Informerを使用した多変量確率時系列予測
'Multivariate probabilistic time series forecasting using Informer'
![]()
イントロダクション
数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。
多変量確率時系列予測
確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。
高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。
Informer – 内部構造
バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。
- 正準自己注意の二次計算:バニラTransformerは、計算量がO ( T 2 D )のオーダーを持ちます。ここで、Tは時系列の長さ、Dは隠れ状態の次元です。長いシーケンス時系列予測(LSTF問題とも呼ばれます)では、これは非常に計算コストが高いかもしれません。この問題を解決するために、InformerはProbSparse attentionと呼ばれる新しい自己注意メカニズムを使用していますが、これはO ( T log T )の時間および空間計算量を持ちます。
- 層を積み重ねる際のメモリボトルネック: N個のエンコーダ/デコーダレイヤーを積み重ねる場合、バニラTransformerのメモリ使用量はO ( N T 2 )のオーダーを持ちます。これにより、長いシーケンスに対するモデルの容量が制限されます。Informerは、入力サイズを半分に削減するためのDistilling操作を使用して、メモリ使用量全体をO ( N ⋅ T log T )に減らします。
ご覧の通り、Informerモデルの動機は、Longformer(Beltagy et el., 2020)、Sparse Transformer(Child et al., 2019)などのNLP論文と類似しており、入力シーケンスが長い場合に自己注意メカニズムの二次計算量を削減することです。では、ProbSparse attentionとDistilling操作について、コードの例を交えて詳しく見ていきましょう。
ProbSparse Attention
ProbSparseの主なアイデアは、正準自己注意のスコアが長尾分布を形成していることです。ここで、「アクティブな」クエリとは、主要なアテンションに寄与するドット積を生成するクエリqiを指し、また、「レイジーな」クエリとは、取るに足らないアテンションを生成するドット積を形成するクエリを指します。ここで、qiとkiは、それぞれQおよびKのアテンション行列のi番目の行です。
「アクティブな」クエリと「レイジーな」クエリのアイデアに基づいて、ProbSparse attentionは「アクティブな」クエリを選択し、アテンションの重みを計算するために使用される縮小されたクエリ行列Qreducedを作成します。この計算はO ( T log T )で行われます。以下では、コードの例を交えて詳しく説明します。
次に、正規化された自己注意の公式を思い出してみましょう:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V
ここで、Q ∈ R L Q × d、K ∈ R L K × d、V ∈ R L V × d です。実際の計算では、クエリとキーの入力長は通常同じであり、つまり L Q = L K = T です。T は時系列の長さを表します。したがって、Q K T の乗算は O ( T 2 ⋅ d ) の計算量を持ちます。ProbSparse attention では、新しい Q r e d u c e 行列を作成し、次のように定義します:
ProbSparseAttention ( Q , K , V ) = softmax ( Q r e d u c e K T d k ) V
ここで、Q r e d u c e 行列は上位 u 個の「アクティブ」なクエリのみを選択します。ここで、u = c ⋅ log L Q であり、c は ProbSparse attention のサンプリングファクターハイパーパラメータです。Q r e d u c e 行列は上位 u 個のクエリのみを選択するため、そのサイズは c ⋅ log L Q × d であり、したがって Q r e d u c e K T の乗算は O ( L K log L Q ) = O ( T log T ) の計算量を持ちます。
これは良いですね!しかし、Q r e d u c e 行列を作成するためには、どのようにして上位 u 個の「アクティブ」なクエリを選択すればよいでしょうか?クエリのスパースさを測定するために、クエリスパースさ測定を定義しましょう。
クエリスパースさ測定
クエリスパースさ測定 M ( q i , K ) は、Q Q Q 内の上位 u 個の「アクティブ」なクエリ q i q_i q i を選択するために使用されます。理論的には、優勢な ⟨ q i , k i ⟩ \langle q_i,k_i \rangle ⟨ q i , k i ⟩ のペアが、図に示すように、クエリ q i q_i q i の確率分布を均一分布から「遠ざける」ことを促進します。したがって、実際のクエリ分布と均一分布の間の KL ダイバージェンスがスパースさ測定の定義に使用されます。
実際の測定は次のように定義されます:
M ( q i , K ) = max j ( q i k j T d ) − 1 L k ∑ j = 1 L k ( q i k j T d )
ここで理解する重要な点は、M(q_i, K)が大きいほど、クエリq_iはQ_{reduce}にあるべきであり、逆もまた然りです。
しかし、非二次時間で項q_ik_j^Tをどのように計算できるでしょうか?ほとんどの内積⟨q_i, k_i⟩は、トリビアルなアテンション(つまり、長い尾の分布特性)を生成するため、Kからランダムにサンプルしたキーのサブセットを作成するだけで十分です。このサブセットはコードでK_sampleと呼ばれます。
さあ、probsparse_attentionのコードを見てみましょう:
from torch import nn
import math
def probsparse_attention(query_states, key_states, value_states, sampling_factor=5):
"""
probsparse self-attentionを計算します。
入力形状:バッチ x 時間 x チャネル
注意:追加の`sampling_factor`入力があります。
"""
# ログを使用して入力のサイズを取得する
L_K = key_states.size(1)
L_Q = query_states.size(1)
log_L_K = np.ceil(np.log1p(L_K)).astype("int").item()
log_L_Q = np.ceil(np.log1p(L_Q)).astype("int").item()
# Kからスライスするサンプルのサブセットを計算し、Q_K_sampleを作成する
U_part = min(sampling_factor * L_Q * log_L_K, L_K)
# Q_K_sample(スパース性の測定におけるq_i * k_j^Tの項)を作成する
index_sample = torch.randint(0, L_K, (U_part,))
K_sample = key_states[:, index_sample, :]
Q_K_sample = torch.bmm(query_states, K_sample.transpose(1, 2))
# Q_K_sampleを使用してクエリのスパース性の測定を計算する
M = Q_K_sample.max(dim=-1)[0] - torch.div(Q_K_sample.sum(dim=-1), L_K)
# スパース性の測定において上位-uのクエリを見つけるためにuを計算する
u = min(sampling_factor * log_L_Q, L_Q)
M_top = M.topk(u, sorted=False)[1]
# Q_reduceをquery_states[:, M_top]として計算する
dim_for_slice = torch.arange(query_states.size(0)).unsqueeze(-1)
Q_reduce = query_states[dim_for_slice, M_top] # サイズ:c*log_L_Q x チャネル
# そして、同じように、canonicalと同じ
d_k = query_states.size(-1)
attn_scores = torch.bmm(Q_reduce, key_states.transpose(-2, -1)) # Q_reduce x K^T
attn_scores = attn_scores / math.sqrt(d_k)
attn_probs = nn.functional.softmax(attn_scores, dim=-1)
attn_output = torch.bmm(attn_probs, value_states)
return attn_output, attn_scores実装では、U_{part}に計算時にL_Qが含まれていることに注意してください(安定性の問題のために)。詳細については、この議論を参照してください。
できました!これはprobsparse_attentionの部分的な実装であることに注意してください。完全な実装は🤗 Transformersで見つけることができます。
蒸留
ProbSparse self-attentionのため、エンコーダの特徴マップには削除できる冗長性があります。したがって、蒸留操作はエンコーダ層間の入力サイズを半分に減らすために使用されます。実際には、Informerの「蒸留」操作は、各エンコーダ層の間にELUとMaxPool1dを適用する1D畳み込み層を追加するだけです。n番目のエンコーダ層の出力をX_nとすると、蒸留操作は次のように定義されます:
X_{n+1} = \textrm{MaxPool}(\textrm{ELU}(\textrm{Conv1d}(X_n)))
コードで見てみましょう:
from torch import nn
# ConvLayerはforward passでELUとMaxPool1dを適用するクラスです
def informer_encoder_forward(x_input, num_encoder_layers=3, distil=True):
# 畳み込み層を初期化する
if distil:
conv_layers = nn.ModuleList([ConvLayer() for _ in range(num_encoder_layers - 1)])
conv_layers.append(None)
else:
conv_layers = [None] * num_encoder_layers
# 各エンコーダ層の間にconv_layerを適用する
for encoder_layer, conv_layer in zip(encoder_layers, conv_layers):
output = encoder_layer(x_input)
if conv_layer is not None:
output = conv_layer(loutput)
return output各レイヤーの入力を2つずつ削減することで、メモリ使用量は O(N\cdot T \log T) になります(ただし、Nはエンコーダ/デコーダのレイヤー数、Tは時間ステップ数です)。これが私たちが求めていたものです!
Informerモデルは現在、🤗 Transformersライブラリで利用可能で、InformerModelとして簡単に呼び出すことができます。以下のセクションでは、このモデルをカスタムの多変量時系列データセットでトレーニングする方法を示します。
環境のセットアップ
まず、必要なライブラリをインストールしましょう:🤗 Transformers、🤗 Datasets、🤗 Evaluate、🤗 Accelerate、およびGluonTS。
後述するように、データの変換と特徴量の作成、適切なトレーニング、検証、テストバッチの作成にはGluonTSを使用します。
!pip install -q transformers datasets evaluate accelerate gluonts ujsonデータセットの読み込み
このブログ投稿では、Hugging Face Hubで利用可能なtraffic_hourlyデータセットを使用します。このデータセットは、Lai et al.(2017)が使用したSan Francisco Trafficデータセットを含んでいます。2015年から2016年の間にサンフランシスコ湾エリアの高速道路での道路占有率を示す862の時間ごとの時系列が含まれています。
このデータセットは、さまざまなドメインの時系列データセットのMonash Time Series Forecastingリポジトリの一部です。これは時系列予測のGLUEベンチマークと見なすことができます。
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "traffic_hourly")上記のように、データセットにはトレーニング、検証、テストの3つの分割が含まれています。
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
})各例にはいくつかのキーが含まれており、そのうちのstartとtargetが最も重要です。データセットの最初の時系列を見てみましょう。
train_example = dataset["train"][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])startは単に時系列の開始を示しており、targetには時系列の実際の値が含まれています。
モデルへの追加の入力として、時系列の値に時間関連の特徴量(例:「年の月」)を追加するために、startは役立ちます。データの頻度がhourlyであることが分かっているため、例えば2番目の値のタイムスタンプは2015-01-01 01:00:01、2015-01-01 02:00:01などです。
print(train_example["start"])
print(len(train_example["target"]))
>>> 2015-01-01 00:00:01
17448検証セットには、トレーニングセットと同じデータが含まれていますが、prediction_lengthよりも長い期間です。これにより、モデルの予測をグラウンドトゥルースと比較することができます。
テストセットは、検証セットと比較してprediction_lengthよりも長いデータです(または複数のローリングウィンドウでのテストには、トレーニングセットと比較してprediction_lengthの倍数の長さのデータが必要です)。
validation_example = dataset["validation"][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])初期値は対応するトレーニング例とまったく同じです。ただし、この例ではトレーニング例と比較してprediction_length=48(48時間、または2日)の追加の値があります。確認しましょう。
freq = "1H"
prediction_length = 48
assert len(train_example["target"]) + prediction_length == len(
dataset["validation"][0]["target"]
)これを可視化しましょう:
import matplotlib.pyplot as plt
num_of_samples = 150
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
validation_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()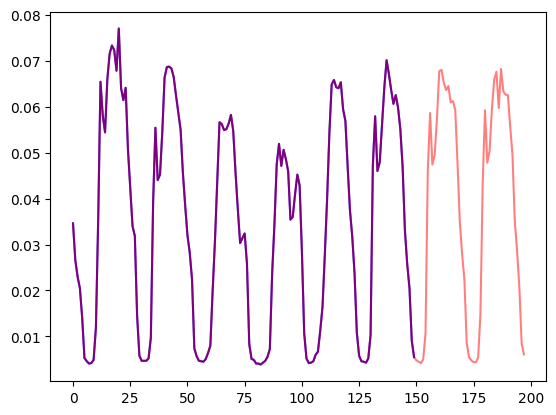
データを分割しましょう:
train_dataset = dataset["train"]
test_dataset = dataset["test"]startをpd.Periodに更新する
まず、各時系列のstartフィーチャーをデータのfreqを使用してpandasのPeriodインデックスに変換します:
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batchこれをオンザフライで行うために、datasetsのset_transform機能を使用します:
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))次に、GluonTSのMultivariateGrouperを使用してデータセットを多変量時系列に変換します。このグルーパーは、個々の1次元時系列を単一の2次元行列に変換します。
from gluonts.dataset.multivariate_grouper import MultivariateGrouper
num_of_variates = len(train_dataset)
train_grouper = MultivariateGrouper(max_target_dim=num_of_variates)
test_grouper = MultivariateGrouper(
max_target_dim=num_of_variates,
num_test_dates=len(test_dataset) // num_of_variates, # ローリングテストウィンドウの数
)
multi_variate_train_dataset = train_grouper(train_dataset)
multi_variate_test_dataset = test_grouper(test_dataset)ターゲットは2次元になりました。第1次元は変量の数(時系列の数)であり、第2次元は時系列の値(時間の次元)です:
multi_variate_train_example = multi_variate_train_dataset[0]
print("multi_variate_train_example["target"].shape =", multi_variate_train_example["target"].shape)
>>> multi_variate_train_example["target"].shape = (862, 17448)モデルの定義
次に、モデルのインスタンスを作成します。モデルはゼロからトレーニングされるため、ここではfrom_pretrainedメソッドではなく、configからランダムに初期化します。
モデルにはいくつかの追加パラメータを指定します:
prediction_length(この場合は48時間):これはInformerのデコーダが予測するホライズンです。context_length:モデルはcontext_length(エンコーダの入力)をprediction_lengthと同じに設定します。- 特定の周波数のラグ:これは効率的な「過去の値を現在の値に連結する」メカニズムです。たとえば、
Dailyの周波数の場合、[1, 7, 30, ...]のような過去の値を考慮するか、Minuteデータの場合は[1, 30, 60, 60*24, ...]などを考慮します。 - 時間特徴の数:この場合、
5になります。つまり、HourOfDay、DayOfWeek、…、Ageの特徴が追加されます(以下を参照)。
GluonTSが提供するデフォルトのラグを、指定された頻度(”hourly”)で確認しましょう:
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 23, 24, 25, 47, 48, 49, 71, 72, 73, 95, 96, 97, 119, 120,
121, 143, 144, 145, 167, 168, 169, 335, 336, 337, 503, 504, 505, 671, 672, 673, 719, 720, 721]これにより、各タイムステップごとに最大で721時間(約30日)まで遡ることができる追加の特徴量としての設定になります。しかし、結果として得られる特徴ベクトルのサイズはlen(lags_sequence)*num_of_variatesとなり、この場合は34480となります!これではうまくいかないので、自分自身で適切なラグを使用します。
また、GluonTSが提供するデフォルトの時間特徴量も確認しましょう:
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function hour_of_day at 0x7f3809539240>, <function day_of_week at 0x7f3809539360>, <function day_of_month at 0x7f3809539480>, <function day_of_year at 0x7f38095395a0>]この場合、4つの追加の特徴量があります。つまり、「時刻」、「曜日」、「月の日」、「年の日」です。これは、各タイムステップにこれらの特徴量をスカラー値として追加します。例えば、タイムスタンプ2015-01-01 01:00:01を考えてみましょう。4つの追加の特徴量は次のようになります:
from pandas.core.arrays.period import period_array
timestamp = pd.Period("2015-01-01 01:00:01", freq=freq)
timestamp_as_index = pd.PeriodIndex(data=period_array([timestamp]))
additional_features = [
(time_feature.__name__, time_feature(timestamp_as_index))
for time_feature in time_features
]
print(dict(additional_features))
>>> {'hour_of_day': array([-0.45652174]), 'day_of_week': array([0.]), 'day_of_month': array([-0.5]), 'day_of_year': array([-0.5])}注意してください、GluonTSでは時間と日が[-0.5, 0.5]の値でエンコードされています。詳細な情報についてはtime_featuresを参照してください。また、これらの4つの特徴量に加えて、後でデータ変換で「年齢」特徴量も追加します。
これでモデルを定義するために必要なものが揃いました:
from transformers import InformerConfig, InformerForPrediction
config = InformerConfig(
# 多変量設定では、input_sizeは各タイムステップの時系列の変数の数です
input_size=num_of_variates,
# 予測長:
prediction_length=prediction_length,
# コンテキスト長:
context_length=prediction_length * 2,
# 1週間前からコピーしたラグの値:
lags_sequence=[1, 24 * 7],
# 5つの時間特徴量(「hour_of_day」など)を追加します:
num_time_features=len(time_features) + 1,
# informerパラメーター:
dropout=0.1,
encoder_layers=6,
decoder_layers=4,
# 入力をnum_of_variates*len(lags_sequence)+num_time_featuresから次のサイズにプロジェクトします:
d_model=64,
)
model = InformerForPrediction(config)デフォルトでは、モデルは対角Student-t分布を使用します(が、これは設定可能です):
model.config.distribution_output
>>> 'student_t'変換の定義
次に、データの変換を定義します。特に、時間特徴量の作成に関する変換を定義します(データセットまたはユニバーサルな特徴量に基づいて)。
この場合も、GluonTSライブラリを使用します。変換のChainを定義します(これは画像のtorchvision.transforms.Composeに似たものです)。これにより、複数の変換を単一のパイプラインに組み合わせることができます。
from gluonts.time_feature import TimeFeature
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)以下の変換はコメントで注釈が付けられており、それらが行うことを説明しています。大まかに言えば、データセットの個々の時系列に対して反復処理を行い、フィールドや特徴量を追加/削除します。
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# 後で削除するフィールドのリストを作成する
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# ステップ1:指定されていない場合は静的/動的フィールドを削除する
[RemoveFields(field_names=remove_field_names)]
# ステップ2:データをNumPyに変換する(必要な場合)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# 多変量の場合、追加の次元を期待する:
expected_ndim=1 if config.input_size == 1 else 2,
),
# ステップ3:NaNを処理し、ゼロでターゲットを補完する
# およびマスクを返す(観測された値が含まれる)
# 観測された値に対してはtrue、NaNに対してはfalse
# デコーダはこのマスクを使用する(未観測の値に対しては損失が発生しない)
# xxxForPredictionモデル内のloss_weightsを参照してください
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# ステップ4:データセットの周波数に基づいて時間特徴量を追加する
# これらは位置符号化として機能する
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# ステップ5:もう1つの時間特徴量を追加する(単一の番号のみ)
# 時系列の値のライフの中でどこにあるかをモデルに伝える
# 種類の実行カウンタのようなもの
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# ステップ6:すべての時間特徴量をキーFEAT_TIMEに垂直にスタックする
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# ステップ7:HuggingFaceの名前と一致するように名前を変更する
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)InstanceSplitterを定義する
次に、トレーニング/検証/テストのためにデータセットからウィンドウをサンプリングするためにInstanceSplitterを作成します(時間とメモリの制約のため、モデルには値の完全な履歴を渡すことはできません)。
インスタンススプリッターは、データからランダムにcontext_lengthサイズのウィンドウとその後のprediction_lengthサイズのウィンドウをサンプリングし、該当するウィンドウの時間キーにpast_またはfuture_キーを追加します。これにより、valuesはpast_valuesとfuture_valuesのキーに分割され、それぞれエンコーダーとデコーダーの入力として使用されます。同様の処理がtime_series_fields引数で指定されたキーに対しても行われます:
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)データローダーの作成
次に、データローダーを作成します。これにより、(入力、出力)のペアである( past_values , future_values )のバッチを取得できます。
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# Trainingのインスタンスを初期化します
instance_splitter = create_instance_splitter(config, "train")
# インスタンススプリッターは、ターゲットの時間系列からランダムに
# コンテキスト長さ+ラグ+予測長さのウィンドウ(この場合は1つ)をサンプリングし、イテレータを返します。
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(
stream, is_train=True
)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# テストのインスタンススプリッターを作成し、エンコーダーには
# トレーニング中にのみ見られた最後のコンテキストウィンドウをサンプリングします。
instance_sampler = create_instance_splitter(config, "test")
# テストモードで変換を適用します
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=multi_variate_train_dataset,
batch_size=256,
num_batches_per_epoch=100,
num_workers=2,
)
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=multi_variate_test_dataset,
batch_size=32,
)最初のバッチをチェックしましょう:
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 264, 5]) torch.FloatTensor
past_values torch.Size([256, 264, 862]) torch.FloatTensor
past_observed_mask torch.Size([256, 264, 862]) torch.FloatTensor
future_time_features torch.Size([256, 48, 5]) torch.FloatTensor
future_values torch.Size([256, 48, 862]) torch.FloatTensor
future_observed_mask torch.Size([256, 48, 862]) torch.FloatTensor上記のように、エンコーダにはinput_idsとattention_maskをフィードしていません(NLPモデルの場合のように)、代わりにpast_values、past_observed_mask、past_time_features、およびstatic_real_featuresがフィードされます。
デコーダの入力はfuture_values、future_observed_mask、およびfuture_time_featuresで構成されます。 future_valuesは、NLPのdecoder_input_idsと同等と見なすことができます。
それぞれの詳細な説明については、ドキュメントを参照してください。
Forward Pass
先ほど作成したバッチで単一のフォワードパスを実行しましょう:
# フォワードパスを実行
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
print("Loss:", outputs.loss.item())
>>> Loss: -1071.5718994140625モデルが損失を返していることに注意してください。これは、デコーダがfuture_valuesを右に1つシフトしてラベルを持つため可能です。これにより、予測値とラベルの間で損失を計算することができます。損失は予測分布の真の値に対する負の対数尤度であり、負の無限大に近づきます。
また、デコーダはfuture_valuesテンソル内の予測する必要のある値を見ないために因果マスクを使用しています。
モデルのトレーニング
モデルのトレーニングの時間です!標準的なPyTorchのトレーニングループを使用します。
ここでは、モデル、オプティマイザ、およびデータローダを適切なdeviceに自動的に配置する🤗 Accelerateライブラリを使用します。
from accelerate import Accelerator
from torch.optim import AdamW
epochs = 25
loss_history = []
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(epochs):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
loss_history.append(loss.item())
if idx % 100 == 0:
print(loss.item())
>>> -1081.978515625
...
-2877.723876953125
# トレーニングの表示
loss_history = np.array(loss_history).reshape(-1)
x = range(loss_history.shape[0])
plt.figure(figsize=(10, 5))
plt.plot(x, loss_history, label="train")
plt.title("Loss", fontsize=15)
plt.legend(loc="upper right")
plt.xlabel("iteration")
plt.ylabel("nll")
plt.show()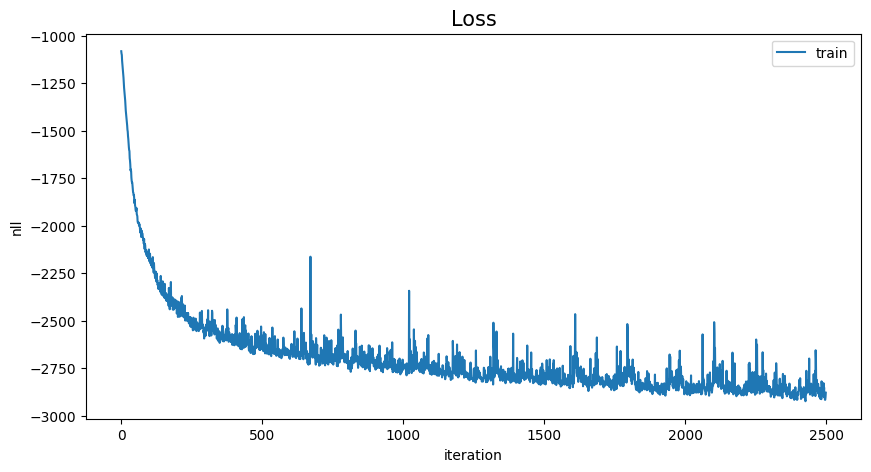
推論
推論時には、NLPモデルと同様に、generate()メソッドを使用することが推奨されています。
予測には、テストインスタンスサンプラーからデータを取得する必要があります。これにより、データセットの各時系列から直近のcontext_lengthサイズのウィンドウの値をサンプリングし、モデルに渡します。なお、デコーダには事前に分かっているfuture_time_featuresも渡します。
モデルは予測分布から一定数の値を自己回帰的にサンプリングし、それをデコーダに戻して予測結果を返します:
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())モデルは形状が(batch_size、number of samples、prediction length、input_size)のテンソルを出力します。
この場合、各時系列(バッチ内の各例、サイズは1)ごとに、次の48時間の100個の可能な値を取得します:
forecasts_[0].shape
>>> (1, 100, 48, 862)テストデータセット内のすべての時系列の予測を縦に積み重ねて取得します(テストセットに他の時系列がある場合のため):
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (1, 100, 48, 862)テストセット内の外れ値を含む正解値に対して予測結果を評価することができます。そのために、🤗 Evaluateライブラリを使用し、MASEおよびsMAPEメトリクスを計算します。
データセットの各時系列変数に対して両方のメトリクスを計算します:
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1).squeeze(0).T
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq),
)
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.1913437728068093
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.5322665081607634
plt.scatter(mase_metrics, smape_metrics, alpha=0.2)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()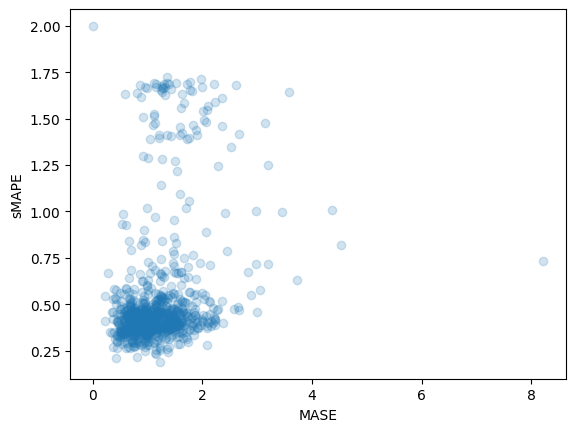
任意の時系列変数に対する予測を、正解データを基準としてプロットするために、次のヘルパー関数を定義します:
import matplotlib.dates as mdates
def plot(ts_index, mv_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=multi_variate_test_dataset[ts_index][FieldName.START],
periods=len(multi_variate_test_dataset[ts_index][FieldName.TARGET]),
freq=multi_variate_test_dataset[ts_index][FieldName.START].freq,
).to_timestamp()
ax.xaxis.set_minor_locator(mdates.HourLocator())
ax.plot(
index[-2 * prediction_length :],
multi_variate_test_dataset[ts_index]["target"][mv_index, -2 * prediction_length :],
label="実測値",
)
ax.plot(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(axis=0),
label="平均値",
)
ax.fill_between(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(0)
- forecasts[ts_index, ..., mv_index].std(axis=0),
forecasts[ts_index, ..., mv_index].mean(0)
+ forecasts[ts_index, ..., mv_index].std(axis=0),
alpha=0.2,
interpolate=True,
label="+/- 1-std",
)
ax.legend()
fig.autofmt_xdate()例:
plot(0, 344)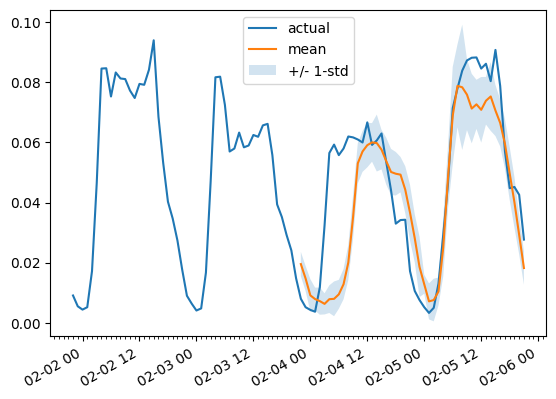
結論
他のモデルと比較してどうなのでしょうか? Monash Time Series Repositoryには、テストセットのMASEメトリクスの比較表があります:
見てわかる通り、多変量予測は通常、単変量予測よりも悪い結果となります。その理由は、クロスシリーズの相関/関係を推定する難しさにあります。推定によって追加される分散は、予測結果に悪影響を及ぼすか、モデルが見かけの相関を学習する原因となります。詳しくは、この論文をご参照ください。多変量モデルは、多くのデータでトレーニングされた場合にうまく機能する傾向があります。
したがって、バニラのTransformerがここで最も優れたパフォーマンスを発揮します!将来的には、これらのモデルを一元化した場所でより良いベンチマークを行い、いくつかの論文の結果を再現しやすくすることを期待しています。さらなる情報をお楽しみに!
リソース
Informerのドキュメントと、このブログポストの上部にリンクされているサンプルノートブックをチェックすることをおすすめします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






