「LLMとNLPのための非構造化データの監視」
Monitoring Unstructured Data for LLM and NLP
テキストディスクリプタを使用するコードチュートリアル
NLPまたはLLMベースのソリューションを展開したら、それを追跡する方法が必要です。しかし、テキストの山を理解するために非構造化データを監視するにはどうすればいいのでしょうか?
ここではいくつかのアプローチがあります。生のテキストデータのドリフトを検出したり、埋め込みドリフトを検出したり、正規表現を使用してルールベースのチェックを実行したりする方法などです。
このチュートリアルでは、特定のアプローチの1つである、テキストディスクリプタを追跡する方法について詳しく説明します。
まず、理論について説明します:
- テキストディスクリプタとは何か、いつ使用するか。
- テキストディスクリプタの例。
- カスタムディスクリプタの選択方法。
次に、コードに入りましょう! あなたはeコマースのレビューデータを使用して、次のステップを実行します:
- テキストデータの概要を把握する。
- 標準ディスクリプタを使用してテキストデータのドリフトを評価する。
- 外部の事前学習モデルを使用してカスタムテキストディスクリプタを追加する。
- パイプラインテストを実装してデータの変更を監視する。
データの変化を評価するためにEvidentlyオープンソースのPythonライブラリを使用します。
コード例: コードに直接進む場合は、こちらの例のノートブックをご参照ください。
テキストディスクリプタとは何ですか?
テキストディスクリプタとは、テキストデータセット内のオブジェクトを説明する任意の特徴またはプロパティのことです。たとえば、テキストの長さやその中のシンボルの数などです。
テキストに付随する有用なメタデータがすでにあるかもしれません。たとえば、eコマースのユーザーレビューには、ユーザーが割り当てた評価やトピックのラベルが付いているかもしれません。
そうでなければ、独自のディスクリプタを生成することもできます!これは、テキストデータに「仮想的な特徴」を追加することによって行います。それぞれが意味のある基準を使用してテキストを説明または分類するのを助けます。
これらのディスクリプタを作成することで、独自の単純な「埋め込み」を作成し、各テキストをいくつかの解釈可能な次元にマッピングします。これにより、非構造化データを理解するのに役立ちます。
次に、これらのテキストディスクリプタを使用できます:
- 本番のNLPモデルを監視するため。 データのプロパティを時間とともに追跡し、変化を検出することができます。たとえば、ディスクリプタは、テキストの長さの急増や感情のドリフトを検出するのに役立ちます。
- モデルの更新中にモデルをテストするため。 モデルを繰り返し改良する際に、評価データセットとモデルの応答のプロパティを比較することができます。たとえば、LLMによって生成された回答の長さが同様であり、期待する単語が一貫して含まれているかを確認することができます。
- データドリフトやモデルの劣化のデバッグに。 埋め込みのドリフトを検出したり、モデルの品質の低下を直接観察した場合、テキストディスクリプタを使用してその原因を調査することができます。
テキストディスクリプタの例
ここでは、いくつかの良いデフォルトのテキストディスクリプタを紹介します:
テキストの長さ
始めるには、単純なテキスト統計を見るのが良いです。たとえば、単語、シンボル、または文で測定されるテキストの長さを見ることができます。平均的な長さや最小-最大の長さを評価し、分布を見ることができます。
使用ケースに基づいて期待値を設定することができます。たとえば、製品のレビューは5から100ワードの間である傾向があります。もし短かすぎたり長すぎたりする場合、コンテキストの変化を示しているかもしれません。固定長のレビューで急激な増加がある場合、スパム攻撃の兆候かもしれません。ネガティブなレビューが通常は長いことを知っている場合、特定の長さ以上のレビューの割合を追跡することもできます。
また、クイックな正常性チェックもあります。チャットボットを実行する場合、ゼロ以外の応答を期待したり、意味のある出力の最小長があることを期待するかもしれません。
語彙外の単語

定義された語彙外の単語の割合を評価することは、データの品質を評価するための「粗い」指標です。ユーザーが新しい言語でレビューを書き始めたのでしょうか?ユーザーは英語ではなくPythonでチャットボットと話していますか?ユーザーは実際の単語の代わりに「ggg」という応答を埋めていますか?
これは、さまざまな変更を検出するための単一の実用的な手法です。シフトを検出すると、より詳細なデバッグが可能になります。
時間の経過とともに蓄積された「良い」プロダクションデータの例に基づいて、語彙外の単語の割合についての期待値を設定することができます。たとえば、以前の製品レビューのコーパスを見ると、OOVは10%未満になることを期待し、この閾値を上回るかどうかを監視できます。
文字以外の文字
関連するが少し異なるのは、このディスクリプタは文字や数字以外のさまざまな特殊記号を数えます。コンマ、括弧、ハッシュなどが含まれます。
テキストに特殊記号の適度な割合が予想される場合もあります。テキストにコードが含まれているか、JSONとして構造化されているかもしれません。テキストには句読点しか含まれないと予想される場合もあります。
文字以外の文字に変化がある場合、レビューのテキストにHTMLコードが漏れ込んでいる、スパム攻撃が行われている、予期しない使用ケースなどのデータ品質の問題が露呈する可能性があります。
感情
テキストの感情は、さまざまなシナリオで役立ちます。チャットボットの対話からユーザーレビュー、マーケティングコピーの作成までさまざまな場面で役立ちます。通常、扱うテキストの感情についての期待値を設定できます。
感情が「適用されない」としても、それは主に中立的なトーンの期待値に翻訳されるかもしれません。ネガティブまたはポジティブなトーンの出現は、予期しない使用シナリオを示唆するかもしれません:ユーザーは仮想住宅ローンアドバイザーをクレームチャネルとして使用していますか?
一定のバランスも期待できます。たとえば、ネガティブなトーンの対話やレビューの一部は常に存在しますが、特定のしきい値を超えないか、レビューの感情の全体的な分布が安定しているかどうかを期待するでしょう。
トリガーワード
テキストに特定のリストまたはリストからの単語が含まれているかどうかをチェックし、これをバイナリフィーチャーとして扱うこともできます。
これは、テキストに関する複数の期待値をエンコードするための強力な方法です。リストの手動での管理には努力が必要ですが、この方法で多くの便利なチェックを設計できます。たとえば、以下のようなトリガーワードのリストを作成できます:
- 製品やブランドの言及。
- 競合他社の言及。
- 場所、都市、場所などの言及。
- 特定のトピックを表す単語の言及。
使用ケースに特化したこのようなリストを作成(および継続的に拡張)できます。
たとえば、アドバイザーチャットボットが会社が提供する製品の選択を支援する場合、ほとんどの応答にはリストからの製品名が含まれることを期待するかもしれません。
正規表現の一致
特定の単語がリストから含まれることは、正規表現として定義できるパターンの一例です。ほかにも考えられます:テキストが「こんにちは」で始まり、「ありがとうございます」で終わることを予想しますか?メールアドレスを含みますか?既知の名前要素を含みますか?
特定の形式に一致するモデルの入力または出力を期待する場合、別の記述子として正規表現一致を使用することができます。
カスタム記述子
このアイデアをさらに拡張することができます。例えば:
- その他のテキストのプロパティを評価する:毒性、主観性、トーンの形式、読みやすさのスコアなど。多くの場合、トリックを行うためのオープンな事前トレーニング済みモデルが見つかります。
- 特定のコンポーネントをカウントする:メール、URL、絵文字、日付、品詞の一部。外部モデルまたは単純な正規表現を使用することができます。
- 統計を細かく追跡する:単語の平均長さ、大文字または小文字であるかどうか、一意の単語の比率など、使用ケースに意味がある場合は、非常に詳細なテキスト統計を追跡することができます。
- 個人を特定できる情報を監視する:例えば、チャットボットの会話でそれが出てくることを予期しない場合。
- 固有表現認識を使用する:特定のエンティティを抽出し、タグとして扱うために使用します。
- トピックモデリングを使用する:トピックモニタリングシステムを構築するために使用します。これは最も労力のかかるアプローチですが、正しく行われると強力です。テキストが主にトピックに留まり、モデルにトレーニング用の以前の例のコーパスがある場合に便利です。教師なしのトピッククラスタリングを使用し、新しいテキストを既知のクラスタに割り当てるモデルを作成できます。その後、割り当てられたクラスを記述子として扱い、新しいデータのトピックの分布の変化を監視することができます。

監視用の記述子を設計する際に考慮すべきことは次のとおりです:
- 焦点を絞り、使用ケースに適した品質の高い指標の数を見つけることが最善です。すべての可能な次元を監視するのではなく、記述子をモデルの特徴として考えてください。多くの弱いまたは役に立たない特徴を生成するよりも、いくつかの強力な特徴を見つけたいと思います。多くの特徴は相関する傾向があります:OOV単語の言語とシェア、文や記号の長さなどです。お好みのものを選んでください!
- 探索的データ分析を使用して、既存のデータ(例:前の会話のログ)でテキストのプロパティを評価し、仮説をテストしてから、モデルの監視に追加する前にそれらを確認してください。
- モデルの失敗から学ぶ。本番モデルの品質に問題が発生し、再発する可能性がある場合(例:外国語のテキスト)、将来的にそれを検出するためのテストケースまたは記述子を開発する方法を考えてください。
- 計算コストに注意してください。可能な次元ごとにテキストをスコアリングするために外部モデルを使用することは魅力的ですが、これにはコストがかかります。大きなデータセットで作業する場合には考慮してください:外部の分類器は実行する追加のモデルです。より少ないまたはシンプルなチェックでも十分です。
ステップバイステップチュートリアル
アイデアを説明するために、次のシナリオを進めてみましょう:電子商取引のウェブサイトにユーザーが残すレビューをスコアリングし、トピックでタグ付けするための分類モデルを構築しています。本番環境になったら、データとモデルの環境の変化を検出したいと思いますが、真のラベルはありません。それらを取得するために別のラベリングプロセスを実行する必要があります。
ラベルがない状態で変化について把握するにはどうすればいいでしょうか?
例のデータセットを取り上げ、以下のステップを進めてみましょう:
コードの例:すべてのステップに従うために、例のノートブックにアクセスしてください。
💻 1. Evidentlyのインストール
まず、Evidentlyをインストールします。Pythonパッケージマネージャを使用して環境にインストールします。Colabで作業している場合は、!pip install を実行します。Jupyter Notebookでは、nbextensionもインストールする必要があります。環境に関する手順を確認してください。
また、pandasや特定のEvidentlyコンポーネントなど、他のいくつかのライブラリもインポートする必要があります。ノートブックの手順に従ってください。
🔡 2. データの準備
準備が整ったら、データを見てみましょう!電子商取引のレビューからのオープンデータセットで作業します。
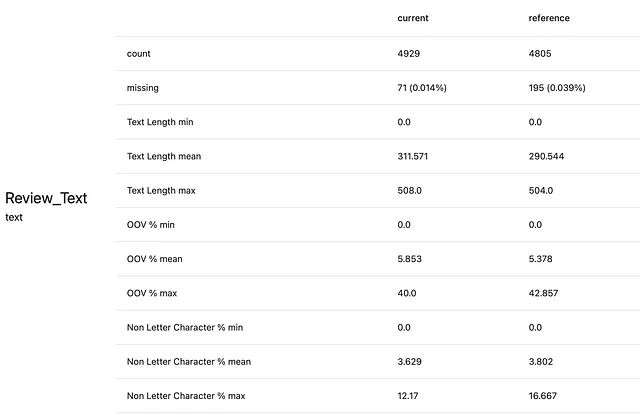
データセットの見た目は次のようになります:
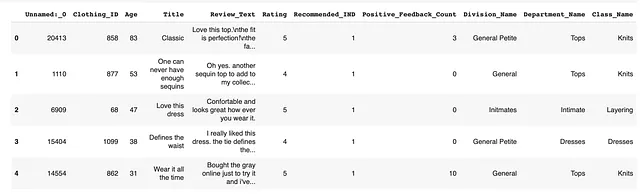
デモ目的では、「Review_Text」列に焦点を当てます。本番では、レビューのテキストの変化を監視したいと考えています。
テキストを含む列を指定する必要があります。以下は列のマッピングの指定例です:
column_mapping = ColumnMapping( numerical_features=['Age', 'Positive_Feedback_Count'], categorical_features=['Division_Name', 'Department_Name', 'Class_Name'], text_features=['Review_Text', 'Title'])また、データをリファレンスと現在の2つに分割する必要があります。ここでは、「リファレンス」データが過去の代表的な期間(例:前月)のデータであり、「現在の」データが現在の本番データ(例:今月)です。これらはディスクリプタを使用して比較する2つのデータセットです。
注意:適切な歴史的なベースラインを確立することが重要です。将来のデータの見た目を反映する期間を選択してください。
私たちは、それぞれのサンプルに5000の例を選択しました。興味深くするために、現在のデータセットではネガティブなレビューを選択することで人工的なシフトを導入しました。
reviews_ref = reviews[reviews.Rating > 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)reviews_cur = reviews[reviews.Rating < 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)📊 3. 探索的データ分析
データをより良く理解するために、Evidentlyを使用して視覚的なレポートを生成することができます。既存のテキスト概要プリセットがあり、2つのテキストデータセットを迅速に比較するのに役立ちます。さまざまな記述的なチェックを組み合わせ、モデルベースのドリフト検出方法を使用して全体的なデータのドリフトを評価します。
このレポートにはいくつかの標準的なディスクリプタも含まれており、トリガーワードのリストを使用してディスクリプタを追加することもできます。次のディスクリプタをレポートの一部として見てみましょう:
- テキストの長さ
- 未知の語彙(OOV)の割合
- 非文字記号の割合
- レビューの感情
- 「ドレス」または「ガウン」という単語を含むレビュー
- 「ブラウス」または「シャツ」という単語を含むレビュー
詳細については、Evidentlyのドキュメントのディスクリプタをご覧ください。
このレポートを実行するために必要なコードは次のとおりです。各ディスクリプタにカスタム名を割り当てることができます。
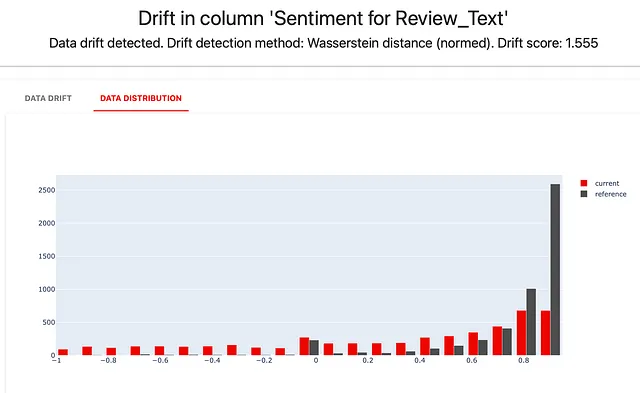
text_overview_report = Report(metrics=[ TextOverviewPreset(column_name="Review_Text", descriptors={ "Review texts - OOV %" : OOV(), "Review texts - Non Letter %" : NonLetterCharacterPercentage(), "Review texts - Symbol Length" : TextLength(), "Review texts - Sentence Count" : SentenceCount(), "Review texts - Word Count" : WordCount(), "Review texts - Sentiment" : Sentiment(), "Reviews about Dress" : TriggerWordsPresence(words_list=['dress', 'gown']), "Reviews about Blouses" : TriggerWordsPresence(words_list=['blouse', 'shirt']), }) ]) text_overview_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) text_overview_reportこのようなレポートを実行することで、テキストの長さの分布など、パターンを探索し、特定のプロパティに関する期待を形成するのに役立ちます。
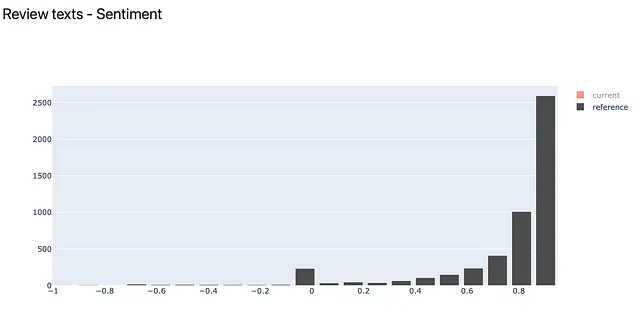
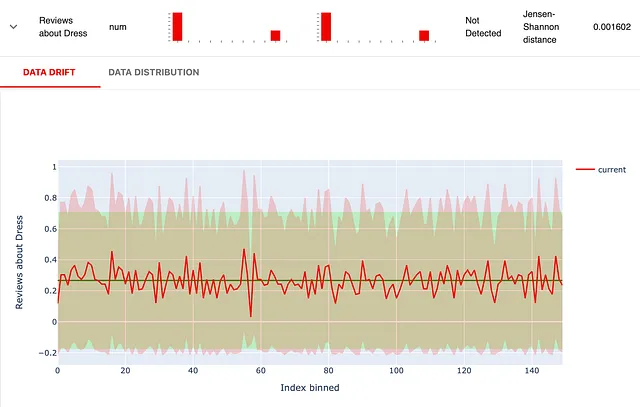
「感情」ディスクリプタの分布は、データを分割する際に行ったトリックをすばやく明らかにします。評価が3以上のレビューを「リファレンス」に配置し、よりネガティブなレビューを「現在の」データセットに配置しました。結果が表示されています:
デフォルトのレポートは非常に包括的であり、一度に多くのテキストのプロパティを見るのに役立ちます。データセット内のディスクリプタと他の列との相関関係を探索することも可能です!
これは探索フェーズで使用できますが、常にすべてを確認する必要はないでしょう。
幸運なことに、カスタマイズは簡単です。
明らかなプリセットとメトリクス。Evidentlyには、ボックスからすぐにレポートを生成するためのレポートのプリセットがあります。しかし、選択肢はたくさんあります!それらを組み合わせてカスタムレポートを作成することができます。プリセットとメトリクスを参照して、そこにあるものを理解してください。
📈 4. ディスクリプタのドリフトを監視する
探索的な分析とビジネス問題の理解に基づいて、少数のプロパティのみを追跡することにしたとしましょう:
統計的な変化に気付きたい場合です。これらのプロパティの分布が基準期間と異なる場合に気付くために、Evidentlyで実装されたドリフト検出方法を使用できます。たとえば、「感情」というような数値的な特徴の場合、デフォルトではWasserstein距離を使用してシフトを監視します。異なる方法を選択することもできます。
以下は、3つのディスクリプタの変化を追跡するためのシンプルなドリフトレポートの作成方法です。
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Review_Text")), ColumnDriftMetric(Sentiment().for_column("Review_Text")), ColumnDriftMetric(TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_reportレポートを実行すると、選択したすべてのディスクリプタに対する組み合わせた視覚化が得られます。以下はその一つです:

濃い緑の線は基準データセットの平均感情です。緑の領域は平均からの標準偏差をカバーしています。現在の分布(赤色)が明らかによりネガティブであることが分かります。
注意:このシナリオでは、出力のドリフトも監視することが意味があります:予測クラスのシフトを追跡することによって。JSダイバージェンスなどのカテゴリカルデータのドリフト検出方法を使用することができます。このチュートリアルでは、入力のみに焦点を当てており、予測は生成していませんので、それについては取り扱いません。実際には、予測のドリフトがしばしば最初の反応信号です。
😍 5. 「感情」ディスクリプタを追加する
レビューに表現される感情は全体的な感情とは異なりますが、「悲しい」と「怒っている」といったレビューの区別にも役立ちます。
このカスタムディスクリプタを追加しましょう!適切な外部オープンソースモデルを見つけてデータセットをスコアリングすることができます。その後、このプロパティを追加の列として扱います。
私たちはHuggingfaceからDistilbertモデルを使用することにします。このモデルはテキストを5つの感情に分類します。
名前付きエンティティ認識、言語検出、毒性検出など、あなたのユースケースに合った他のモデルを使用することも検討できます。
モデルを実行するためにtransformersをインストールする必要があります。詳細については、指示を確認してください。それから、レビューデータセットに適用します:
from transformers import pipeline classifier = pipeline("text-classification", model='bhadresh-savani/distilbert-base-uncased-emotion', top_k=1) prediction = classifier("I love using evidently! It's easy to use", ) print(prediction)注意:このステップでは外部モデルを使用してデータセットにスコアを付けます。環境によっては、実行に時間がかかる場合があります。待つことなく原則を理解するために、例のノートブックの「シンプルな例」セクションを参照してください。
新しい列「emotion」をデータセットに追加した後、Column Mappingに反映する必要があります。データセット内の新しいカテゴリ変数であることを指定する必要があります。
column_mapping = ColumnMapping( numerical_features=['Age', 'Positive_Feedback_Count'], categorical_features=['Division_Name', 'Department_Name', 'Class_Name', 'emotion'], text_features=['Review_Text', 'Title'] )これで、レポートに「emotion」の分布ドリフト監視を追加することができます。
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Review_Text")), ColumnDriftMetric(Sentiment().for_column("Review_Text")), ColumnDriftMetric(TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ColumnDriftMetric('emotion'), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_report以下が手に入るものです!
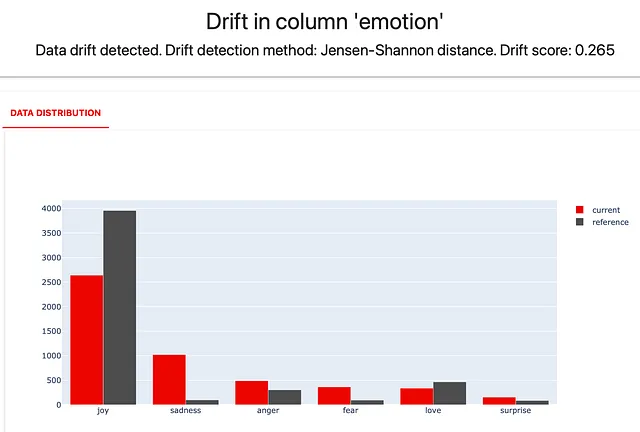
「悲しい」レビューが大幅に増加し、「喜び」が減少していることがわかります。
時間の経過を追跡するのに役立ちますか?新しいデータをスコアリングしながらこのチェックを継続することができます。
🏗️ 6. パイプラインテストを実行する
データ入力の定期的な分析を実行するために、評価をテストとしてパッケージ化することは合理的です。このシナリオでは、「合格」または「不合格」の結果が得られます。すべてのテストが合格した場合にはプロットを見る必要はありません。変化がある場合にのみ興味があります!
明らかにこのように動作するTest Suiteという代替インターフェースがあります。
次に、同じ4つの記述子に対して統計的分布をチェックするためのテストスイートを作成する方法を示します。
descriptors_test_suite = TestSuite(tests=[ TestColumnDrift(column_name = 'emotion'), TestColumnDrift(column_name = WordCount().for_column("Review_Text")), TestColumnDrift(column_name = Sentiment().for_column("Review_Text")), TestColumnDrift(column_name = TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ]) descriptors_test_suite.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_test_suite注意:デフォルトで実行しますが、カスタムのドリフトメソッドと条件も設定できます。
以下が結果です。出力は整然と構造化されており、どの記述子がドリフトしているかがわかります。
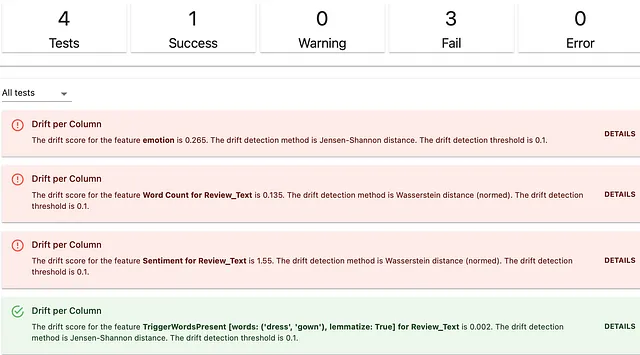
統計的分布のドリフトを検出することは、テキストの特性の変化を監視する方法の一つです。他にもあります!時には、記述子の最小値、最大値、または平均値に基づいたルールベースの期待を実行することが便利です。
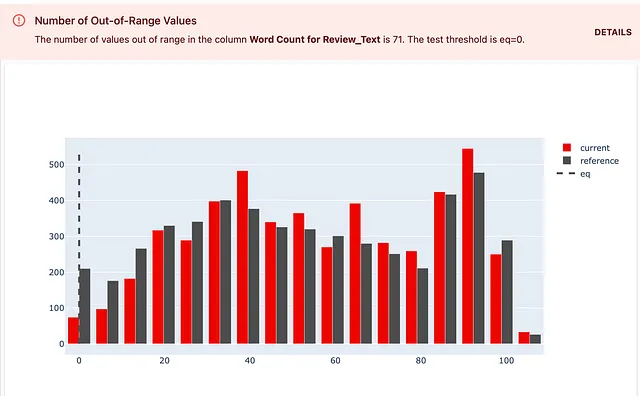
例えば、すべてのレビューテキストが2単語以上であることを確認したいとします。少なくとも1つのレビューが2単語未満の場合、テストが失敗し、応答で短いテキストの数を表示したいとします。
以下がその方法です!TestNumberOfOutRangeValues()チェックを選択できます。この場合、カスタムの境界値を設定する必要があります:期待される範囲の「左側」は2単語です。テスト条件eq=0も設定する必要があります。これは、この範囲外のオブジェクトの数が0であることを期待していることを意味します。もし数が高い場合、テストが失敗するということです。
descriptors_test_suite = TestSuite(tests=[ TestNumberOfOutRangeValues(column_name = WordCount().for_column("Review_Text"), left=2, eq=0), ]) descriptors_test_suite.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_test_suite以下が結果です。定義された期待値が表示されるテストの詳細も確認できます。
この原則に従って他のチェックを設計できます。
Evidentlyのサポート
このチュートリアルを楽しんでいただけましたか?コミュニティのために無料でオープンソースのツールとコンテンツを作成し続けるために、Evidentlyにスターを付けて貢献してください! ⭐️ GitHubでスターを付ける ⟶
まとめ
テキスト記述子は、テキストデータを数値またはカテゴリ属性として表現できる解釈可能な次元にマッピングします。これにより、非構造化データを説明、評価、および監視するのに役立ちます。
このチュートリアルでは、記述子を使用してテキストデータを監視する方法について学びました。
このアプローチを使用して、NLPやLLMパワードモデルのプロダクションの振る舞いを監視することができます。記述子をカスタマイズし、埋め込みのドリフトなど他の方法と組み合わせることもできます。
他に普遍的に有用と考えられる記述子はありますか?ご意見をお聞かせください!Discordコミュニティに参加して、思いを共有しましょう。
元記事は2023年6月27日にhttps://www.evidentlyai.comで公開されました。本記事の共同執筆者としてOlga Filippovaさんに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
