「MLOpsの考え方:常に本番準備完了」
MLOps Always ready for production
機械学習(ML)の成功は、さまざまなドメインでの成功をもたらしましたが、それに伴い、モデルの継続的なトレーニングと評価、トレーニングデータのドリフトの継続的なチェックの必要性という新たな一連の課題が生じました。継続的な統合とデプロイ(CI/CD)は、成功するソフトウェアエンジニアリングプロジェクトの中核であり、しばしばDevOpsと呼ばれます。DevOpsは、コードの進化を効率化し、さまざまなテストフレームワークを可能にし、開発サーバー(開発、ステージング、本番など)への選択的なデプロイを容易にします。
MLに関連する新たな課題は、従来のCI/CDの範囲を拡大し、Googleによって最初に紹介された「Continuous Training(CT)」という用語を含むようになりました。継続的なトレーニングでは、MLモデルを新しいデータセットで継続的にトレーニングし、本番環境への展開前に期待値を評価する必要があります。また、さまざまなML固有の機能を有効にする必要もあります。現在、機械学習のコンテキストでは、DevOpsはMLOpsとして知られるようになり、CI、CT、CDを含みます。
MLOpsの原則
すべての製品開発は特定の原則に基づいていますが、MLOpsも例外ではありません。以下は、最も重要なMLOpsの原則です。
- 継続的なX:MLOpsの焦点は進化にあるべきであり、継続的なトレーニング、継続的な開発、継続的な統合など、継続的に進化/変化するものであるべきです。
- すべてをトラック:MLの探索的な性質を考慮すると、科学実験のように起こることを追跡し、収集する必要があります。
- ジグソーパズルのアプローチ:どのMLOpsフレームワークもプラグイン可能なコンポーネントをサポートする必要があります。ただし、適切なバランスを取ることが重要です。プラグイン性が高すぎると互換性の問題が発生し、プラグイン性が低すぎると使用が制限されます。
これらの原則を念頭に置いて、優れたMLOpsフレームワークを制御するキーコンポーネントを特定しましょう。
MLOpsの要件
以前にも述べたように、機械学習はOpsに対して新たな要件をもたらしました。
- 再現性:MLの実験を繰り返して結果を確認できるようにするために、ML実験を再現できるようにする必要があります。
- バージョニング:データ、コード、モデル、構成など、すべての方向からバージョニングを維持する必要があります。データ-モデル-コードのバージョニングを行うには、GitHubのようなバージョン管理ツールを使用する方法があります。
- パイプライン:有向非循環グラフ(DAG)ベースのパイプラインは、非MLシナリオ(例:Airflow)でよく使用されますが、MLは継続的なトレーニングを可能にするため、独自のパイプライニング要件をもたらします。トレーニングと予測のためのパイプラインコンポーネントの再利用は、特徴抽出の一貫性を保ち、データ処理エラーを減らすことを保証します。
- オーケストレーションとデプロイ:MLモデルのトレーニングには、GPUを含む分散フレームワークのマシンの使用が必要であり、そのためクラウドでパイプラインを実行することはMLトレーニングサイクルの本質的な一部です。さまざまな条件(メトリック、環境など)に基づいてモデルを展開することは、機械学習において独自の課題をもたらします。
- 柔軟性:データソースの選択、クラウドプロバイダの選択、さまざまなツール(データ分析、モニタリング、MLフレームワークなど)の選択肢を提供することで、柔軟性を実現できます。柔軟性は、外部ツールへのプラグインオプションの提供やカスタムコンポーネントの定義能力の提供によって実現できます。柔軟なオーケストレーションとデプロイメントコンポーネントは、クラウドに依存しないパイプラインの実行とMLサービスを保証します。
- 実験の追跡:MLに固有のものとして、実験はプロジェクトの暗黙の一部です。複数の実験ラウンド(アーキテクチャやハイパーパラメータの実験など)の後、MLモデルは成熟します。将来の参照のために各実験のログを保持することは、MLにとって不可欠です。実験追跡ツールは、コードとモデルのバージョニングを確保し、DVCのようなツールはコードとデータのバージョニングを確保します。
実践的な考慮事項
MLモデルを作成する興奮の中で、初期データ分析やハイパーパラメータのチューニング、前処理/後処理など、特定のMLの衛生状態がしばしば見落とされます。多くの場合、プロジェクトの初めからMLの本番マインドセットが欠けているため、後の段階(メモリの問題、予算のオーバーフローなど)で驚きが生じ、特に本番時に再モデリングと市場参入の遅延を引き起こします。しかし、MLプロジェクトの開始時からMLOpsフレームワークを使用することで、生産に関する考慮事項が早期に解決され、データ分析、実験の追跡など、機械学習の問題を解決するための体系的なアプローチが強制されます。
MLOpsは、いつでも本番に対応可能にします。これは、市場投入までの時間を短縮する必要があるスタートアップにとって重要です。MLOpsは、オーケストレーションと展開において柔軟性を提供するため、MLOpsパイプラインの一部であるオーケストレータ(例:GitHubアクション)やデプロイヤー(例:MLflow、KServeなど)を事前に定義することで、本番準備が可能です。
MLOpsの既存のフレームワーク
Google、Amazon、Azureなどのクラウドサービスプロバイダは、独自のMLOpsフレームワークを提供しており、それらのプラットフォーム内または既存の機械学習フレームワーク(Tensorflowフレームワークの一部であるTFXパイプライニングなど)の一部として使用することができます。これらのMLOpsフレームワークは使用しやすく、機能が充実しています。
クラウドサービスプロバイダからのMLOpsフレームワークの使用は、組織が独自の環境でMLOpsを使用することを制限します。多くの組織にとって、クラウドサービスの使用は顧客の要望に依存するため、これは大きな制約となります。多くの場合、クラウドプロバイダを選択する柔軟性を提供し、同時にMLOpsのほとんどの機能を備えたMLOpsフレームワークが必要です。
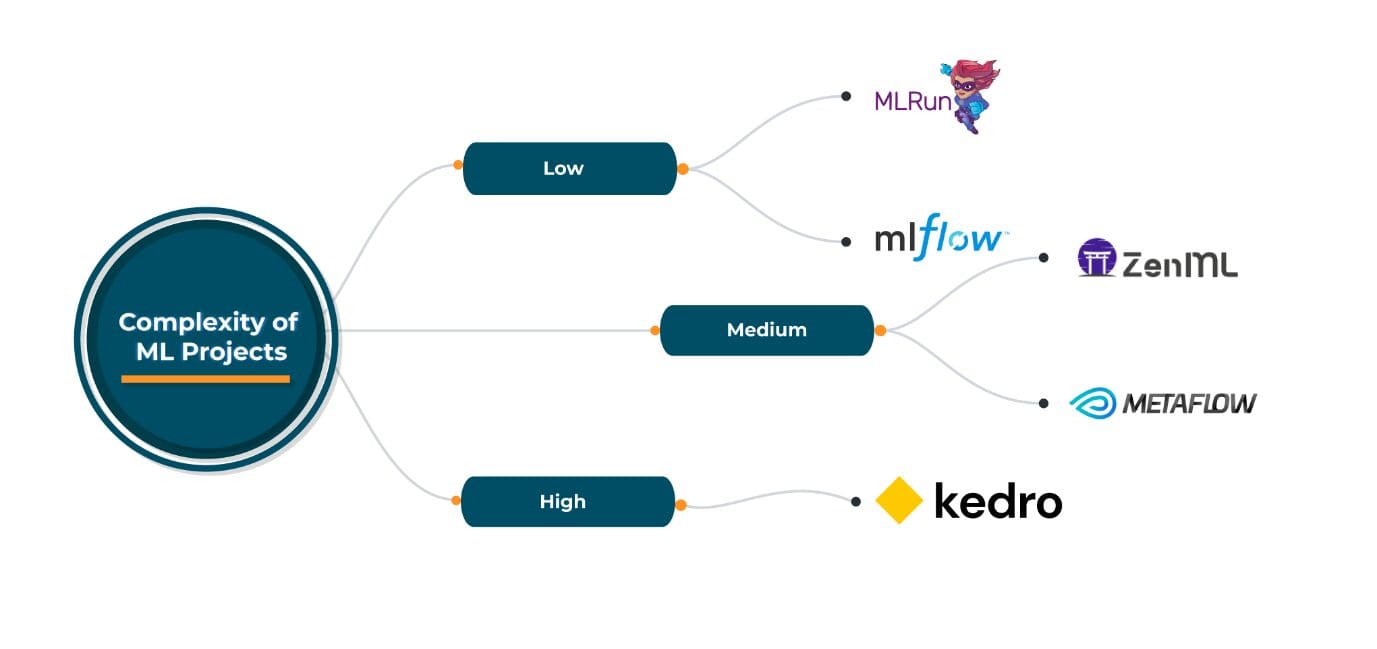
オープンソースのMLOpsフレームワークは、そのようなシナリオで役立ちます。ZenML、MLRun、Kedro、Metaflowなどは、それぞれ独自の利点と欠点を持つよく知られたオープンソースのMLOpsフレームワークであり、クラウドプロバイダ、オーケストレーション/デプロイメント、およびMLツールの選択において柔軟性を提供します。これらのオープンソースのフレームワークの選択は、具体的なMLOpsの要件に依存しますが、これらのフレームワークは幅広い要件に対応するため、一般的に使用することができます。
これらのオープンソースのMLOpsフレームワークの現在の状態での経験に基づいて、以下をお勧めします:
MLOpsを早期に採用する
MLOpsは、DevOpsの次の進化形であり、データエンジニア、機械学習エンジニア、インフラエンジニアなど、さまざまな領域の人々を結びつけています。将来的には、MLOpsがDevOpsと同様にローコード化されることが期待されます。特にスタートアップ企業は、市場投入までの時間を短縮するために、開発の早い段階でMLOpsを採用することが重要です。また、他の利点ももたらします。 Abhishek Guptaは、Talentica Softwareの主任データサイエンティストです。現在の役割では、AI/MLを使用して製品ラインアップの企業に協力しています。Abhishekは、AI/MLとビッグデータの領域で7年以上にわたって活動しており、通信ネットワークや機械学習などのさまざまな分野で特許や論文を持っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





