Mozilla Common Voiceでの音声言語認識-第II部:モデル
Mozilla Common Voiceの音声言語認識 II部:モデル
これは、Mozilla Common Voiceデータセットに基づく音声言語認識に関する2番目の記事です。最初のパートではデータの選択と最適な埋め込みの選択について説明しました。ここでは、いくつかのモデルをトレーニングし、最も優れたモデルを選びます。
モデルの比較
以下のモデルをフルデータ(40,000のサンプル、データの選択と前処理に関する詳細は最初のパートを参照)でトレーニングし、評価します:
· 畳み込みニューラルネットワーク(CNN)モデル。言語分類問題を2次元画像の分類として扱います。CNNベースの分類器は、言語認識のTopCoderコンペティションで有望な結果を示しました。
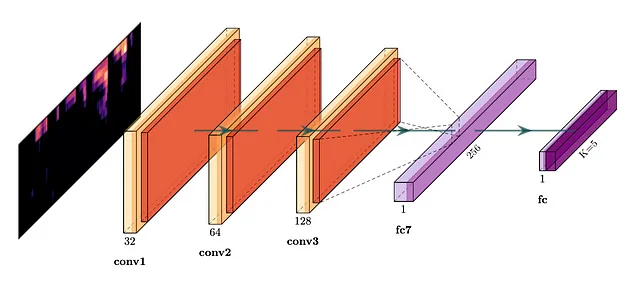
· Bartz et al. 2017によるCRNNモデル。CRNNは、CNNの記述力とRNNの時間的特徴を捉える能力を組み合わせたものです。
- 「プロジェクトRumiにご参加ください:大規模言語モデルのための多言語パラ言語的プロンプティング」
- 「教師なし学習シリーズ — セルフオーガナイズマップの探求」
- 「グラフ機械学習 @ ICML 2023」
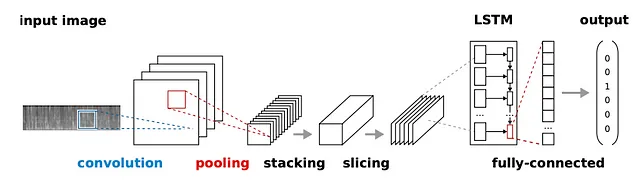
· Alashban et al. 2022によるCRNNモデル。これはCRNNアーキテクチャの別のバリエーションです。
· De Andrade et al. 2018によるAttNNモデル。このモデルは元々音声認識のために提案され、その後、インテリジェントミュージアムプロジェクトの音声言語認識に適用されました。このモデルには、畳み込みとLSTMユニットに加えて、入力シーケンスの一部(フーリエ変換が計算されるフレーム)の重要性に応じて重みを付けるためにトレーニングされる後続のアテンションブロックがあります。
· CRNN*モデル:AttNNと同じアーキテクチャですが、アテンションブロックはありません。
· Time-delayニューラルネットワーク(TDNN)モデル。ここでテストするモデルは、Snyder et al. 2018で音声言語認識のX-vector埋め込みを生成するために使用されました。私たちの研究では、X-vectorの生成をバイパスし、ネットワークを直接言語を分類するためにトレーニングしました。
すべてのモデルは、同じトレーニング/検証/テストの分割と同じメルスペクトログラム埋め込み(最初の13のメルフィルタバンク係数)に基づいてトレーニングされました。モデルはこちらで見つけることができます。
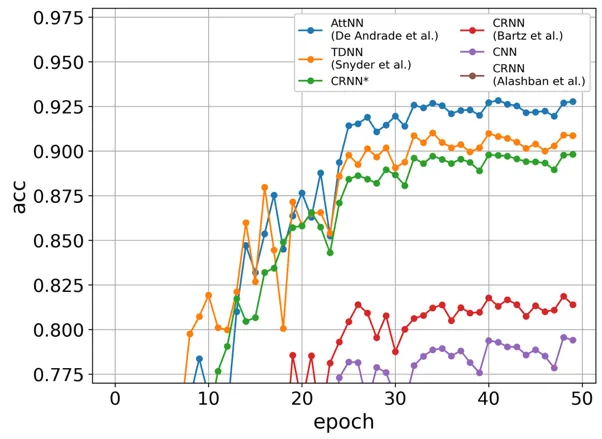
検証セットの学習曲線は、以下の図に示されています(各「エポック」はデータセットの1/8を指します)。
以下の表は、10回の実行に基づく正解率の平均と標準偏差を示しています。
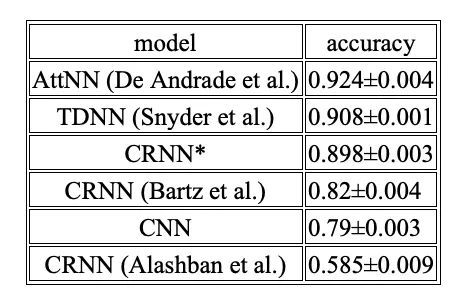
明らかに、AttNN、TDNN、およびCRNN*モデルは類似のパフォーマンスを示しており、AttNNが92.4%の正解率で1位となっています。一方、CRNN(Bartz et al. 2017)、CNN、およびCRNN(Alashban et al. 2022)は非常に控えめなパフォーマンスを示し、CRNN(Alashban et al. 2022)が58.5%の正解率で最下位です。
次に、優勝したAttNNモデルをトレーニングし、トレーニングセットと検証セットで評価しました。テスト正解率は92.4%(男性92.4%、女性92.3%)で、検証正解率に近いことがわかりました。これは、モデルが検証セットに対して過学習していないことを示しています。
評価されたモデル間の性能差を理解するために、まずTDNNとAttNNが音声認識タスクに特化して設計され、以前のベンチマークに対して既にテストされていることに注意します。これがこれらのモデルがトップになる理由かもしれません。
AttNNと私たちのCRNNモデル(同じアーキテクチャですが、アテンションブロックはありません)との性能差は、アテンションメカニズムが話された言語認識において関連性があることを証明しています。次のCRNNモデル(Bartz et al. 2017)は、同様のアーキテクチャにもかかわらず、性能が低いです。これはおそらく、デフォルトのモデルのハイパーパラメータがMCVデータセットに最適でないためです。
CNNモデルには特定のメモリメカニズムはなく、次に来ます。厳密に言えば、CNNには畳み込みを計算するために一定数の連続フレームが関与するため、一定のメモリの概念があります。したがって、より高い層はCNNの階層的な性質により、より長い時間間隔の情報をカプセル化します。実際、第2位のスコアを叩き出したTDNNモデルは、1次元CNNと見なすことができるかもしれません。したがって、より多くの時間をCNNアーキテクチャの検索に費やすと、CNNモデルはTDNNとほぼ同等の性能を発揮したかもしれません。
Alashban et al. 2022のCRNNモデルは意外なことに最も低い正確性を示します。元の研究では、このモデルはMCVで言語を認識するために設計され、約97%の正確性を示しました。ただし、元のコードは公開されていないため、この大きな食い違いの原因を特定するのは難しいでしょう。
ペアワイズ正確性
多くの場合、ユーザーは通常2つの言語以上を使用しません。この場合、モデルの性能のより適切な指標は、他のすべての言語のスコアを無視して、特定のペアの言語に対して計算されるペアワイズ正確性です。
テストセット上のAttNNモデルのペアワイズ正確性は、以下の表に示されています。混同行列の隣にあり、個々の言語の再現率が対角線上に表示されます。平均ペアワイズ正確性は97%です。ペアワイズ正確性は、2つの言語のみを識別する必要があるため、常に正確性よりも高くなります。
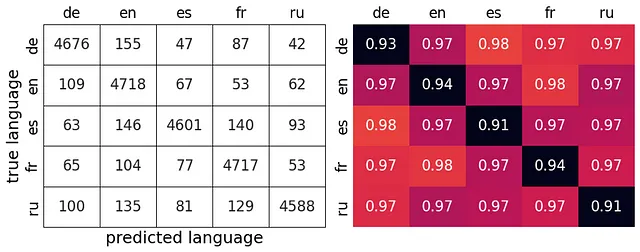
したがって、このモデルは、ドイツ語(de)とスペイン語(es)とフランス語(fr)と英語(en)の間で最も優れた識別能力を持っています(98%)。これは、これらの言語の音韻体系がかなり異なるため、驚くべきことではありません。
モデルのトレーニングにはソフトマックスロスを使用しましたが、ペアワイズ分類ではタプルマックスロスでより高い正確性が得られる可能性が以前に報告されています(Wan et al. 2019)。
タプルマックスロスの効果を調査するために、PyTorchでタプルマックスロスを実装してからモデルを再トレーニングしました(実装の詳細はこちらを参照してください)。以下の図は、バリデーションセットで評価した場合のソフトマックスロスとタプルマックスロスの正確性とペアワイズ正確性の効果を比較しています。
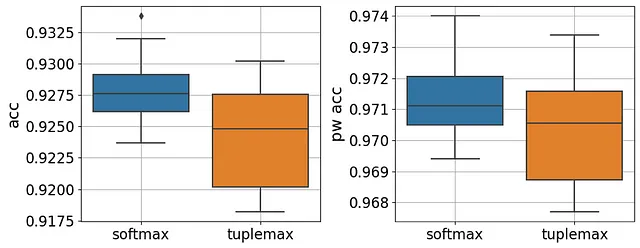
観察できるように、タプルマックスロスは、全体的な正確性(対応するt検定のp値=0.002)またはペアワイズ正確性(対応するt検定のp値=0.2)を比較する際に劣っています。
実際、元の研究でも、なぜタプルマックスロスがより良い結果を出すのかはっきりと説明されていません。著者が行う例は次のとおりです:

実際のところ、損失の絶対値は実際にはあまり意味を持ちません。十分なトレーニングイテレーションがあれば、この例はどちらの損失でも正しく分類されるかもしれません。
とにかく、タプルマックスロスは汎用的な解決策ではなく、損失関数の選択は各問題に慎重に活用する必要があります。
結論
私たちは、Mozilla Common Voice(MCV)データセットからの短いオーディオクリップの話し言葉認識において、92%の正確さと97%のペアワイズ正確さを達成しました。ドイツ語、英語、スペイン語、フランス語、ロシア語が考慮されました。
メルスペクトログラム、MFCC、RASTA-PLP、GFCCの埋め込みを比較した予備的な研究では、最初の13個のフィルタバンク係数を持つメルスペクトログラムが最も高い認識精度を示すことがわかりました。
次に、5つのニューラルネットワークモデル(CNN、CRNN(Bartz et al. 2017)、CRNN(Alashban et al. 2022)、AttNN(De Andrade et al. 2018)、CRNN *、およびTDNN(Snyder et al. 2018))の汎化性能を比較しました。すべてのモデルの中で、AttNNが最も優れた性能を示し、LSTMとアテンションブロックが話し言葉認識において重要であることを強調しています。
最後に、ペアワイズ正確さを計算し、tuplemax損失の効果を研究しました。結果として、tuplemax損失はsoftmaxに比べて正確さとペアワイズ正確さの両方を低下させることがわかりました。
結論として、私たちの結果はMozilla Common Voiceデータセットにおける話し言葉認識の新しいベンチマークを構成しています。将来の研究では、異なる埋め込みを組み合わせて有望なニューラルネットワークアーキテクチャ(例:トランスフォーマー)を詳しく調査することで、より良い結果が得られる可能性があります。
第III部では、モデルの性能向上に役立つ可能性のあるオーディオ変換について議論します。
参考文献
- Alashban, Adal A., et al. 「Spoken language identification system using convolutional recurrent neural network.」 Applied Sciences 12.18 (2022): 9181.
- Bartz, Christian, et al. 「Language identification using deep convolutional recurrent neural networks.」 Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, November 14–18, 2017, Proceedings, Part VI 24. Springer International Publishing, 2017.
- De Andrade, Douglas Coimbra, et al. 「A neural attention model for speech command recognition.」 arXiv preprint arXiv:1808.08929 (2018).
- Snyder, David, et al. 「Spoken language recognition using x-vectors.」 Odyssey. Vol. 2018. 2018.
- Wan, Li, et al. 「Tuplemax loss for language identification.」 ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Juliaプログラミング言語の探求:MongoDB」
- 大規模言語モデルは、ビデオからの長期行動予測に役立ちますか?AntGPTをご紹介します:ビデオベースの長期行動予測タスクにおいて大規模言語モデルを組み込むためのAIフレームワークです
- 「IBM、HuggingFace、そしてNASAがWatsonx․ai Foundation Modelをオープンソース化 NASA初の公開可能なAI基盤モデルであり、HuggingFace上で最大の地理空間モデル」
- キャッシング生成的LLMs | APIコストの節約
- ジニ係数の解説:経済学が機械学習に影響を与えた方法
- 「コードを使用して、大規模な言語モデルを使って、どんなPDFや画像ファイルでもチャットする方法」
- ライトオンAIは、Falcon-40Bをベースにした新しいオープンソースの言語モデル(LLM)であるAlfred-40B-0723をリリースしました