モデルの自信を求めて ブラックボックスを信頼できるか?
モデルの自信を求めるなら、ブラックボックスの信頼性はどうなのか?

大型言語モデル(LLM)であるGPT-4やLLaMA2が[データラベリング]チャットに参入しました。LLMは長い道のりを歩んできて、今ではデータのラベル付けや人間が行ってきたタスクを行うことができます。LLMを使用してデータラベルを取得することは非常に迅速で比較的安価ですが、依然として1つの大きな問題があります。それは、これらのモデルが究極のブラックボックスであるということです。そのため、燃えるような疑問は、これらのLLMが生成するラベルにどれだけの信頼を置くべきかということです。今日の記事では、この難問を解明し、LLMによるラベル付きデータへの信頼度を評価するための基本的なガイドラインを確立します。
背景
以下の結果は、トルコ語のデータセットで人気モデルとともに実施されたTolokaによる実験の結果です。これは科学的な報告書ではなく、問題への可能なアプローチの概要と、アプリケーションに最適な方法を決定するためのいくつかの提案の短い概要です。
重要な問い
詳細に入る前に、重要な問いは次のとおりです:いつLLMによって生成されたラベルを信頼できるのか、いつ疑うべきなのか?これを知ることは、自動データラベリングに役立ち、顧客サポート、コンテンツ生成などの他の応用タスクでも役立ちます。
現在の状況
では、人々はこの問題にどのように取り組んでいるのでしょうか?モデルに自信スコアを直接尋ねる方法もありますし、モデルの回答の一貫性を複数回の実行で見る方法もあります。また、モデルの対数確率を調べる方法もあります。しかし、これらのアプローチのいずれが信頼性があるのでしょうか?さあ、確かめましょう。
経験則
「良い」信頼スコアとは何でしょうか?一つのシンプルな規則は、信頼スコアとラベルの正確さの間に正の相関関係があるべきということです。言い換えれば、高い信頼スコアは正しい可能性が高いことを意味します。この関係を信頼度と正確さを表すキャリブレーションプロットを使用して視覚化することができます。
実験とその結果
アプローチ1:自己信頼
自己信頼のアプローチでは、モデルに直接信頼度について尋ねることが含まれます。そして何と言いますか?結果は悪くありませんでした!私たちがテストしたLLMは非英語のデータセットに苦労しましたが、自己報告された信頼度と実際の正確さの間にはかなりの相関関係がありました。つまり、モデルは自分の制約をよく意識しています。GPT-3.5とGPT-4でも同様の結果が得られました。
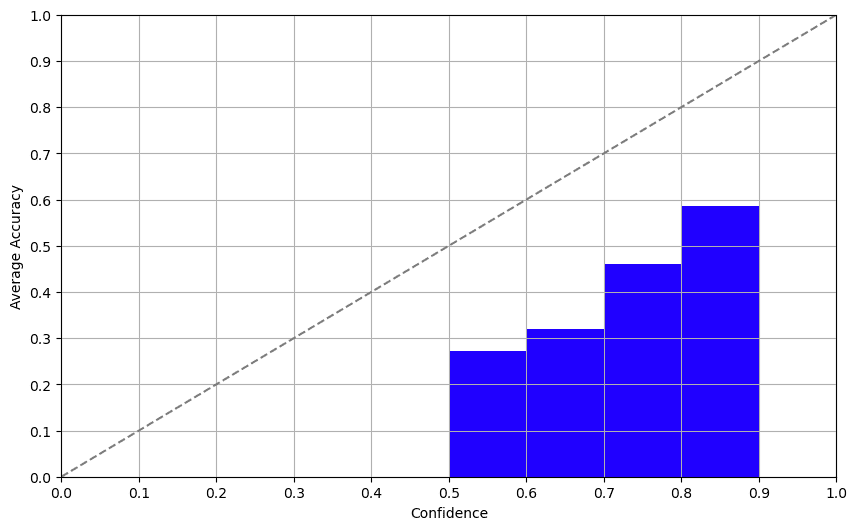
アプローチ2:一貫性
高い温度(〜0.7–1.0)を設定し、同じアイテムに対して複数回ラベルを付け、回答の一貫性を分析します。詳細については、この論文をご覧ください。GPT-3.5で試してみましたが、控えめに言っても状態がひどいものとなりました。モデルに同じ質問を複数回回答させた結果、一貫して不安定な結果となりました。このアプローチは、人生のアドバイスに魔法の8ボールに聞くのと同様に信頼できません。
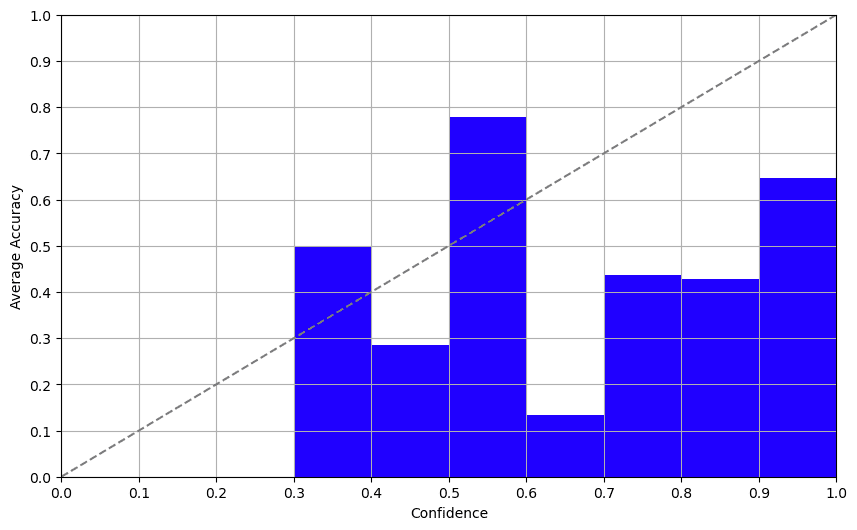
アプローチ3:対数確率
対数確率は驚くべき結果をもたらしました。Davinci-003は補完モードでトークンの対数確率を返します。この出力を調べると、驚くほどまともな信頼スコアが得られ、正確さとの相関も良好でした。この方法は信頼性のある信頼スコアの決定に有望なアプローチを提供します。
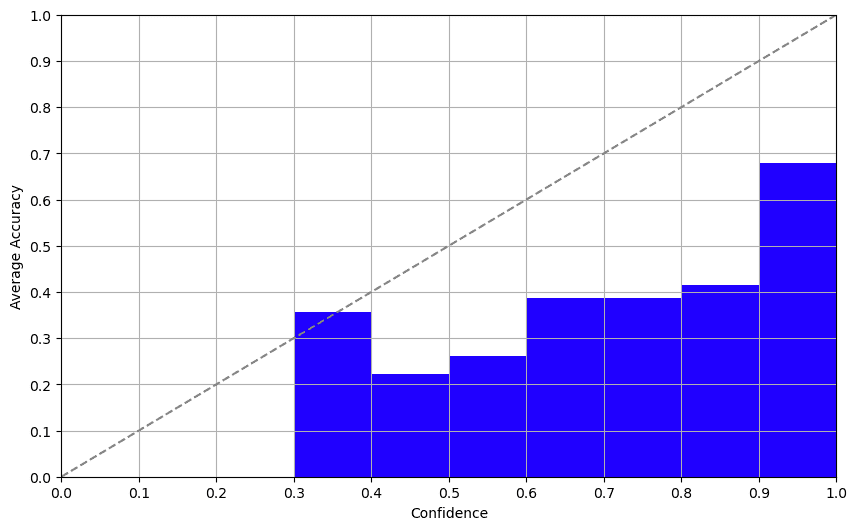
結論
では、何を学びましたか?砂糖で包み込むことなく、ここにあります:
- 自信:役立つが、注意が必要です。バイアスが広く報告されています。
- 一貫性:やめてください。カオスを楽しみたい場合を除いて。
- 対数確率:モデルがアクセス可能であれば、今のところ驚くほど良い賭けです。
興味深いのは、この論文によれば、モデルを微調整しなくても、対数確率はかなり強固であり、この方法は過信していると報告されているにもかかわらず、さらなる探査の余地があることです。
将来の展望
次の論理的なステップは、これらの3つのアプローチの最良の部分を組み合わせるか、新しいアプローチを探求するための黄金の公式を見つけることかもしれません。だから、チャレンジに挑戦したければ、これが次の週末プロジェクトになるかもしれません!
総括
はい、データラベル付けを行っているのか、次の大物の対話エージェントを構築しているのかに関わらず、モデルの信頼性を理解することは重要です。信頼度のスコアを顔の値として受け取らず、宿題をきちんと行いましょう!
この記事が有益であることを願っています。次回まで、数字を解析し、モデルに疑問を投げかけることを続けてください。 イワン・ヤムシチコフは、データセマンティクス処理と認知コンピューティングの教授であり、フュルツブルクWürzburg応用科学技術大学AIセンターのデータアドボケイツチームを率いています。彼の研究関心は、計算的な創造力、セマンティックデータ処理、生成モデルなどです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





