マルチモーダル医療AI
Multimodal Healthcare AI
Google ResearchのHealth AI部門の責任者であるGreg Corradoと、Engineering and ResearchのVPであるYossi Matiasによって投稿されました。
医学は本質的に多様なモダリティを持つ分野です。医療を提供する際、臨床医は医学画像、臨床ノート、検査結果、電子保健記録、ゲノミクスなど、さまざまなモダリティのデータを解釈することが日常的に行われます。過去10年ほどで、AIシステムは特定のタスクや特定のモダリティにおいて専門家レベルのパフォーマンスを達成してきました。CTスキャンを処理するAIシステム、高倍率の病理スライドを分析するAIシステム、希少な遺伝子の変異を探すAIシステムなどがあります。これらのシステムの入力は画像などの複雑なデータであり、通常は離散的なグレードや密な画像セグメンテーションマスクの形で構造化された出力を提供します。同時に、大規模言語モデル(LLM)の能力と機能は非常に高度になり、医学の知識を理解し、明瞭な言語で解釈および応答することを示しています。しかし、これらの能力を組み合わせてこれらの情報源から情報を利用する医療AIシステムを構築するにはどうすれば良いのでしょうか?
本日のブログ投稿では、LLMに多様なモダリティの能力をもたらすアプローチの範囲を概説し、最近の研究論文で示されている多様なモダリティの医療LLMの構築の実現可能性についての興味深い結果を共有します。これらの論文は、LLMに新たなモダリティを導入する方法、最先端の医学画像基盤モデルを会話型LLMに組み込む方法、そして真の汎用的な多様なモダリティの医療AIシステムの構築への初歩的な取り組みについて説明しています。成功すれば、多様なモダリティの医療LLMは、専門医療、医学研究、消費者向けアプリケーションを横断する新しい支援技術の基盤となる可能性があります。私たちの以前の研究と同様に、これらの技術を医療コミュニティや医療エコシステムとの協力による慎重な評価の必要性を強調します。
アプローチの範囲
最近の数ヶ月間には、多様なモダリティのLLMの構築に関するいくつかの手法が提案されています[1, 2, 3]。さらに新しい手法がしばらくの間続々と登場することでしょう。医療AIシステムに新しいモダリティをもたらす機会を理解するために、3つの広義に定義されたアプローチを考えてみましょう:ツールの利用、モデルの組み込み、汎用システム。
- 「AnyLocによる最新のビジュアル位置認識(VPR)の汎用方法について紹介します」
- 「このAIニュースレターが必要なすべて #59」
- 「シャッターストックがNVIDIAピカソとともに生成AIを3Dシーンの背景に導入」
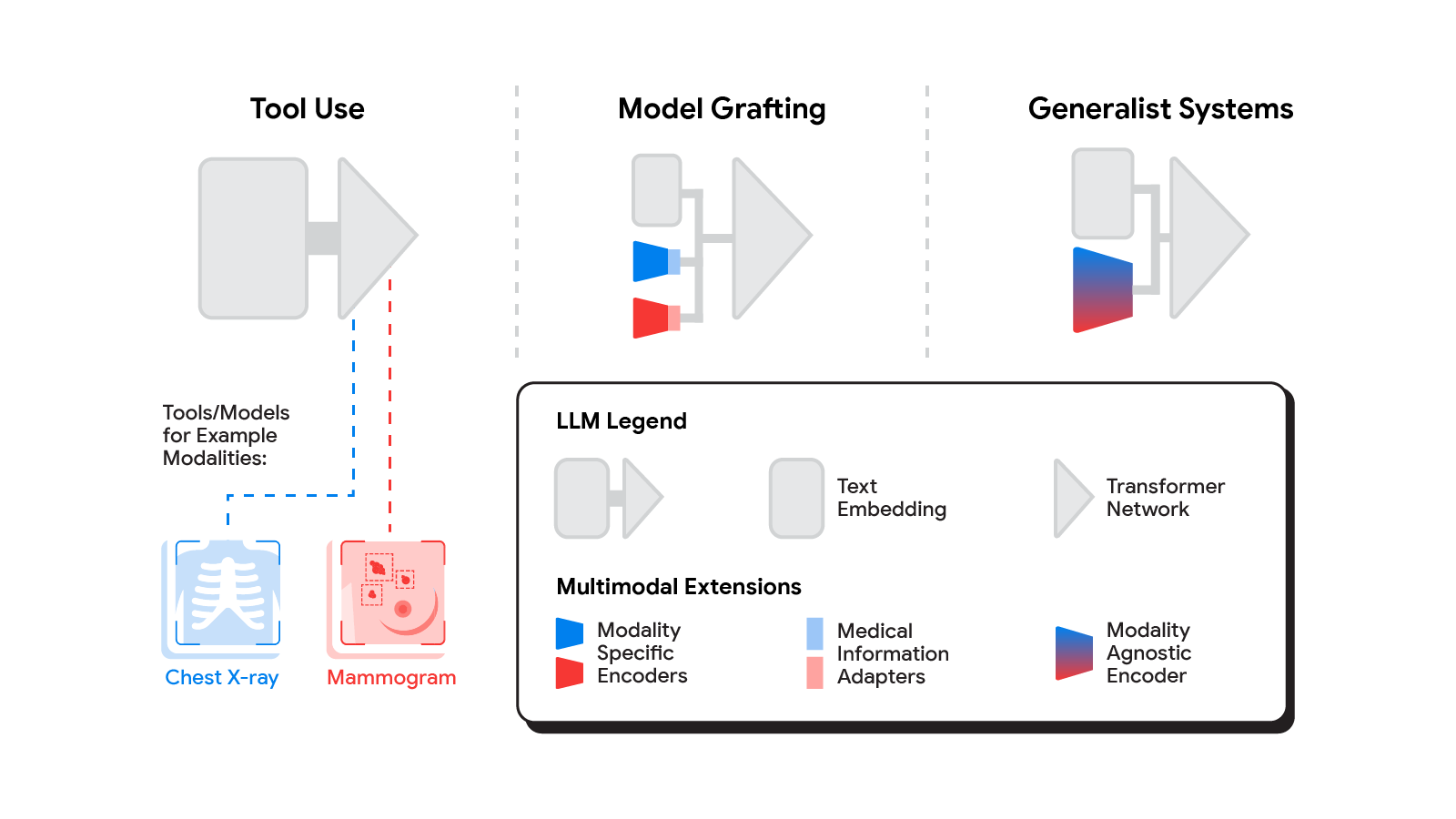 |
| 多様なモダリティのLLMを構築するアプローチの範囲は、LLMが既存のツールやモデルを使用することから、ドメイン固有のコンポーネントをアダプタとして利用すること、多様なモダリティのモデルを共同モデリングすることまで広がっています。 |
ツールの利用
ツールの利用のアプローチでは、中央の医療LLMは各タスクに最適化されたソフトウェアサブシステム(ツール)によるさまざまなモダリティのデータの解析を外部に委託します。ツールの利用の一般的な例は、LLMに計算を自身で行うのではなく、電卓を使用することを教えることです。医療の場合、胸部X線を処理する医療LLMは、その画像を放射線学AIシステムに転送し、その応答を統合することができます。これは、サブシステムが提供するアプリケーションプログラミングインターフェース(API)を介して行うこともできますし、より幻想的には、異なる専門分野を持つ2つの医療AIシステムが会話をすることもできます。
このアプローチにはいくつかの重要な利点があります。サブシステム間の最大の柔軟性と独立性が実現され、ヘルスシステムはサブシステムの検証されたパフォーマンス特性に基づいてテックプロバイダ間で製品を組み合わせることができます。さらに、サブシステム間の人間が読めるコミュニケーションチャネルは、監査可能性とデバッグ可能性を最大化します。ただし、独立したサブシステム間のコミュニケーションをうまく行うことは難しい場合があり、情報の伝達が狭まったり、誤ったコミュニケーションや情報の損失のリスクが発生する可能性があります。
モデルの組み込み
より統合されたアプローチとして、各関連する領域に特化したニューラルネットワークを取り、それをLLMに直接組み込むことが考えられます。つまり、ビジュアルモデルを核となる推論エージェントに組み込むことです。ツールの利用とは異なり、モデルの組み込みでは、研究者は開発中に特定のモデルを使用、改良、または開発することができます。Google Researchの最近の2つの論文では、これが実現可能であることを示しています。ニューラルLLMは通常、テキストを最初に単語のベクトル埋め込み空間にマッピングすることでテキストを処理します。両論文は、新しいモダリティのデータを既にLLMに馴染みのある入力単語埋め込み空間にマッピングするというアイデアに基づいています。最初の論文「個別データに基づく健康な多様なモダリティのLLM」では、イギリスバイオバンクでの喘息リスク予測が改善されることを示しています。このために、まず、スパイログラム(呼吸能力を評価するために使用されるモダリティ)を解釈するためのニューラルネットワーク分類器を訓練し、そのネットワークの出力をLLMへの入力として適応させることで実現します。
2つ目の論文、「ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders」は、同じアプローチを採用していますが、これを放射線学の全画像エンコーダモデルに適用しています。胸部X線の理解のための基礎モデルから始めて、このモダリティでさまざまな分類器を構築するための良い基盤であることがすでに示されている基礎モデルの最上位層の出力を、LLMの入力埋め込み空間のトークンの系列として再表現する軽量の医療情報アダプタのトレーニングについて説明しています。ビジュアルエンコーダや言語モデルのファインチューニングは行われなかったにもかかわらず、結果として得られるシステムは、意味検索やビジュアルクエスチョンアンサリングなどに訓練されていなかった能力を示します。
 |
| モデルグラフティングへのアプローチはいくつかの利点があります。アダプタレイヤーのトレーニングには比較的控えめな計算リソースが使用されますが、データドメインごとに高度に最適化され検証された既存のモデルをLLMが利用することができます。エンコーダ、アダプタ、LLMのコンポーネントに問題を分割することは、このようなシステムを開発および展開する際に個々のソフトウェアコンポーネントのテストとデバッグを容易にすることもできます。対応するデメリットは、専門のエンコーダとLLMの間の通信が人間に読み取れない形式(高次元ベクトルの系列)であること、およびグラフティング手順が、ドメイン固有のエンコーダだけでなく、それらのエンコーダの各改訂版に対して新しいアダプタを構築する必要があることです。 |
モダリティの特化システム
汎用システム
マルチモーダル医療AIへの最も急進的なアプローチは、すべての情報源から情報を吸収することができる統合された完全な汎用システムを構築することです。この領域での私たちの3番目の論文「Towards Generalist Biomedical AI」では、各データモダリティごとに別々のエンコーダとアダプタを持つのではなく、PaLM-Eという最近発表されたマルチモーダルモデルを利用しています。このモデル自体は単一のLLM(PaLM)と単一のビジョンエンコーダ(ViT)の組み合わせです。このセットアップでは、テキストと表形式のデータモダリティはLLMのテキストエンコーダによってカバーされていますが、他のすべてのデータは画像として扱われ、ビジョンエンコーダに供給されます。
 |
| Med-PaLM Mは、臨床言語、画像、およびゲノミクスを含むバイオメディカルデータを柔軟にエンコードおよび解釈する大規模なマルチモーダル生成モデルです。 |
私たちは、論文で説明されている医療データセット上のモデルのパラメータの完全なセットをファインチューニングすることで、PaLM-Eを医療領域に特化させます。その結果、得られる汎用的な医療AIシステムは、Med-PaLMのマルチモーダルバージョンであり、Med-PaLM Mと呼ばれます。柔軟なマルチモーダルシーケンス-シーケンスアーキテクチャにより、さまざまなタイプのマルチモーダルバイオメディカル情報を単一のインタラクションで交差させることができます。私たちの知る限りでは、これはタスクごとに異なるモデルウェイトを使用せずに、マルチモーダルバイオメディカルデータを解釈し、さまざまなタスクを処理するための単一の統一モデルの最初のデモンストレーションです(詳細な評価は論文に記載されています)。
このマルチモーダリティへの総合的なアプローチは、私たちが説明するアプローチの中でも最も野心的で同時に最も洗練されたものです。原理的には、この直接的なアプローチはモダリティ間の柔軟性と情報伝達を最大化します。互換性を維持するためのAPIやアダプタレイヤーの増加もなく、総合的なアプローチはおそらく最もシンプルな設計であると言えます。しかし、その同じ洗練さがいくつかの欠点の源にもなっています。計算コストが通常よりも高くなることがあり、広範なモダリティを対象とする単一のビジョンエンコーダによって、ドメインの特殊化やシステムのデバッグ可能性が低下する可能性があります。
マルチモーダル医療AIの現実
医療におけるAIの最大の利点を得るためには、予測AIでトレーニングされた専門システムの強みと、生成AIによって可能になる柔軟性を組み合わせる必要があります。どのアプローチ(またはアプローチの組み合わせ)がフィールドで最も有用であるかは、まだ評価されていない多くの要素に依存します。一般化モデルの柔軟性とシンプルさは、モデルの移植やツールの使用に比べてどれだけ価値があるのでしょうか?特定の実世界のユースケースに対して最高品質の結果を提供するのはどのアプローチですか?医学研究や医学教育のサポートと、医療実践の補完とでは、好ましいアプローチは異なるのでしょうか?これらの問いに答えるには、継続的な厳密な経験的研究と、医療提供者、医療機関、政府機関、医療産業のパートナーとの直接の協力が必要です。一緒に答えを見つけることを楽しみにしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- NVIDIA NeMoを使ったスタートアップが生成AIの成功ストーリーをスタートさせました
- 「グリーンAIへの道:ディープラーニングモデルを製品化する際に効率的にする方法」
- 「生成型AI:CHATGPT、Dall-E、Midjourneyなどの背後にあるアイデア」
- ピクセルを説明的なラベルに変換する:TensorFlowを使ったマルチクラス画像分類のマスタリング
- 「Pythonデコレーターは開発者のエクスペリエンスをスーパーチャージします🚀」
- 「オーディオ機械学習入門」
- 「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク






