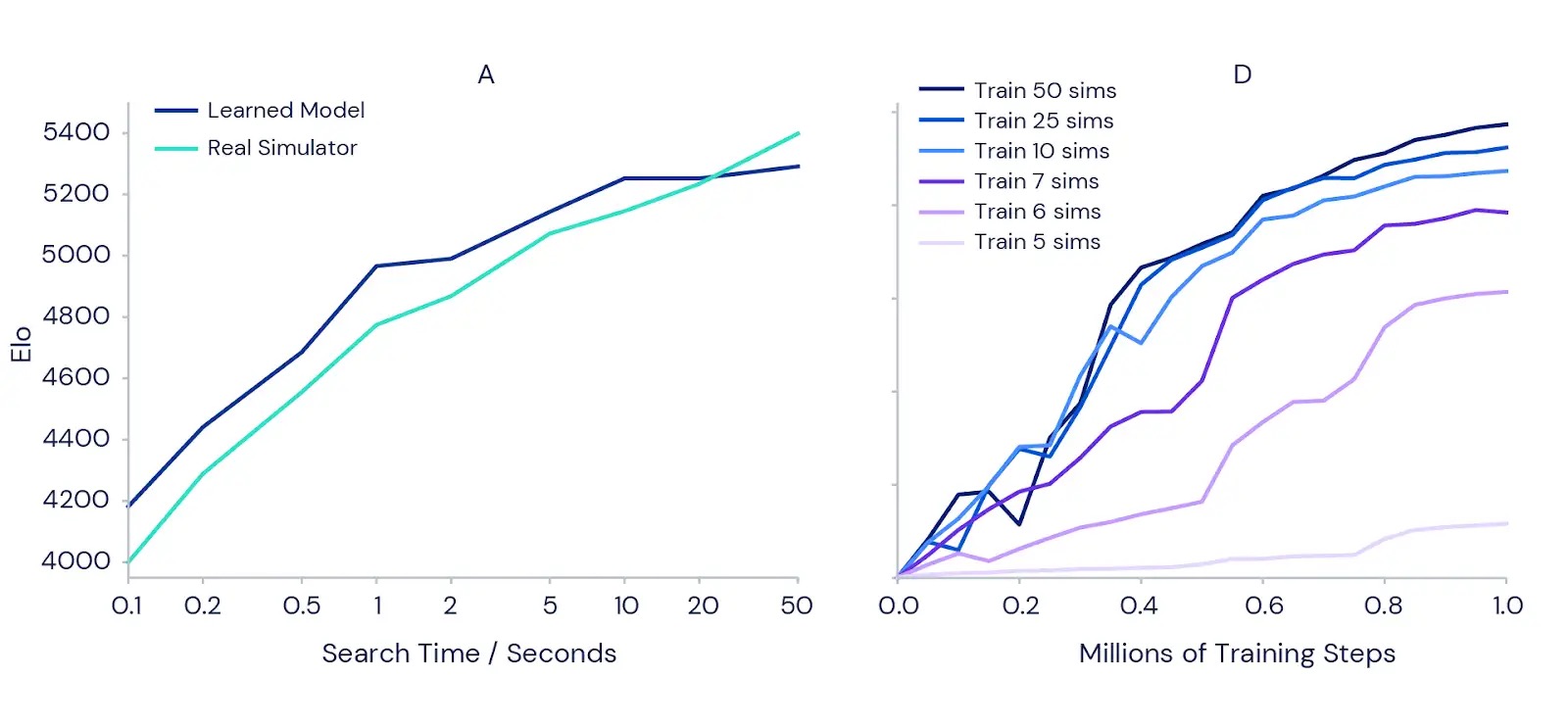
計画が訓練全体にも利益をもたらすかどうかをテストするために、私たちはAtariゲームのMs Pac-Man(上の右側のグラフ)で別々にトレーニングされたMuZeroのインスタンスを使用して一連の実験を行いました。それぞれは、移動ごとに考慮する計画シミュレーションの数を異なる範囲で設定することができました。範囲は5から50までです。結果は、各移動ごとの計画の量を増やすことで、MuZeroがより早く学習し、より良い最終的なパフォーマンスを達成することを確認しました。
興味深いことに、MuZeroにはMs Pac-Manのすべての利用可能なアクションをカバーするには小さすぎる6または7のシミュレーションのみを考慮することが許されていましたが、それでも良いパフォーマンスを達成しました。これは、MuZeroがアクションと状況の間を一般化することができ、効果的に学習するためにすべての可能性を徹底的に探索する必要はないことを示しています。
新たな地平線
MuZeroが環境のモデルを学習し、それを使用して計画を成功させる能力は、強化学習と汎用アルゴリズムの追求において重要な進歩を示しています。その前身であるAlphaZeroは、既に化学、量子物理学などの複雑な問題に適用されています。MuZeroの強力な学習と計画のアルゴリズムの背後にあるアイデアは、ロボット工学、産業システム、および他のルールが明確でない複雑な現実世界の環境への新たな挑戦に向けた道を開くかもしれません。
関連リンク:
- MuZero:Nature論文
- MuZeroの講演:NeurIPS(9分、2019年12月)、ICAPS(30分、2020年10月)
- MuZero:プレプリント| NeurIPS 2019ポスター
- AlphaGo:ブログ| 論文
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






