「マルチタスクアーキテクチャ:包括的なガイド」
Multi-Task Architecture Comprehensive Guide
リアルタイムマルチタスク推論のための軽量モデル
イントロダクション
多くのことをするために、深層ニューラルネットワークを訓練する方法について考えたことはありますか?そのようなモデルはマルチタスクアーキテクチャと呼ばれ、各タスクに個別のモデルを使用する従来のアプローチよりも利点があります。マルチタスクアーキテクチャは、複数のタスクを同時に実行するモデルまたはモデルセットを訓練する一般的なアプローチであるマルチタスクラーニングのサブセットです。
この記事では、分類と回帰のタスクを同時に実行するための単一のモデルの訓練方法について学びます。この記事のコードはGitHubで見つけることができます。以下は概要です。
- 動機 — なぜこれをするのか?
- アプローチ — どのようにしてこれを行うのか?
- モデルアーキテクチャ
- トレーニングアプローチ
- 推論 — パフォーマンスを確認し、興味深い失敗から学ぶ
- 結論
動機
なぜ軽量モデルを使用したいのでしょうか?パフォーマンスは低下しませんか?エッジに展開しない場合、できるだけ大きなモデルを使用すべきではないでしょうか?
エッジアプリケーションでは、低消費電力でリアルタイム推論を実行するために軽量モデルが必要です。他のアプリケーションでも利点がありますが、どのような利点があるのでしょうか?軽量モデルの見過ごされがちな利点は、計算要件の低さです。一般的に、これによりサーバーの使用量が減少し、電力消費量が削減されます。これは費用の削減と炭素排出量の低下という全体的な効果をもたらします。後者はAIの将来において重要な問題となる可能性があります。
軽量モデルは、電力消費量が少なくなることにより、コストを削減し炭素排出量を低下させるのに役立ちます
これらすべてを考慮しても、マルチタスクアーキテクチャはツールボックスの中の単なるツールです。プロジェクトの要件を考慮して、どのツールを使用するかを決定する前に、よく考えるべきです。さあ、これらのうちの1つを訓練する例について詳しく見てみましょう!
アプローチ
マルチタスクアーキテクチャを構築するために、この論文のアプローチを大まかにカバーします。この論文では、セグメンテーションと深さ推定のために単一のモデルが同時に訓練されました。基本的な目標は、これらのタスクを高速かつ効率的に実行することであり、パフォーマンスの損失を許容できるトレードオフがあります。マルチタスクラーニングでは、通常、類似したタスクをグループ化します。トレーニング中には、モデルの学習を支援する補助的なタスクを追加することもできますが、推論中には使用しないことも選択できます[1, 2]。単純化のため、トレーニング中には補助的なタスクは使用しません。
深さとセグメンテーションは、両方とも密な予測タスクであり、類似点があります。たとえば、単一のオブジェクトの深さは、オブジェクトのすべての領域で一貫している可能性があり、非常に狭い分布を形成します。主なアイデアは、各個別のオブジェクトには独自の深さ値があるべきであり、深さマップを見るだけで個別のオブジェクトを認識できるはずです。同様に、セグメンテーションマップを見るだけで同じ個別のオブジェクトを認識できるはずです。いくつかの外れ値が存在する可能性はありますが、この関係が成立すると仮定します。
データセット
City Scapesデータセットを使用して、(左カメラの)入力画像のセグメンテーションマスクと深さマップを提供します。セグメンテーションマップには、19クラス+1の未分類カテゴリを含めた標準のトレーニングラベルを使用します。
深さマップの準備 — デフォルトの視差
SteroSGBMで作成された視差マップはCityScapesのウェブサイトから簡単に入手できます。視差は、各ステレオカメラの視点から見たオブジェクト間のピクセルの差を示し、深さの逆比例です。深さは以下の式で計算できます:

ただし、デフォルトの視差マップは、無限の深さに対応する多くの穴と、常に表示される自己車両の一部がノイズを含んでいます。これらの視差マップをクリーニングするための一般的なアプローチは次のとおりです:
- 下部の20%と左端および上端の一部を切り取る
- 元のスケールにリサイズする
- スムージングフィルタを適用する
- インペインティングを行う
視差をクリーニングした後、深度を計算することができ、次のような結果となります:
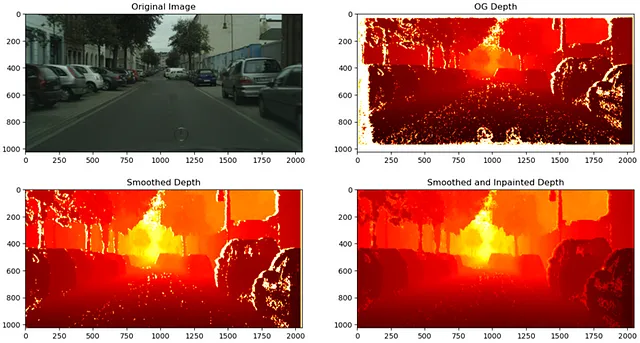
このアプローチの詳細は、この投稿の範囲外ですが、興味がある場合はYouTubeでのビデオ解説をご覧ください。
クロップとリサイズのステップにより、視差(および深度)マップは入力画像と完全に一致しなくなります。この問題を修正するために、入力画像でも同じクロップとリサイズを行うことができますが、新しいアプローチを試してみることにしました。
深度マップの準備 ― CreStereo視差
私たちは、CreStereoを使用して左右の画像から高品質な視差マップを生成することを試しました。CreStereoは、ステレオ画像ペアから滑らかな視差マップを予測することができる高度なモデルです。このアプローチは、知識蒸留として知られるパラダイムを導入しており、CreStereoは教師ネットワークであり、私たちのモデルは学習ネットワーク(少なくとも深度推定の場合)となります。このアプローチの詳細は、この投稿の範囲外ですが、興味がある場合はYouTubeのリンクをご覧ください。
一般的に、CreStereoの深度マップはノイズがほとんどないため、クロップやリサイズの必要はありません。ただし、セグメンテーションマスクに存在する自己車両が一般化に問題を引き起こす可能性があるため、すべてのトレーニング画像から下部の20%を削除しました。以下はトレーニングサンプルの例です:

データがそろったので、アーキテクチャを見てみましょう。
モデルのアーキテクチャ
[1]に従って、アーキテクチャはMobileNetバックボーン/エンコーダ、LightWeight RefineNetデコーダ、および各個別のタスク用のヘッドで構成されます。全体的なアーキテクチャは、図3に示されています。
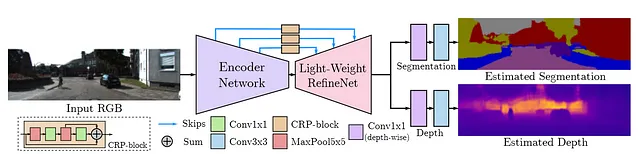
エンコーダ/バックボーンには、MobileNetV3を使用し、スキップ接続を1/4、1/8、1/16、および1/32の解像度でLightWeight Refine Netに渡します。最後に、各タスクに対応するヘッドに出力が渡されます。このアーキテクチャには、さらにタスクを追加することもできることに注意してください。
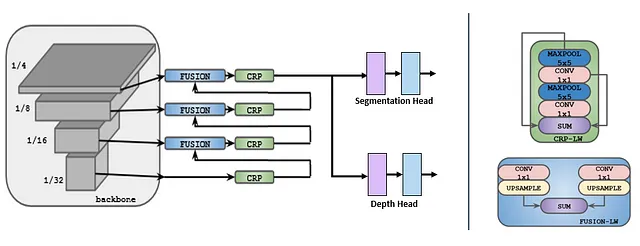
エンコーダの実装には、事前学習済みのMobileNetV3エンコーダを使用し、MobileNetV3エンコーダをカスタムのPyTorchモジュールに渡します。そのforward関数の出力は、LightWeight Refine Netへの入力用のスキップ接続のParameterDictです。以下のコードスニペットは、これを行う方法を示しています。
class MobileNetV3Backbone(nn.Module): def __init__(self, backbone): super().__init__() self.backbone = backbone def forward(self, x): """ MobileNetV3バックボーンの特徴抽出レイヤーを通過させる入力を過ぎる 接続を追加するレイヤー - 1:1/4の解像度 - 3:1/8の解像度 - 7、8:1/16の解像度 - 10、11:1/32の解像度 """ skips = nn.ParameterDict() for i in range(len(self.backbone) - 1): x = self.backbone[i](x) # スキップ接続の出力を追加 if i in [1, 3, 7, 8, 10, 11]: skips.update({f"l{i}_out" : x}) return skipsLightWeight RefineNetデコーダは、[1]で実装されたものと非常に似ていますが、MobileNetV2と互換性を持つようにいくつかの変更が加えられています。また、デコーダ部分はセグメンテーションとデプスのヘッドで構成されていることに注意してください。モデルの完全なコードはGitHubで利用可能です。モデルを次のように組み立てることができます:
from torchvision.models import mobilenet_v3_small mobilenet = mobilenet_v3_small(weights='IMAGENET1K_V1')encoder = MobileNetV3Backbone(mobilenet.features)decoder = LightWeightRefineNet(num_seg_classes)model = MultiTaskNetwork(encoder, freeze_encoder=False).to(device)トレーニングアプローチ
トレーニングは3つのフェーズに分かれており、最初のフェーズは1/4の解像度、2番目のフェーズは1/2の解像度、最後のフェーズはフル解像度で行われます。エンコーダの重みを凍結すると良い結果が得られないため、すべての重みが更新されました。
変換
各フェーズでは、ランダムなクロップリサイズ、カラージッター、ランダムフリップ、および正規化を行います。左側の入力画像は、標準のイメージネットの平均値と標準偏差で正規化されます。
デプス変換
一般的に、深度マップには主に小さな値が含まれています。なぜなら、深度マップに含まれる情報の大部分は、カメラに近いオブジェクトや表面から構成されるためです。深度マップの深度は、低い値を中心に集中しているため(下図の左を参照)、ニューラルネットワークによって効果的に学習されるために変換する必要があります。深度マップは0から250の範囲でクリップされます。これは、大きな距離のステレオ視差/深度データは通常信頼性が低いため、これを破棄する方法が必要なためです。次に、自然対数を取り、数値の範囲を狭めるために5で割ります。詳細については、このノートブックを参照してください。
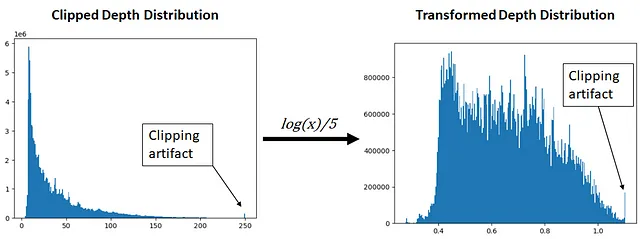
正直なところ、深度データを変換する最良の方法がわかりませんでした。もし他にいい方法があるか、もしくは異なる方法で行う場合は、コメントで詳細を教えていただけると嬉しいです 🙂
損失関数
損失関数は、セグメンテーションにはクロスエントロピー損失を、デプス推定には平均二乗誤差を使用しています。これらを重みづけなしで合算し、共同で最適化しています。
学習率
最大値が5e-4のワンサイクルコサインアニール学習率を使用し、1/4の解像度で150エポックトレーニングします。トレーニングに使用されるノートブックはこちらにあります。
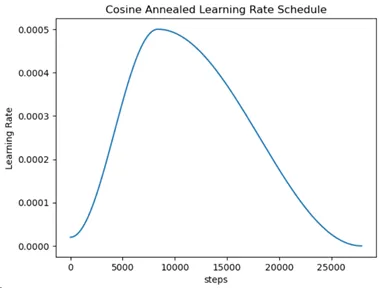
次に、1/2の解像度で25エポック、さらにフル解像度で別の25エポックを学習率5e-6で微調整します。なお、解像度を増やして微調整するたびに、バッチサイズを減らす必要がありました。
推論
推論では、入力画像を正規化し、モデルを通じて順方向に処理します。図6には、検証データとテストデータの両方からのトレーニング結果が示されています。
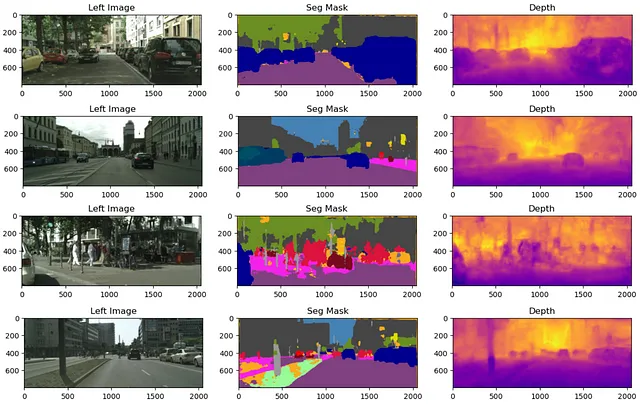
一般的に、モデルは画像内に大きなオブジェクトがある場合にセグメント化や深度の推定が可能です。しかし、歩行者などのより細かい詳細なオブジェクトが存在すると、モデルは完全にそれらをセグメント化するのに苦労する傾向があります。モデルはある程度の正確さで深度を推定することができます。
興味深い失敗例
図6の下部は、画像の左側にある街灯を完全にセグメント化できなかった興味深い失敗例を示しています。セグメンテーションは街灯の下半分しかカバーしておらず、深度は街灯の下半分が上半分よりもはるかに近いことを示しています。深度の失敗は、下部ピクセルが一般的により近い深度に対応しているというバイアスに起因する可能性があります。ピクセル500周辺の水平線に注目してください。近くのピクセルと遠くのピクセルの間には明確な境界があります。このバイアスがモデルのセグメンテーションタスクに漏れた可能性があります。このようなタスクの漏洩は、マルチタスクモデルのトレーニング時に考慮する必要があります。
マルチタスク学習では、1つのタスクのトレーニングデータが別のタスクのパフォーマンスに影響を与える可能性があります
深度分布
予測された深度が真の深度と比較してどのように分布しているかを確認してみましょう。簡単のために、真の/予測されたフル解像度の深度マップペアのサンプルを94個使用します。
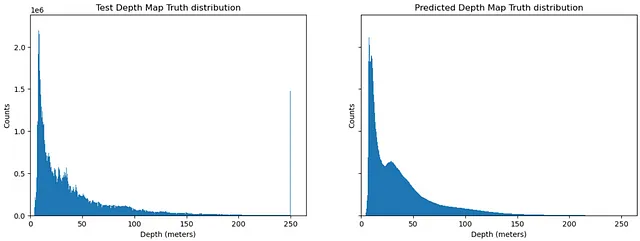
モデルは、ピークが約4の分布とピークが約30の分布の2つを学習したようです。クリッピングによるアーティファクトは影響を与えないようです。全体の分布には、遠くの深度データが画像の一部にしか含まれないという特徴的な長いテールが含まれています。
予測された深度の分布は、真の深度よりもはるかにスムーズです。真の深度の荒さは、各オブジェクトが似たような深度値を含んでいることから生じる可能性があります。この情報を利用して、モデルにこのパラダイムに従うように強制するための正則化を適用することが可能かもしれませんが、それは別の機会になります。
ボーナス:推論速度
これは速度を重視した軽量モデルなので、GPU上での推論速度を見てみましょう。以下のコードはこの記事から修正されました。このテストでは、入力画像を400×1024にスケーリングダウンしました。
# find optimal backend for performing convolutions torch.backends.cudnn.benchmark = True # rescale to half sizerescaled_sample = Rescale(400, 1024)(sample)rescaled_left = rescaled_sample['left'].to(DEVICE)# INIT LOGGERSstarter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)repetitions = 300timings=np.zeros((repetitions,1))#GPU-WARM-UPfor _ in range(10): _, _ = model(rescaled_left.unsqueeze(0))# MEASURE PERFORMANCEwith torch.no_grad(): for rep in range(repetitions): starter.record() _, _ = model(rescaled_left.unsqueeze(0)) ender.record() # WAIT FOR GPU SYNC torch.cuda.synchronize() curr_time = starter.elapsed_time(ender) timings[rep] = curr_timemean_syn = np.sum(timings) / repetitionsstd_syn = np.std(timings)print(mean_syn, std_syn)推論テストでは、このモデルが18.69±0.44ms、つまり約55Hzで実行できることが示されています。重要な点として、これはNVIDIA RTX 3060 GPUを搭載したノートパソコンで実行されたPythonのプロトタイプにすぎないことに注意する必要があります。異なるハードウェアでは推論速度が変わります。また、Torch-TensorRtのようなSDKをNVIDIA GPUに展開すると、大幅な高速化が期待できます。
結論
この記事では、マルチタスク学習がコストを削減し、炭素排出量を減らすことができる方法を学びました。CityScapesデータセット上で分類と回帰を同時に行うことができる軽量マルチタスクアーキテクチャの構築方法を学びました。また、CreStereoと知識蒸留を活用して、モデルがより良い深度マップを予測するように学習する方法も学びました。
この軽量モデルは、パフォーマンスを犠牲にして速度と効率性を追求したトレードオフを提供します。このトレードオフにも関わらず、トレーニングされたモデルはテストデータにおいて合理的な深度とセグメンテーション結果を予測することができました。さらに、真の深度マップと似た深度分布を予測することができました。
参考文献
[1] Nekrasov, Vladimir, et al. 「非対称アノテーションを用いたリアルタイムジョイントセマンティックセグメンテーションと深度推定」。CoRR、vol. abs/1809.04766、2018年、http://arxiv.org/abs/1809.04766
[2] Standley, Trevor, et al. 「マルチタスク学習で一緒に学習すべきタスクはどれですか?」。CoRR、vol. abs/1905.07553、2019年、http://arxiv.org/abs/1905.07553
[3] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., & Schiele, B. (2016)。セマンティック都市シーン理解のためのCityscapesデータセット。2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)。https://doi.org/10.1109/cvpr.2016.350
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Google AIはWeatherBench 2を紹介します:さまざまな天気予測モデルの評価と比較のための機械学習フレームワーク
- 「PDF、txt、そしてウェブページとして、あなたのドキュメントと話しましょう」
- 「AIとのプログラミング」
- このAI論文は、さまざまなディープラーニングと機械学習のアルゴリズムを用いた行動および生理学的スマートフォン認証の人気のあるダイナミクスとそのパフォーマンスを識別します
- 「大規模言語モデルのダークサイドの理解:セキュリティの脅威と脆弱性に関する包括的なガイド」
- コードのための大規模な言語モデルの構築とトレーニング:StarCoderへの深い探求
- 「ガードレールでLLMを保護する」





